aria2支持使用代理服务器,如果你使用例如ssr 2ray此类代理可以在本地建立代理服务器,或者使用TUN模式
墮落姬甲
这游戏应该在2025.05.27关闭服务器
需要手动设置unity版本为 2019.4.36f1
import requests
import json
import os
from urllib.parse import urljoin
def get_json(url):
response = requests.get(url)
response.raise_for_status()
return response.json()
def process_files(cdn_domain, res_min, file_paths, output_file):
base_url = f"{cdn_domain}/Bundle/Android/{res_min}/"
with open(output_file, 'w', encoding='utf-8') as f:
for path in file_paths:
if path.startswith("0#/"):
filename = path[3:]
file_url = urljoin(base_url, filename)
rel_path = os.path.join("Bundle", "Android", res_min, filename)
rel_path = rel_path.replace('\\', '/')
f.write(f"{file_url}\n out={rel_path}\n")
def main():
cdn_info_url = "https://cdn-aussetzen-ms.pinkcore.net/"
cdn_info = get_json(cdn_info_url)
cdn_domain = cdn_info["cdn_domain"]
print(f"CDN Domain: {cdn_domain}")
version_url = f"{cdn_domain}/Config/Prod/version.json"
version_info = get_json(version_url)
res_min = None
for pair in version_info["Contents"]["Pairs"]:
if pair["Key"] == "Res_Min":
res_min = pair["Value"]
break
if not res_min:
raise ValueError("Res_Min not found in version.json")
print(f"Res_Min: {res_min}")
catalog_url = f"{cdn_domain}/Bundle/Android/{res_min}/catalog_release.json"
catalog_info = get_json(catalog_url)
file_paths = [path for path in catalog_info["m_InternalIds"] if path.startswith("0#/")]
print(f"Found {len(file_paths)} bundle files")
output_file = "jj.txt"
process_files(cdn_domain, res_min, file_paths, output_file)
print(f"Results written to {output_file}")
os.system("aria2c -i jj.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/墮落姬甲")
if __name__ == "__main__":
main()
3 个赞
大佬,请问可以出一个极乐夜王和星神少女的吗,非常感谢,这两个游戏的资源包都是无法在游戏内一键下载而是要获取资源后才能获得的,非常感谢!
星神有鉴权
难受了兄弟
感謝大佬 話說
dmm的総裁の野望 -美女養成計画- R = 大佬的梦琪领导
而且DMM的應該比較早上市 提供這邊參考
樱境物语 自动获取index.txt版
额朋友说更新了抓包的时候研究了一下这个index的请求
尝试笨办法修改hex格式的版本号试试。。。目前1.6.0版本获取没问题
站内解密脚本似乎在unity版本后面多了一个0字节?移除后可以正常解包
import json
import requests
import os
import re
from pathlib import Path
def generate_aria2_input(url, output_file='yj.txt'):
try:
response = requests.get(url)
response.raise_for_status()
data = json.loads(response.text)
base_url = url[:url.rfind('/') + 1] if '/' in url else url
with open(output_file, 'w', encoding='utf-8') as out_f:
for url_path, value in data.items():
if isinstance(value, list) and len(value) > 1:
hash_value = value[1]
full_url = f"{base_url}{url_path}.{hash_value}"
out_path = os.path.join('download', url_path)
out_f.write(f"{full_url}\n out={out_path}\n")
print(f"成功生成aria2输入文件: {output_file}")
print(f"共处理了 {len(data)} 个URL")
os.system("aria2c -i yj.txt -j 32 -s 16 -x 16 --check-certificate=false --max-tries=100 --retry-wait=60 --dir=resdownload/樱境物语")
except requests.exceptions.RequestException as e:
print(f"下载失败: {str(e)}")
except json.JSONDecodeError:
print("错误: 下载的内容不是有效的JSON格式")
except Exception as e:
print(f"发生错误: {str(e)}")
def process_file(input_file_path, output_file_path):
indicies = [0x3FB, 0xD99, 0x197C]
with open(input_file_path, "rb") as file:
bytes_data = bytearray(file.read())
for idx in indicies:
if idx < len(bytes_data):
ridx = len(bytes_data) - idx
bytes_data[idx], bytes_data[ridx] = bytes_data[ridx], bytes_data[idx]
originalVersion = b"2020.3.41f1"
encryptedVersion = b"2018.3.5f1\x00"
index = 0
offset = 0
array = bytearray()
while index != -1:
index = bytes_data.find(encryptedVersion, offset)
if index == -1:
array.extend(bytes_data[offset:])
break
if index > 0:
array.extend(bytes_data[offset:index])
array.extend(originalVersion)
offset = len(encryptedVersion) + index
os.makedirs(os.path.dirname(output_file_path), exist_ok=True)
with open(output_file_path, "wb") as file:
print("Processed:", output_file_path)
file.write(array)
def process_folder(input_folder_path, output_folder_path):
input_path = Path(input_folder_path)
output_path = Path(output_folder_path)
for item in input_path.rglob('*'):
if item.is_file():
relative_path = item.relative_to(input_path)
output_file_path = output_path / relative_path
process_file(str(item), str(output_file_path))
def version_to_hex(version_str):
return version_str.encode('utf-8').hex()
def build_hex_payload(version_hex):
base_payload_hex = (
"08 C7 85 06 1A 02 2D 31 50 FF FF FF FF FF FF FF FF FF 01 60 BC 90 98 AA F1 32 72 20 37 30 46 30 46 35 33 35 41 36 43 46 45 35 43 36 43 36 41 43 34 34 46 31 30 36 38 37 34 43 34 33 BA AC 30 17 08 02 12 0D"
)
# 替换版本部分
full_payload_hex = f"{base_payload_hex} {version_hex} 2D 65 6C 2D 68 2D 61 6E 1A 04 7A 68 63 6E"
return full_payload_hex.replace(" ", "")
if __name__ == "__main__":
user_version = input("请输入版本号(例如 1.6.0 直接回车手动提供index url):")
if user_version != "":
version_hex = version_to_hex(user_version)
payload_hex = build_hex_payload(version_hex)
payload_bytes = bytes.fromhex(payload_hex)
url = "https://game-ct-labs.ecchi.xxx:1893/"
headers = {
"Host": "game-ct-labs.ecchi.xxx:1893",
"User-Agent": "UnityPlayer/2020.3.41f1 (UnityWebRequest/1.0, libcurl/7.84.0-DEV)",
"Accept": "*/*",
"Accept-Encoding": "deflate, gzip",
"Content-Type": "application/octet-stream",
"X-Unity-Version": "2020.3.41f1"
}
response = requests.post(url, headers=headers, data=payload_bytes)
print(f"Status Code: {response.status_code}")
match = re.search(r'(?<=\:\s)[a-fA-F0-9]{32}', response.text)
if match:
indexhash = match.group()
index_url = f'https://hefc.hrbzqy.com/patch/files/index.txt.{indexhash}'
print(f'Try {index_url}')
else:
index_url = input("index链接>")
else:
#2025.04版更新index改为在线获取需要POST数据但是数据经过加密暂时没有什么可替代的方法可以抓包获取index文件后将url传入
index_url = input("index链接>")
generate_aria2_input(index_url)
#站内的解密脚本
process_folder("resdownload/樱境物语/download", "resdownload/樱境物语/decode")
我这个版本是nutaku 的dmm因为ip问题反正懒得搞了
也不敢连着学校VPN(日本ip)搞 ![]()
1 个赞
赶着版本更新再研究了一下他的热更包获取修改为在线获取json无需下载apk
import requests
import json
import os
from urllib.parse import urlparse
def get_path_domain():
url = "https://game-arkre-labs.ecchi.xxx/Router/RouterHandler.ashx"
headers = {
"Host": "game-arkre-labs.ecchi.xxx",
"User-Agent": "UnityPlayer/2022.3.28f1 (UnityWebRequest/1.0, libcurl/8.5.0-DEV)",
"Accept": "*/*",
"Accept-Encoding": "deflate, gzip",
"Content-Type": "application/octet-stream",
"X-Unity-Version": "2022.3.28f1"
}
data = {
"data": {},
"route": "GameServerDBSettingHandler.QueryBulletinInfoResult"
}
response = requests.put(url, headers=headers, json=data)
if response.status_code == 200:
result = response.json()
return result["Info"]["PathDomain"],result["Info"]["NewCatalogName"]
else:
print(f"请求失败,状态码: {response.status_code}")
return None
def get_relative_path(url, base_domain):
parsed_url = urlparse(url)
base_parsed = urlparse(base_domain)
if parsed_url.netloc != base_parsed.netloc:
return None
relative_path = parsed_url.path.lstrip('/')
return relative_path
def process_json_file(file_path, path_domain):
try:
with open(file_path, 'r', encoding='utf-8') as file:
data = json.load(file)
resource_entries = []
if "m_InternalIds" in data:
for item in data["m_InternalIds"]:
if isinstance(item, str) and "http://PatchDomain" in item:
full_url = item.replace("http://PatchDomain", path_domain)
relative_path = get_relative_path(full_url, path_domain)
if relative_path:
resource_entries.append((full_url, relative_path))
return resource_entries
except Exception as e:
print(f"处理JSON文件时出错: {e}")
return None
def process_json_url(url, path_domain):
try:
response = requests.get(url)
response.raise_for_status()
data = response.json()
resource_entries = []
if "m_InternalIds" in data:
for item in data["m_InternalIds"]:
if isinstance(item, str) and "http://PatchDomain" in item:
full_url = item.replace("http://PatchDomain", path_domain)
relative_path = get_relative_path(full_url, path_domain)
if relative_path:
resource_entries.append((full_url, relative_path))
return resource_entries
except Exception as e:
print(f"处理JSON URL时出错: {e}")
return None
def main():
path_domain,NewCatalogName = get_path_domain()
if not path_domain:
print("无法获取PathDomain,程序退出")
return
print(f"获取到的PathDomain: {path_domain}")
if not NewCatalogName:
json_file_path = input(r"请输入JSON文件路径(\assets\aa): ").strip('"')
if not os.path.exists(json_file_path):
print("文件不存在,请检查路径")
return
resource_entries = process_json_file(json_file_path, path_domain)
else:
resource_entries = process_json_url(f'{path_domain}/Android/{NewCatalogName}.json', path_domain)
if not resource_entries:
print("没有找到包含PatchDomain的资源链接")
return
output_file = "xyjh.txt"
with open(output_file, 'w', encoding='utf-8') as file:
for url, rel_path in resource_entries:
file.write(f"{url}\n\tout={rel_path}\n")
print(f"已成功将{len(resource_entries)}个资源链接写入到{output_file}")
os.system(f"aria2c -i {output_file} -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/星陨计划")
if __name__ == "__main__":
main()
1 个赞
梦琪领导 / 总统的野望 / 首富2
在线获取资源json版
dmm版
import json
import os
import re
import requests
'''
这个游戏挺久没更新,这个脚本也是半成品也许有bug但是spine和live2d资源可以下载下来
'''
def generate_download_urls(json_url, output_file):
# 从URL获取JSON数据
response = requests.get(json_url)
response.raise_for_status() # 如果请求失败会抛出异常
data = response.json()
animation_data = data['files']['animation']
with open(output_file, 'w', encoding='utf-8') as f_out:
def process_node(node, current_path):
if isinstance(node, dict):
for key, value in node.items():
if '.' in key and not re.search(r'\.\d{4}$', key):
new_path = current_path
else:
new_path = f"{current_path}/{key}" if current_path else key
if isinstance(value, dict):
process_node(value, new_path)
elif isinstance(value, str):
# 这是文件节点
file_name = key
file_hash = value
generate_url_and_write(f_out, current_path, file_name, file_hash)
else:
print(f"警告: 未知数据类型 {type(value)} 在路径 {new_path}")
process_node(animation_data, "")
def generate_url_and_write(output_handle, item_path, file_name, file_hash):
# 确定文件扩展名
if file_name.endswith('.atlas'):
ext = '.atlas'
elif file_name.endswith('.moc3'):
ext = '.moc3'
elif file_name.endswith('.json'):
ext = '.json'
else:
ext = '.png'
if '.' in file_name:
base_name = '.'.join(file_name.split('.')[:-1])
url = f"https://h.cgg4game.com/games/richman2Release/resource/animation/{item_path}/{base_name}_{file_hash}{ext}"
else:
url = f"https://h.cgg4game.com/games/richman2Release/resource/animation/{item_path}/{file_name}_{file_hash}{ext}"
# 构建输出路径
if '.' in file_name:
out_path = f"animation/{item_path}/{file_name}"
else:
out_path = f"animation/{item_path}/{file_name}{ext}"
output_handle.write(f"{url}\n out={out_path}\n")
import socket
import ssl
from urllib.parse import urlparse, parse_qs
host = "city2dmm.cgg4game.com"
port = 443
path = "/webdmm/h5Index_dmmPC.php"
request = f"GET {path} HTTP/1.1\r\n"
request += f"Host: {host}\r\n"
request += "Connection: keep-alive\r\n"
request += 'sec-ch-ua: "Chromium";v="136", "Microsoft Edge";v="136", "Not.A/Brand";v="99"\r\n'
request += "sec-ch-ua-mobile: ?0\r\n"
request += 'sec-ch-ua-platform: "Windows"\r\n'
request += "Upgrade-Insecure-Requests: 1\r\n"
request += "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0\r\n"
request += "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7\r\n"
request += "Sec-Fetch-Site: same-site\r\n"
request += "Sec-Fetch-Mode: navigate\r\n"
request += "Sec-Fetch-Dest: iframe\r\n"
request += "Sec-Fetch-Storage-Access: active\r\n"
request += "Referer: https://h.cgg4game.com/\r\n"
request += "Accept-Encoding: gzip, deflate, br, zstd\r\n"
request += "Accept-Language: zh-CN,zh;q=0.9\r\n"
request += "\r\n"
context = ssl.create_default_context()
with socket.create_connection((host, port)) as sock:
with context.wrap_socket(sock, server_hostname=host) as ssock:
ssock.sendall(request.encode())
response = b""
while True:
chunk = ssock.recv(4096)
if not chunk:
break
response += chunk
response_text = response.decode()
location_header = None
for line in response_text.split("\r\n"):
if line.lower().startswith("location:"):
location_header = line.split(":", 1)[1].strip()
break
if location_header:
parsed_url = urlparse(location_header)
query_params = parse_qs(parsed_url.query)
resVer = query_params.get("resVer", [None])[0]
print("resVer:", resVer)
output_file = 'ztdyw.txt'
generate_download_urls(f'https://h.cgg4game.com/games/richman2Release/resource/default.res.{resVer}.json', output_file)
print(f"下载URL已导出到 {output_file}")
if os.path.exists(output_file):
os.system("aria2c -i ztdyw.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/总统的野望")
else:
print("未能生成下载列表,请检查错误信息")
else:
print("No Location header found")
nutaku版
import json
import os
import re
import requests
'''
这个游戏挺久没更新,这个脚本也是半成品也许有bug但是spine和live2d资源可以下载下来
'''
def generate_download_urls(json_url, output_file):
# 从URL获取JSON数据
response = requests.get(json_url)
response.raise_for_status() # 如果请求失败会抛出异常
data = response.json()
animation_data = data['files']['animation']
with open(output_file, 'w', encoding='utf-8') as f_out:
def process_node(node, current_path):
if isinstance(node, dict):
for key, value in node.items():
if '.' in key and not re.search(r'\.\d{4}$', key):
new_path = current_path
else:
new_path = f"{current_path}/{key}" if current_path else key
if isinstance(value, dict):
process_node(value, new_path)
elif isinstance(value, str):
# 这是文件节点
file_name = key
file_hash = value
generate_url_and_write(f_out, current_path, file_name, file_hash)
else:
print(f"警告: 未知数据类型 {type(value)} 在路径 {new_path}")
process_node(animation_data, "")
def generate_url_and_write(output_handle, item_path, file_name, file_hash):
# 确定文件扩展名
if file_name.endswith('.atlas'):
ext = '.atlas'
elif file_name.endswith('.moc3'):
ext = '.moc3'
elif file_name.endswith('.json'):
ext = '.json'
else:
ext = '.png'
if '.' in file_name:
base_name = '.'.join(file_name.split('.')[:-1])
url = f"https://cdnen.cgg4game.com/games/richman2Release/resource/animation/{item_path}/{base_name}_{file_hash}{ext}"
else:
url = f"https://cdnen.cgg4game.com/games/richman2Release/resource/animation/{item_path}/{file_name}_{file_hash}{ext}"
# 构建输出路径
if '.' in file_name:
out_path = f"animation/{item_path}/{file_name}"
else:
out_path = f"animation/{item_path}/{file_name}{ext}"
output_handle.write(f"{url}\n out={out_path}\n")
import socket
import ssl
from urllib.parse import urlparse, parse_qs
host = "city2ntk.cgg4game.com"
port = 443
path = "/webfyen/nutakupc.php"
request = f"GET {path} HTTP/1.1\r\n"
request += f"Host: {host}\r\n"
request += "Connection: keep-alive\r\n"
request += 'sec-ch-ua: "Chromium";v="136", "Microsoft Edge";v="136", "Not.A/Brand";v="99"\r\n'
request += "sec-ch-ua-mobile: ?0\r\n"
request += 'sec-ch-ua-platform: "Windows"\r\n'
request += "Upgrade-Insecure-Requests: 1\r\n"
request += "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0\r\n"
request += "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7\r\n"
request += "Sec-Fetch-Site: same-site\r\n"
request += "Sec-Fetch-Mode: navigate\r\n"
request += "Sec-Fetch-Dest: iframe\r\n"
request += "Sec-Fetch-Storage-Access: active\r\n"
request += "Referer: https://cdnen.cgg4game.com/\r\n"
request += "Accept-Encoding: gzip, deflate, br, zstd\r\n"
request += "Accept-Language: zh-CN,zh;q=0.9\r\n"
request += "\r\n"
context = ssl.create_default_context()
with socket.create_connection((host, port)) as sock:
with context.wrap_socket(sock, server_hostname=host) as ssock:
ssock.sendall(request.encode())
response = b""
while True:
chunk = ssock.recv(4096)
if not chunk:
break
response += chunk
response_text = response.decode()
location_header = None
for line in response_text.split("\r\n"):
if line.lower().startswith("location:"):
location_header = line.split(":", 1)[1].strip()
break
if location_header:
parsed_url = urlparse(location_header)
query_params = parse_qs(parsed_url.query)
resVer = query_params.get("resVer", [None])[0]
print("resVer:", resVer)
output_file = 'naku.txt'
generate_download_urls(f'https://h.cgg4game.com/games/richman2Release/resource/default.res.{resVer}.json', output_file)
print(f"下载URL已导出到 {output_file}")
if os.path.exists(output_file):
os.system("aria2c -i naku.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/梦琪领导")
else:
print("未能生成下载列表,请检查错误信息")
else:
print("No Location header found")
3 个赞
感谢大佬无私分享, ![]()
![]()
![]() 。文件有缺失的可以加断点续传 -c 再下一次。
。文件有缺失的可以加断点续传 -c 再下一次。
aria2c -c -i naku.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/梦琪领导
1 个赞
ssr/v2ray这种是代理需要手动设置代理服务器
TUN模式是全局模式支持所有流量走代理就无需手动设置
梦琪领导 / 总统的野望 / 首富2 求分享,下不下来 ![]()
???
于2025 06 06 13:50 (UTC) 发现服务器更换地址为
1 个赞
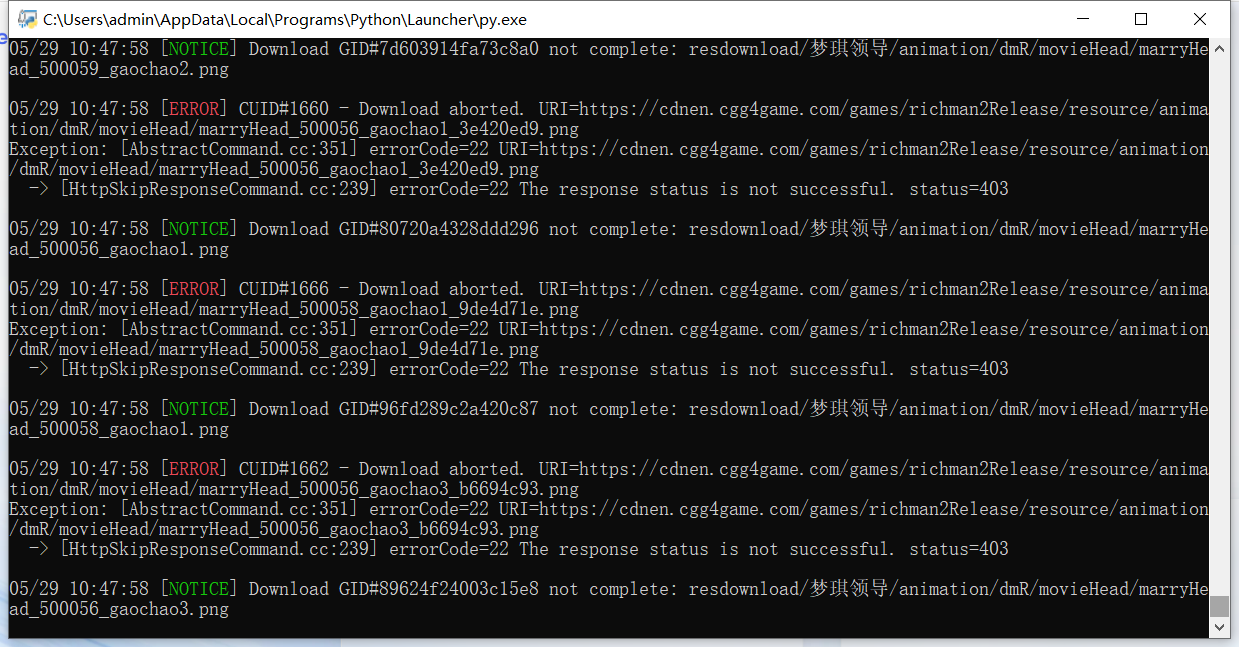
梦琪领导的脚本有些问题,下载链接和保存文件格式不一致时会失败,而且由于aria2的问题下载会失败
https://cdnen.cgg4game.com/games/richman2Release/resource/animation/dmR/lovePicture/marry_H4_5_b8165.png
out=animation/dmR/lovePicture/marry_H4_5.jpg
手动编写下载脚本,并纠正了上诉错误
import os
import requests
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
from urllib.parse import urlparse# 配置参数
MAX_WORKERS = 8 # 同时下载的线程数
MAX_RETRIES = 3 # 失败重试次数
TIMEOUT = 30 # 请求超时时间(秒)
CHUNK_SIZE = 8192 # 下载块大小def download_files(input_file):
# 准备下载环境
if not os.path.exists(‘downloads’):
os.makedirs(‘downloads’)# 初始化日志 error_log = "download_errors.log" with open(error_log, 'w', encoding='utf-8') as f: f.write(f"下载日志 - {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n") f.write(f"线程数: {MAX_WORKERS}, 重试次数: {MAX_RETRIES}\n\n") # 读取任务列表 tasks = [] with open(input_file, 'r', encoding='utf-8') as file: url, out_path = None, None for line in file: line = line.strip() if line.startswith('http'): url = line elif line.startswith('out='): out_path = line[4:].strip() if url and out_path: tasks.append((url, out_path)) url, out_path = None, None if not tasks: print("未发现有效下载任务!") return print(f"发现 {len(tasks)} 个下载任务,使用 {MAX_WORKERS} 线程下载...") # 多线程下载 success_count = 0 start_time = time.time() with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: futures = {executor.submit(download_task, task[0], task[1], error_log): task for task in tasks} for future in as_completed(futures): url, out_path = futures[future] try: if future.result(): success_count += 1 except Exception as e: log_error(error_log, url, out_path, f"线程异常: {str(e)}") # 统计结果 total_time = time.time() - start_time avg_speed = len(tasks) / total_time if total_time > 0 else 0 print(f"\n下载完成! 用时: {total_time:.2f}秒, 平均 {avg_speed:.2f}个/秒") print(f"成功: {success_count}/{len(tasks)}") if success_count < len(tasks): print(f"查看失败详情: {error_log}")def download_task(url, out_path, error_log):
for attempt in range(MAX_RETRIES):
try:
# 处理扩展名不一致的情况
parsed_url = urlparse(url)
url_ext = os.path.splitext(parsed_url.path)[1].lower()
out_ext = os.path.splitext(out_path)[1].lower()# 如果扩展名不一致,尝试修改URL的扩展名 modified_url = url if url_ext and out_ext and url_ext != out_ext: modified_url = url.rsplit('.', 1)[0] + out_ext print(f"注意: 扩展名不一致,尝试 {url} -> {modified_url}") # 准备路径 full_path = os.path.join('downloads', out_path) os.makedirs(os.path.dirname(full_path), exist_ok=True) # 检查文件是否已存在 if os.path.exists(full_path): file_size = os.path.getsize(full_path) headers = {'Range': f'bytes={file_size}-'} if file_size > 0 else {} mode = 'ab' if file_size > 0 else 'wb' else: headers = {} mode = 'wb' # 带进度显示下载 print(f"下载中: {os.path.basename(out_path)}...", end=' ', flush=True) with requests.get(modified_url, stream=True, headers=headers, timeout=TIMEOUT) as r: r.raise_for_status() total_size = int(r.headers.get('content-length', 0)) + (file_size if 'Range' in headers else 0) with open(full_path, mode) as f: for chunk in r.iter_content(chunk_size=CHUNK_SIZE): if chunk: f.write(chunk) print("✓") return True except Exception as e: if attempt == MAX_RETRIES - 1: # 最后一次尝试仍然失败 # 如果修改过扩展名失败,尝试用原始URL if modified_url != url: try: with requests.get(url, stream=True, timeout=TIMEOUT) as r: r.raise_for_status() with open(full_path, 'wb') as f: for chunk in r.iter_content(chunk_size=CHUNK_SIZE): if chunk: f.write(chunk) print("✓ (使用原始URL成功)") return True except Exception as e2: log_error(error_log, url, out_path, f"尝试 {MAX_RETRIES} 次后失败(包括扩展名修正尝试): {str(e2)}") print("✗") return False else: log_error(error_log, url, out_path, f"尝试 {MAX_RETRIES} 次后失败: {str(e)}") print("✗") return False time.sleep(1) # 失败后等待1秒再重试def log_error(log_file, url, out_path, message):
entry = f"[{datetime.now().strftime(‘%Y-%m-%d %H:%M:%S’)}] {url} → {out_path} | {message}\n"
with open(log_file, ‘a’, encoding=‘utf-8’) as f:
f.write(entry)if name == ‘main’:
input_file = input("请输入包含下载链接的txt文件路径: ").strip()
if not os.path.isfile(input_file):
print(“错误: 文件不存在!”)
else:
download_files(input_file)
运行
python “President’s Ambition download.py”
请输入包含下载链接的txt文件路径: naku.txt
遇到不一致时
注意: 扩展名不一致,尝试 https://cdnen.cgg4game.com/games/richman2Release/resource/animation/dmR/movieImg/movie_H39_4_49196e2f.png → https://cdnen.cgg4game.com/games/richman2Release/resource/animation/dmR/movieImg/movie_H39_4_49196e2f.jpg
下载中: movie_H39_4.jpg… ✓
1 个赞

{kind=link}
{kind=link}
{kind=link}
这就是我为什么说是半成品因为文件太多只验证了live2d和spine资源是否完整
这个问题只需要在文件后缀判断代码加上
elif file_name.endswith('.jpg'):
ext = '.jpg'
添加jpg类型的就行,不要盲目添加直接匹配.后面的字符,如live2d的文件就有类似xxx.2048.xxx的格式
Everlusting Life资源下载脚本
import os
import requests
import re
if 1:
if 1:
main_version = input('version eg:2.0.0>')
url = "https://assetservice.adult-chess.com/ac/get_assets_with_als"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"x-country": "JP",
"accept": "*/*",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9",
"content-type": "application/json"
}
payload = {
"state": f"ac-release-v{main_version}",
"static_type": "webgl_bundles"
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
data = response.json()
aria2_commands = []
if "result" in data and "assets" in data["result"]:
for category, items in data["result"]["assets"].items():
for item in items:
file_url = item.get("url", "")
if file_url:
path_parts = file_url.split("/webgl_bundles/")[-1]
output_path = f"download/webgl_bundles/{path_parts}"
command = f"{file_url}\n out={output_path}"
aria2_commands.append(command)
with open("everlustinglife.txt", "w", encoding="utf-8") as f:
f.write("\n".join(aria2_commands))
print(f"保存成功:everlustinglife.txt,共{len(aria2_commands)}个下载链接")
os.system("aria2c -i everlustinglife.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/everlustinglife")
except requests.RequestException as e:
print("请求失败:", e)
except ValueError:
print("响应不是有效的 JSON")
except Exception as e:
print("发生错误:", e)
欲望女神
import os
import requests
main_version = input('version eg:7.0.0>')
url = "https://6cc9.prod.assetservice.chickgoddess.com/aw/get_assets_with_als"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 Edg/137.0.0.0",
"x-country": "JP",
"pnk-abtest-group": "Base",
"accept": "*/*",
"origin": "https://client.chickgoddess.com",
"sec-fetch-site": "same-site",
"sec-fetch-mode": "cors",
"sec-fetch-dest": "empty",
"referer": "https://client.chickgoddess.com/",
"accept-encoding": "gzip, deflate, br, zstd",
"accept-language": "zh-CN,zh;q=0.9"
}
# 需要 MessagePack 编码的数据
payload = {
"state": f"aw-release-v{main_version}",
"static_type": "webgl_bundles",
"assets_names": None
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
data = response.json()
aria2_commands = []
if "result" in data and "assets" in data["result"]:
for category, items in data["result"]["assets"].items():
for item in items:
file_url = item.get("url", "")
if file_url:
path_parts = file_url.split("/webgl_bundles/")[-1]
output_path = f"download/webgl_bundles/{path_parts}"
command = f"{file_url}\n out={output_path}"
aria2_commands.append(command)
with open("ywns.txt", "w", encoding="utf-8") as f:
f.write("\n".join(aria2_commands))
print(f"保存成功:ywns.txt,共{len(aria2_commands)}个下载链接")
os.system("aria2c -i ywns.txt -j 32 -s 16 -x 16 --check-certificate=false --dir=resdownload/欲望女神")
except requests.RequestException as e:
print("请求失败:", e)
except ValueError:
print("响应不是有效的 JSON")
except Exception as e:
print("发生错误:", e)
1 个赞