自用的截至2025.05.21相关服务器地址都是有效的,后续服务器地址改变可自己编辑代码
自行下载aria2c.exe所有脚本输出的下载链接文件都是符合aria2c的格式的
龙少女
import json
import requests
import os
version_url = "https://asset.lecisxqw.com/mgameasset/m3productionasset/Android/version.json"
output_path = "lsn.txt"
# 基础URL
base_url = "https://asset.lecisxqw.com/mgameasset/m3productionasset/Android/"
headers = {
"User-Agent": "UnityPlayer/2020.3.38f1 (UnityWebRequest/1.0, libcurl/7.80.0-DEV)",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "keep-alive",
}
# 获取version.json内容
try:
response = requests.get(version_url, headers=headers)
response.raise_for_status()
data = response.json()
except requests.exceptions.RequestException as e:
print(f"获取version.json失败: {e}")
exit(1)
asset_paths = data['assetBundleMetadatas'].keys()
download_entries = []
for path in asset_paths:
url = base_url + path
download_entry = f"{url}\n out=download/{path}"
download_entries.append(download_entry)
try:
with open(output_path, 'w', encoding='utf-8') as f:
f.write('\n'.join(download_entries))
print(f"已生成 {len(download_entries)} 个下载链接到 {output_path}")
os.system(f"aria2c -i {output_path} -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/龙少女")
except IOError as e:
print(f"写入文件失败: {e}")
梦娘
import requests
import json
import re
import os
'''
不知道什么情况E服好几个版本都是2.4不过2.4的资源确实有更新
试过2.5版本结果还更旧?(存疑)
'''
def get_bundle_path():
versioninfo = input("请输入版本(例如2.4):")
url = "https://api.mh-freya-game.com:8100/M1HGateway/gateway.php" # 改为 HTTPS
headers = {
"Host": "api.mh-freya-game.com:8100",
"User-Agent": "UnityPlayer/2020.3.38f1 (UnityWebRequest/1.0, libcurl/7.80.0-DEV)",
"Accept": "*/*",
"Accept-Encoding": "deflate, gzip",
"Content-Type": "application/x-www-form-urlencoded",
"X-Unity-Version": "2020.3.38f1",
}
data = f"Mode=ServerInfo&AppName=Freya&AppVersion={versioninfo}&Platform=android"
# 禁用 SSL 验证(仅测试用,生产环境应使用正确证书)
response = requests.post(url, headers=headers, data=data, verify=False)
if response.status_code != 200:
raise Exception(f"请求失败,状态码: {response.status_code}")
result = response.json()
bundle_path = result.get("bundlePath", "")
# 清理bundlePath中的转义字符和方括号
if bundle_path:
bundle_path = re.sub(r'[\\"\[\]]', '', bundle_path)
if bundle_path.endswith('/'):
bundle_path = bundle_path[:-1]
return bundle_path
def get_version_json(bundle_path):
version_url = f"{bundle_path}/Android/version.json"
response = requests.get(version_url)
if response.status_code != 200:
raise Exception(f"获取version.json失败,状态码: {response.status_code}")
return response.json()
def generate_download_urls(bundle_path, version_data):
urls = []
asset_bundles = version_data.get("assetBundleMetadatas", {})
for path in asset_bundles.keys():
download_url = f"{bundle_path}/Android/{path}"
# 构造aria2c兼容的输出格式
aria_line = f"{download_url}\n out={path}"
urls.append(aria_line)
return urls
def save_to_file(urls, filename="hj.txt"):
with open(filename, "w", encoding="utf-8") as f:
for url in urls:
f.write(url + "\n")
def main():
try:
bundle_path = get_bundle_path()
print(f"获取到的bundlePath: {bundle_path}")
version_data = get_version_json(bundle_path)
print("成功获取version.json数据")
download_urls = generate_download_urls(bundle_path, version_data)
print(f"共生成 {len(download_urls)} 个下载URL")
save_to_file(download_urls)
print("下载URL已保存到hj.txt")
os.system(f"aria2c -i hj.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/梦娘")
except Exception as e:
print(f"发生错误: {e}")
if __name__ == "__main__":
main()
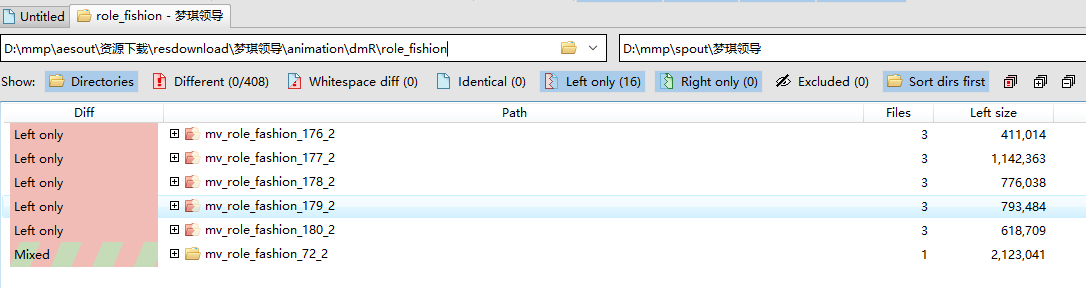
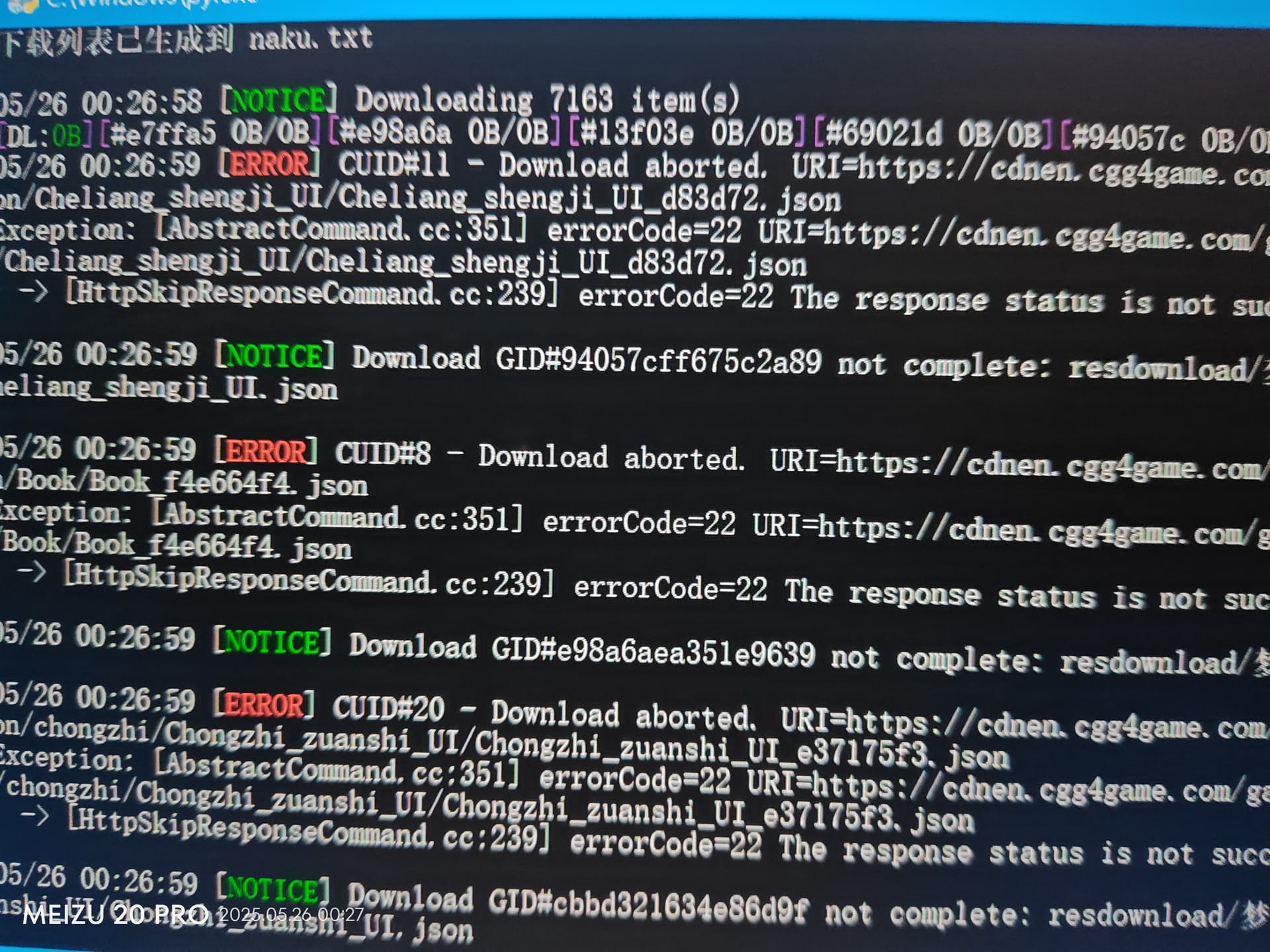
梦琪领导(非erolab游戏nutaku上的 President’s Ambition-Project Beauty-R在还原spine工程时候在一些json图片路径里找到的中文名字可能是外包?)
import json
import os
'''
这个游戏挺久没更新,这个脚本也是半成品也许有bug但是spine和live2d资源可以下载下来
'''
def generate_download_urls(json_file_path, output_file):
with open(json_file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
animation_data = data['files']['animation']
with open(output_file, 'w', encoding='utf-8') as f_out:
def process_node(node, current_path):
if isinstance(node, dict):
for key, value in node.items():
if '.' in key:
new_path = current_path
else:
new_path = f"{current_path}/{key}" if current_path else key
if isinstance(value, dict):
process_node(value, new_path)
elif isinstance(value, str):
# 这是文件节点
file_name = key
file_hash = value
generate_url_and_write(f_out, current_path, file_name, file_hash)
else:
print(f"警告: 未知数据类型 {type(value)} 在路径 {new_path}")
process_node(animation_data, "")
def generate_url_and_write(output_handle, item_path, file_name, file_hash):
# 确定文件扩展名
if file_name.endswith('.atlas'):
ext = '.atlas'
elif file_name.endswith('.json'):
ext = '.json'
else:
ext = '.png'
if '.' in file_name:
base_name = file_name.split('.')[0]
url = f"https://cdnen.cgg4game.com/games/richman2Release/resource/animation/{item_path}/{base_name}_{file_hash}{ext}"
else:
url = f"https://cdnen.cgg4game.com/games/richman2Release/resource/animation/{item_path}/{file_name}_{file_hash}{ext}"
# 构建输出路径
if '.' in file_name:
out_path = f"animation/{item_path}/{file_name}"
else:
out_path = f"animation/{item_path}/{file_name}{ext}"
output_handle.write(f"{url}\n out={out_path}\n")
# 使用示例
json_file_path = r"C:\Users\test\Downloads\default.res.2u6m4ad.json"
output_file = 'naku.txt'
generate_download_urls(json_file_path, output_file)
print(f"下载URL已导出到 {output_file}")
# 执行aria2c下载
if os.path.exists(output_file):
os.system("aria2c -i naku.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/梦琪领导")
else:
print("未能生成下载列表,请检查错误信息")
樱境物语
import json
import requests
import os
def generate_aria2_input(url, output_file='yj.txt'):
try:
response = requests.get(url)
response.raise_for_status()
data = json.loads(response.text)
base_url = url[:url.rfind('/') + 1] if '/' in url else url
with open(output_file, 'w', encoding='utf-8') as out_f:
for url_path, value in data.items():
if isinstance(value, list) and len(value) > 1:
hash_value = value[1]
full_url = f"{base_url}{url_path}.{hash_value}"
out_path = os.path.join('download', url_path)
out_f.write(f"{full_url}\n out={out_path}\n")
print(f"成功生成aria2输入文件: {output_file}")
print(f"共处理了 {len(data)} 个URL")
os.system("aria2c -i yj.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/樱境物语")
except requests.exceptions.RequestException as e:
print(f"下载失败: {str(e)}")
except json.JSONDecodeError:
print("错误: 下载的内容不是有效的JSON格式")
except Exception as e:
print(f"发生错误: {str(e)}")
import os
import argparse
import struct
from pathlib import Path
def process_file(input_file_path, output_file_path):
indicies = [0x3FB, 0xD99, 0x197C]
with open(input_file_path, "rb") as file:
bytes_data = bytearray(file.read())
for idx in indicies:
if idx < len(bytes_data):
ridx = len(bytes_data) - idx
bytes_data[idx], bytes_data[ridx] = bytes_data[ridx], bytes_data[idx]
originalVersion = b"2020.3.41f1\x00"
encryptedVersion = b"2018.3.5f1\x00"
index = 0
offset = 0
array = bytearray()
while index != -1:
index = bytes_data.find(encryptedVersion, offset)
if index == -1:
array.extend(bytes_data[offset:])
break
if index > 0:
array.extend(bytes_data[offset:index])
array.extend(originalVersion)
offset = len(encryptedVersion) + index
os.makedirs(os.path.dirname(output_file_path), exist_ok=True)
with open(output_file_path, "wb") as file:
print("Processed:", output_file_path)
file.write(array)
def process_folder(input_folder_path, output_folder_path):
input_path = Path(input_folder_path)
output_path = Path(output_folder_path)
for item in input_path.rglob('*'):
if item.is_file():
relative_path = item.relative_to(input_path)
output_file_path = output_path / relative_path
process_file(str(item), str(output_file_path))
if __name__ == "__main__":
#2025.04版更新index改为在线获取需要POST数据但是数据经过加密暂时没有什么可替代的方法可以抓包获取index文件后将url传入
index_url = input("index链接>")
generate_aria2_input(index_url)
#站内的解密脚本
process_folder("resdownload/樱境物语/download", "resdownload/樱境物语/decode")
潘吉亚异闻录
import requests
import json
from urllib.parse import urlparse
import os
def get_latest_android_build():
config_url = "https://hwpn.uquqp.com/ELB/prod/config.json"
try:
response = requests.get(config_url)
response.raise_for_status()
config_data = response.json()
android_versions = config_data["Releases"]["Android"]
def version_key(version_str):
# 这里有可能有bug版本号有些包含年份实在不行就手动设置一下
parts = []
for part in version_str.split('.'):
if len(part) > 4 and part.isdigit():
part = part[-6:]
parts.append(int(part))
return parts
latest_version = max(android_versions.keys(), key=version_key)
build_number = android_versions[latest_version]
print(f"Latest Android version: {latest_version}, build number: {build_number}")
return build_number
except Exception as e:
print(f"Error fetching config.json: {e}")
return None
def get_resource_links(build_number):
catalog_url = f"https://hwpn.uquqp.com/ELB/prod/Android/{build_number}/catalog_Remote.json"
print(catalog_url)
try:
response = requests.get(catalog_url)
response.raise_for_status()
catalog_data = response.json()
base_url = f"https://hwpn.uquqp.com/ELB/prod/Android/{build_number}"
resource_links = []
for url in catalog_data.get("m_InternalIds", []):
if isinstance(url, str) and "{RiverGames.AddressableRumtimeSetting.MainUrl}" in url:
placeholder = "{RiverGames.AddressableRumtimeSetting.MainUrl}"
if placeholder not in url:
placeholder = "{RiverGames.AddressableRumtimeSetting.MainUrl}"
# 构建完整URL
full_url = url.replace(placeholder, base_url)
file_name = url.split("/")[-1]
resource_links.append((full_url, file_name))
return resource_links
except Exception as e:
print(f"Error fetching catalog_Remote.json: {e}")
return None
def generate_aria2c_download_list(resource_links, output_file="pjyy.txt"):
try:
with open(output_file, "w", encoding="utf-8") as f:
for url, out_path in resource_links:
f.write(f"{url}\n out={out_path}\n")
print(f"Successfully generated aria2c download list with {len(resource_links)} entries in {output_file}")
os.system(f"aria2c -i {output_file} -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/潘吉亚异闻录")
except Exception as e:
print(f"Error writing to {output_file}: {e}")
def main():
build_number = get_latest_android_build()
if not build_number:
return
resource_links = get_resource_links(build_number)
if not resource_links:
return
generate_aria2c_download_list(resource_links)
if __name__ == "__main__":
main()
贤者同盟
import requests
import json
import os
def get_filelist_and_generate_urls():
# 请求文件列表
url = "https://msdq.tuanziwo.com/ob/update/android/filelist"
try:
response = requests.get(url)
response.raise_for_status() # 检查请求是否成功
filelist = response.json()
# 生成下载链接并写入文件
with open("xztm.txt", "w", encoding="utf-8") as f:
for item in filelist:
filename = item["filename"]
download_url = f"https://msdq.tuanziwo.com/ob/update/android/{filename}"
f.write(f"{download_url}\n out={filename}\n")
print("下载链接已成功导出到xztm.txt")
os.system(f"aria2c -i xztm.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/贤者同盟")
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
except json.JSONDecodeError:
print("解析JSON数据失败")
if __name__ == "__main__":
get_filelist_and_generate_urls()
天下布魔
import json
import os
import re
import requests
def fetch_json(url):
try:
response = requests.get(url)
response.raise_for_status()
return response.json()
except requests.RequestException as e:
print(f"Error fetching {url}: {str(e)}")
raise
def process_json_file(data):
http_links = []
for item in data.get('m_InternalIds', []):
if isinstance(item, str) and item.startswith('http://file.sg-arts.com'):
http_links.append(item)
cdn_info = fetch_json("https://cdn-aussetzen-tkfm.pinkcore.net/")
cdn_domain = cdn_info['cdn_domain']
version_info = fetch_json(f"{cdn_domain}/version/tkfm-version-1101.json")
latest_build_number = version_info['latest_build_number']
config_info = fetch_json(f"{cdn_domain}/config/tkfm-config-1101-{latest_build_number}.json")
asset_url = config_info['asset_url']
new_prefix = f"{cdn_domain}/{asset_url}"
old_prefix = 'http://file.sg-arts.com/bundle/tkfm/development'
processed_links = []
for link in http_links:
new_link = link.replace(old_prefix, new_prefix)
relative_path = link[len(old_prefix):]
output = {
'url': new_link,
'out': f'download{relative_path}'
}
processed_links.append(output)
# 写入到txbm.txt文件
with open('txbm.txt', 'w', encoding='utf-8') as out_file:
for item in processed_links:
out_file.write(f"{item['url']}\n out={item['out']}\n")
print(f"已处理并保存{len(processed_links)}个链接到txbm.txt")
os.system("aria2c -i txbm.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/天下布魔")
def main():
try:
cdn_info = fetch_json("https://cdn-aussetzen-tkfm.pinkcore.net/")
cdn_domain = cdn_info['cdn_domain']
version_info = fetch_json(f"{cdn_domain}/version/tkfm-version-1101.json")
latest_build_number = version_info['latest_build_number']
config_info = fetch_json(f"{cdn_domain}/config/tkfm-config-1101-{latest_build_number}.json")
asset_url = config_info['asset_url']
catalog_name = config_info['catalog_name']
catalog_url = f"{cdn_domain}/{asset_url}/Android/{catalog_name}.json"
catalog_data = fetch_json(catalog_url)
process_json_file(catalog_data)
except Exception as e:
print(f"发生错误: {str(e)}")
if __name__ == "__main__":
main()
星欲少女
import json
import os
import requests
from urllib.parse import urlparse
def get_cdn_domain():
url = "https://cdn-aussetzen-ls.pinkcore.net/"
headers = {
"x-channel": "EROLABS",
"accept-encoding": "br, gzip, identity",
"user-agent": "BestHTTP/2 v2.8.2",
"content-length": "0"
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
data = response.json()
return data["cdn_domain"]
except requests.exceptions.RequestException as e:
print(f"获取CDN域名失败: {e}")
return None
def get_asset_version(cdn_domain, version):
config_url = f"{cdn_domain}/ClientConfig/prod_config_v{version}.json"
try:
response = requests.get(config_url)
response.raise_for_status()
config_data = response.json()
return config_data["AssetVersion"]
except requests.exceptions.RequestException as e:
print(f"获取AssetVersion失败: {e}")
return None
except KeyError:
print("配置文件中找不到AssetVersion字段")
return None
def process_json_file(json_path, cdn_domain, asset_version):
try:
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
except Exception as e:
print(f"读取JSON文件失败: {e}")
return
resources = []
for item in data.get("m_InternalIds", []):
if "{LSGlobalConfig.AssetLoadPath}" in item:
# 提取资源相对路径
resource_path = item.replace("{LSGlobalConfig.AssetLoadPath}/", "")
# 构建完整URL
resource_url = f"{cdn_domain}/Erolabs/Android/prod/{asset_version}/{resource_path}"
resources.append(resource_url)
if not resources:
print("没有找到有效的资源链接")
return
# 创建下载目录
download_dir = os.path.join("resdownload", "星欲少女")
os.makedirs(download_dir, exist_ok=True)
# 写入aria2c输入文件
input_file = os.path.join(download_dir, "download_list.txt")
with open(input_file, 'w', encoding='utf-8') as f:
for url in resources:
parsed = urlparse(url)
relative_path = parsed.path.lstrip('/')
# 移除版本号前的路径,保持原始资源路径结构
resource_relative_path = '/'.join(relative_path.split('/')[4:])
f.write(f"{url}\n out={resource_relative_path}\n")
print(f"已找到 {len(resources)} 个资源链接并保存到 {input_file}")
# 执行aria2c下载
aria2c_cmd = (
f"aria2c -i {input_file} -j 32 -s 16 -x 16 "
f"--check-certificate=false --dir={download_dir} "
"--auto-file-renaming=false --allow-overwrite=true"
)
print(f"执行下载命令: {aria2c_cmd}")
os.system(aria2c_cmd)
def main():
cdn_domain = get_cdn_domain()
if not cdn_domain:
print("无法获取CDN域名,程序退出")
return
print(f"获取到的CDN域名: {cdn_domain}")
version = input("请输入版本号(例如1.19.0): ").strip()
asset_version = get_asset_version(cdn_domain, version)
if not asset_version:
print("无法获取AssetVersion,程序退出")
return
print(f"获取到的AssetVersion: {asset_version}")
while True:
json_path = input("请输入JSON文件路径(\\assets\\aa\\catalog.json): ").strip()
if json_path.lower() == 'q':
break
if not os.path.isfile(json_path):
print("文件不存在,请重新输入")
continue
process_json_file(json_path, cdn_domain, asset_version)
break
if __name__ == "__main__":
main()
print("图片走Normal模式")
星陨计划
import requests
import json
import os
from urllib.parse import urlparse
def get_path_domain():
url = "https://game-arkre-labs.ecchi.xxx/Router/RouterHandler.ashx"
headers = {
"Host": "game-arkre-labs.ecchi.xxx",
"User-Agent": "UnityPlayer/2022.3.28f1 (UnityWebRequest/1.0, libcurl/8.5.0-DEV)",
"Accept": "*/*",
"Accept-Encoding": "deflate, gzip",
"Content-Type": "application/octet-stream",
"X-Unity-Version": "2022.3.28f1"
}
data = {
"data": {},
"route": "GameServerDBSettingHandler.QueryBulletinInfoResult"
}
response = requests.put(url, headers=headers, json=data)
if response.status_code == 200:
result = response.json()
return result["Info"]["PathDomain"]
else:
print(f"请求失败,状态码: {response.status_code}")
return None
def get_relative_path(url, base_domain):
parsed_url = urlparse(url)
base_parsed = urlparse(base_domain)
if parsed_url.netloc != base_parsed.netloc:
return None
relative_path = parsed_url.path.lstrip('/')
return relative_path
def process_json_file(file_path, path_domain):
try:
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
resource_entries = []
if "m_InternalIds" in data:
for item in data["m_InternalIds"]:
if isinstance(item, str) and "http://PatchDomain" in item:
full_url = item.replace("http://PatchDomain", path_domain)
relative_path = get_relative_path(full_url, path_domain)
if relative_path:
resource_entries.append((full_url, relative_path))
return resource_entries
except Exception as e:
print(f"处理JSON文件时出错: {e}")
return None
def main():
path_domain = get_path_domain()
if not path_domain:
print("无法获取PathDomain,程序退出")
return
print(f"获取到的PathDomain: {path_domain}")
json_file_path = input(r"请输入JSON文件路径(\assets\aa): ").strip('"')
if not os.path.exists(json_file_path):
print("文件不存在,请检查路径")
return
resource_entries = process_json_file(json_file_path, path_domain)
if not resource_entries:
print("没有找到包含PatchDomain的资源链接")
return
output_file = "xyjh.txt"
with open(output_file, 'w', encoding='utf-8') as file:
for url, rel_path in resource_entries:
file.write(f"{url}\n\tout={rel_path}\n")
print(f"已成功将{len(resource_entries)}个资源链接写入到{output_file}")
os.system(f"aria2c -i {output_file} -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/星陨计划")
if __name__ == "__main__":
main()
异种啪乐町
import requests
import json
import os
headers = {
"User-Agent": "UnityPlayer/6000.0.40f1 (UnityWebRequest/1.0, libcurl/8.10.1-DEV)"
}
version_url = "https://drgame-patch.gsvfn.com/Config/Prod/version.json"
try:
response = requests.get(version_url, headers=headers)
response.raise_for_status()
version_data = response.json()
res_value = None
for pair in version_data["Contents"]["Pairs"]:
if pair["Key"] == "Res":
res_value = pair["Value"]
break
print(f"Res的值是: {res_value}")
bundle_index_url = f"https://drgame-patch.gsvfn.com/Bundle/Android/{res_value}/BundleIndexFile.txt"
response = requests.get(bundle_index_url, headers=headers)
print(f"BundleIndexFile 响应状态码: {response.status_code}")
if response.status_code == 200 and response.text.strip():
bundle_lines = response.text.splitlines()
download_links = []
for line in bundle_lines:
if line.strip() and not line.startswith("localization"):
parts = line.split(",")
if len(parts) == 2:
filename, file_version = parts
download_url = f"https://drgame-patch.gsvfn.com/Bundle/Android/{file_version}/{filename}"
download_links.append(download_url)
with open("yzpltdownload.txt", "w", encoding="utf-8") as f:
for link in download_links:
f.write(link + "\n")
print(f"\n已生成 {len(download_links)} 个下载链接并保存到 yzpltdownload.txt")
os.system("aria2c -i yzpltdownload.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/异种啪乐町")
else:
print("\n错误: 未能获取有效的BundleIndexFile内容")
except requests.exceptions.RequestException as e:
print(f"\n请求发生错误: {e}")
except json.JSONDecodeError as e:
print(f"\nJSON解析错误: {e}")
except Exception as e:
print(f"\n发生未知错误: {e}")
潘吉亚异闻录nutaku (落后于E服但是是大雷服部分资源不一样命名后有_NTK字样)
import requests
import json
from urllib.parse import urlparse
import os
def get_latest_android_build():
config_url = "https://evnk.uquqp.com/NTK/prod/config.json"
try:
response = requests.get(config_url)
response.raise_for_status()
config_data = response.json()
android_versions = config_data["Releases"]["Android"]
def version_key(version_str):
# 这里有可能有bug版本号有些包含年份实在不行就手动设置一下
parts = []
for part in version_str.split('.'):
if len(part) > 4 and part.isdigit():
part = part[-6:]
parts.append(int(part))
return parts
latest_version = max(android_versions.keys(), key=version_key)
build_number = android_versions[latest_version]
print(f"Latest Android version: {latest_version}, build number: {build_number}")
return build_number
except Exception as e:
print(f"Error fetching config.json: {e}")
return None
def get_resource_links(build_number):
catalog_url = f"https://evnk.uquqp.com/NTK/prod/Android/{build_number}/catalog_Remote.json"
print(catalog_url)
try:
response = requests.get(catalog_url)
response.raise_for_status()
catalog_data = response.json()
base_url = f"https://evnk.uquqp.com/NTK/prod/Android/{build_number}"
resource_links = []
for url in catalog_data.get("m_InternalIds", []):
if isinstance(url, str) and "{RiverGames.AddressableRumtimeSetting.MainUrl}" in url:
placeholder = "{RiverGames.AddressableRumtimeSetting.MainUrl}"
if placeholder not in url:
placeholder = "{RiverGames.AddressableRumtimeSetting.MainUrl}"
# 构建完整URL
full_url = url.replace(placeholder, base_url)
file_name = url.split("/")[-1]
resource_links.append((full_url, file_name))
return resource_links
except Exception as e:
print(f"Error fetching catalog_Remote.json: {e}")
return None
def generate_aria2c_download_list(resource_links, output_file="pjyyntk.txt"):
try:
with open(output_file, "w", encoding="utf-8") as f:
for url, out_path in resource_links:
f.write(f"{url}\n out={out_path}\n")
print(f"Successfully generated aria2c download list with {len(resource_links)} entries in {output_file}")
os.system(f"aria2c -i {output_file} -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/潘吉亚异闻录NTK")
except Exception as e:
print(f"Error writing to {output_file}: {e}")
def main():
build_number = get_latest_android_build()
if not build_number:
return
resource_links = get_resource_links(build_number)
if not resource_links:
return
generate_aria2c_download_list(resource_links)
if __name__ == "__main__":
main()