收到了日本朋友的邮件看了一眼这不是早就暴毙的 女神降临/Goddess Arrival 吗

这还能肘赢牢大打赢复活赛我是真没想到…

与前作稍有一点不一样UI更新了(按理说是原作苍空物语更新的UI…)
加密只有H资产的png加密了
这里也给想学的小白一个参考如何快速定位这种cocos2djs在线页游的解密代码
直接打开“发起程序”
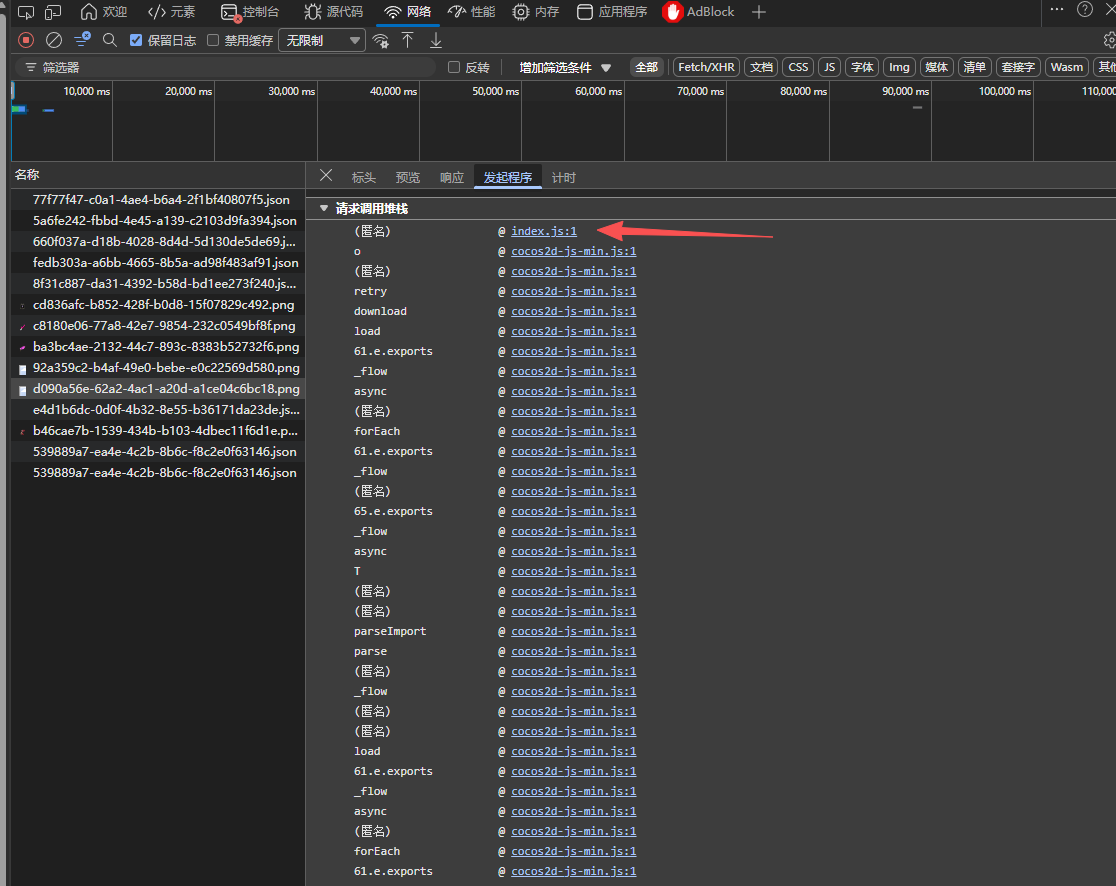
可以看到是index,js拉起的加密png下载
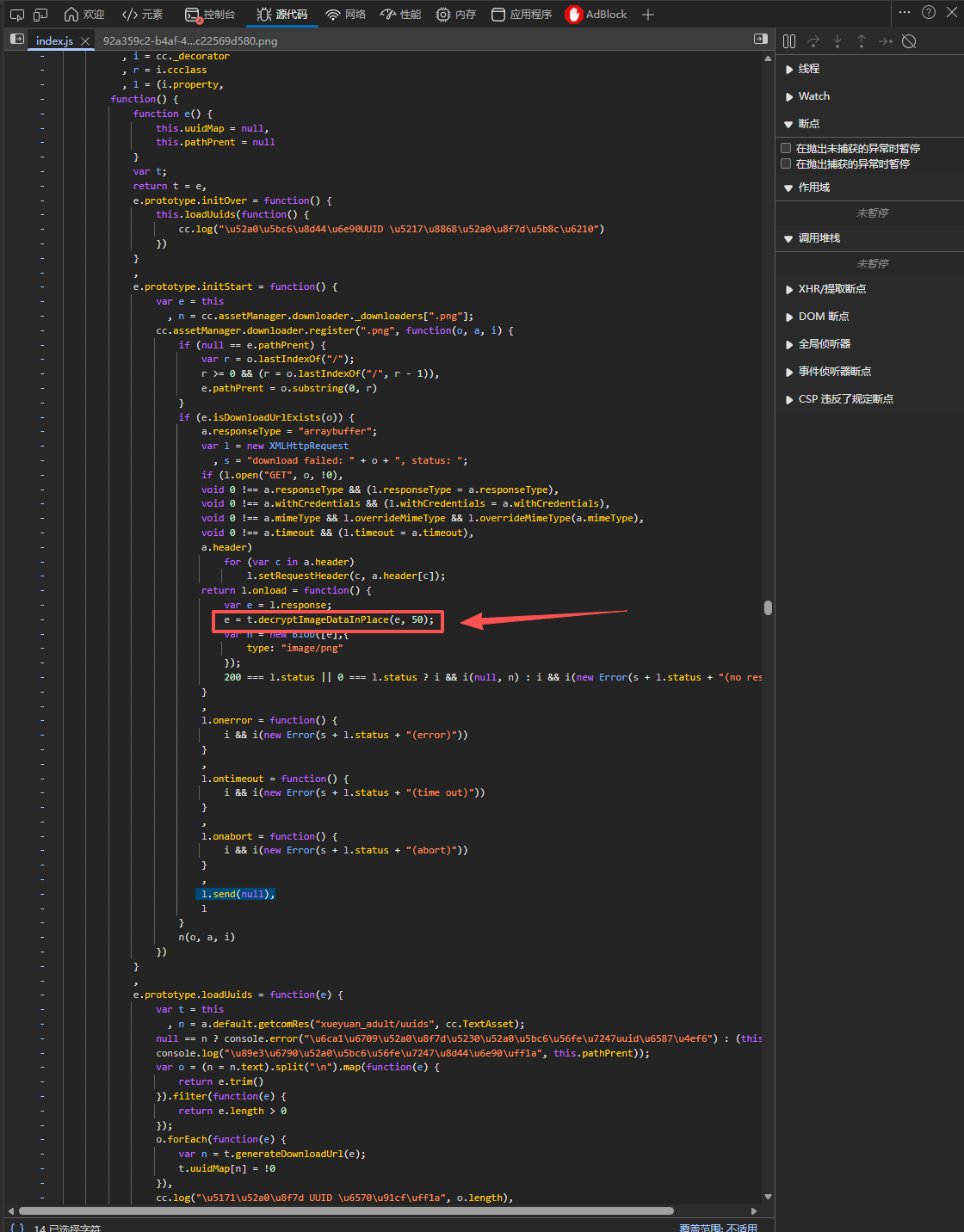
转到上下文后可以看到有个decryptImageDataInPlace函数调用名字已经暴露一切
然后找到函数原型

参考python解密代码
import os
def decrypt_image_in_place(data: bytearray, t: int):
n = len(data)
a = (n // 2) - (t // 2)
for i in range(t):
r = a + (i % t)
data[i] ^= data[r]
data[n - t + i] ^= data[r]
return data
def decrypt_file_in_place(file_path, t=50):
with open(file_path, "rb") as f:
data = bytearray(f.read())
# 直接判断文件头是不是合法png头来判断是不是加密文件
if data[:8] == b'\x89PNG\r\n\x1a\n':
print(f"跳过已解密文件: {file_path}")
return
print(f"解密文件: {file_path},长度: {len(data)} 字节")
decrypt_image_in_place(data, t)
with open(file_path, "wb") as f:
f.write(data)
print(f"已覆盖原文件: {file_path}")
def decrypt_directory(base_dir, t=50):
for root, _, files in os.walk(base_dir):
for file in files:
if file.lower().endswith(".png"):
file_path = os.path.join(root, file)
decrypt_file_in_place(file_path, t)
if __name__ == "__main__":
target_dir = r"resdownload\Goddess Contract"
decrypt_directory(target_dir)
参考的下载器源码(仅H资产)
import os
import requests
import json
import re
from urllib.parse import urljoin
from concurrent.futures import ThreadPoolExecutor, as_completed
proxyaddr = useproxy = 0
def nsljdownloader(overwrite):
BASE64_CHARS = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
BASE64_VALUES = [0] * 128
for idx, char in enumerate(BASE64_CHARS):
BASE64_VALUES[ord(char)] = idx
HEX_CHARS = list('0123456789abcdef')
_t = ['', '', '', '']
UUID_TEMPLATE = _t + _t + ['-'] + _t + ['-'] + _t + ['-'] + _t + ['-'] + _t + _t + _t
INDICES = [i for i, x in enumerate(UUID_TEMPLATE) if x != '-']
mainurl = "https://res-engame.goodviewvip.com"
def decode_uuid(base64_str):
if len(base64_str) != 22:
return base64_str
result = UUID_TEMPLATE.copy()
result[0] = base64_str[0]
result[1] = base64_str[1]
j = 2
for i in range(2, 22, 2):
lhs = BASE64_VALUES[ord(base64_str[i])]
rhs = BASE64_VALUES[ord(base64_str[i + 1])]
result[INDICES[j]] = HEX_CHARS[lhs >> 2]
j += 1
result[INDICES[j]] = HEX_CHARS[((lhs & 3) << 2) | (rhs >> 4)]
j += 1
result[INDICES[j]] = HEX_CHARS[rhs & 0xF]
j += 1
return ''.join(result)
def has_sp_skeleton_data(obj):
if isinstance(obj, list):
if len(obj) > 0 and obj[0] == "sp.SkeletonData":
return obj
for item in obj:
found = has_sp_skeleton_data(item)
if found:
return found
elif isinstance(obj, dict):
for value in obj.values():
found = has_sp_skeleton_data(value)
if found:
return found
elif obj == "sp.SkeletonData":
return 1
return None
def getspresjson(bundle):
url2 = f"https://res-engame.goodviewvip.com/gamefileen/9008/assets/resources/config.json"
try:
response2 = requests.get(url2)
response2.raise_for_status()
return response2.json()
except Exception as e:
print(e)
return None
def has_sp_skeleton_data(data):
if isinstance(data, dict) and data.get("__type__") == "sp.SkeletonData":
return True
if isinstance(data, list) and any("sp.SkeletonData" in str(x) for x in data):
return True
return False
def process_uuid(idx, sid, uuids, paths, BASE, output_dir):
try:
if paths.get(str(idx)) and paths.get(str(idx))[1] == types.index("sp.SkeletonData"):
uuid = decode_uuid(sid)
full_uuid = f"{uuid}"
res_path = paths[str(idx)][0]
if "xueyuan_adult" not in res_path:
return
json_url = f"{BASE}/import/{uuid[:2]}/{full_uuid}.json"
skel_url = f"{BASE}/native/{uuid[:2]}/{full_uuid}.bin"
base_name = os.path.basename(res_path)
print(f'json - {base_name}.json -> {json_url} | skel - {base_name}.skel -> {skel_url}')
try:
response = requests.get(json_url)
response.raise_for_status()
json_data = response.json()
except Exception as e:
print(f"[!] 下载失败: {json_url} ({e})")
return
if not has_sp_skeleton_data(json_data):
return
folder = os.path.join(output_dir, *res_path.split("/"))
os.makedirs(folder, exist_ok=True)
try:
sp_type_block = next(item for item in json_data[3] if item[0] == "sp.SkeletonData")
field_names = sp_type_block[1]
except Exception as e:
print(f"[!] 无法解析字段名: {e}")
return
try:
obj_data = json_data[5][0]
field_values = obj_data[1:]
sp_dict = dict(zip(field_names, field_values))
_name = sp_dict.get("_name", base_name)
_atlasText = sp_dict.get("_atlasText", "")
_skeletonJson = sp_dict.get("_skeletonJson", None)
atlas_path = os.path.join(folder, f"{_name}.atlas")
if os.path.exists(atlas_path) and not overwrite:
print(f"[!] 已存在 atlas,跳过:{_name}.atlas")
else:
with open(atlas_path, "w", encoding="utf-8") as f:
f.write(_atlasText)
print(f"[+] 写入 atlas 成功:{_name}.atlas")
if _skeletonJson:
json_path = os.path.join(folder, f"{_name}.json")
with open(json_path, "w", encoding="utf-8") as f:
json.dump(_skeletonJson, f, ensure_ascii=False, indent=2)
print(f"[+] 写入 skeletonJson 成功:{_name}.json")
else:
skel_path = os.path.join(folder, f"{_name}.skel")
with open("nslj.txt", "a", encoding="utf-8") as f:
f.write(f"{skel_url}\n out={skel_path}\n")
pngdata = json_data[1]
for i, pngsid in enumerate(pngdata):
pnguuid = decode_uuid(pngsid[:22])
try:
idxpng = uuids.index(pngsid[:22])
pngurl = f"{BASE}/native/{pnguuid[:2]}/{pnguuid}.png"
png_tempname = f"{_name}_{i + 1}" if i >= 1 else f"{_name}"
png_path = os.path.join(folder, png_tempname + ".png")
print(f'{png_tempname}.png -> {pngurl}')
with open("nslj.txt", "a", encoding="utf-8") as f:
f.write(f"{pngurl}\n out={png_path}\n")
except Exception as e:
print(f"[!] PNG处理失败: {e}")
except Exception as e:
print(f"[!] 解包 sp.SkeletonData 数据失败: {e}")
except Exception as e:
print(f"[!] UUID处理失败: {e}")
def resdownloader(BASE, data, output_dir, max_workers=8):
if not data:
return
uuids = data["uuids"]
paths = data["paths"]
global types
types = data["types"]
if "sp.SkeletonData" not in types:
print(f"[!] 未找到 sp.SkeletonData 数据")
return
os.makedirs(output_dir, exist_ok=True)
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = []
for idx, sid in enumerate(uuids):
futures.append(executor.submit(process_uuid, idx, sid, uuids, paths, BASE, output_dir))
for future in as_completed(futures):
future.result()
def decrypt_image_in_place(data: bytearray, t: int):
n = len(data)
a = (n // 2) - (t // 2)
for i in range(t):
r = a + (i % t)
data[i] ^= data[r]
data[n - t + i] ^= data[r]
return data
def decrypt_file_in_place(file_path, t=50):
with open(file_path, "rb") as f:
data = bytearray(f.read())
if data[:8] == b'\x89PNG\r\n\x1a\n':
#print(f"跳过已解密文件: {file_path}")
return
print(f"解密文件: {file_path},长度: {len(data)} 字节")
decrypt_image_in_place(data, t)
with open(file_path, "wb") as f:
f.write(data)
def decrypt_directory(base_dir, t=50):
for root, _, files in os.walk(base_dir):
for file in files:
if file.lower().endswith(".png"):
file_path = os.path.join(root, file)
decrypt_file_in_place(file_path, t)
if os.path.exists("nslj.txt"):
os.remove("nslj.txt")
resdownloader(f"{mainurl}/gamefileen/9008/assets/resources", getspresjson('normal'),
"resdownload\\Goddess Contract")
os.system(f"aria2c -i nslj.txt -j 16 --max-tries=100 --retry-wait=60 --auto-file-renaming=false {f'{proxyaddr} ' if useproxy else ''}{'--allow-overwrite=true ' if overwrite else ''}--check-certificate=false")
target_dir = r"resdownload\Goddess Contract"
decrypt_directory(target_dir)
nsljdownloader(0)
顺带问一问谁保留了原来老版本的数据包
可以参考这个解密
似乎这个新版本还少了几个角色的cg