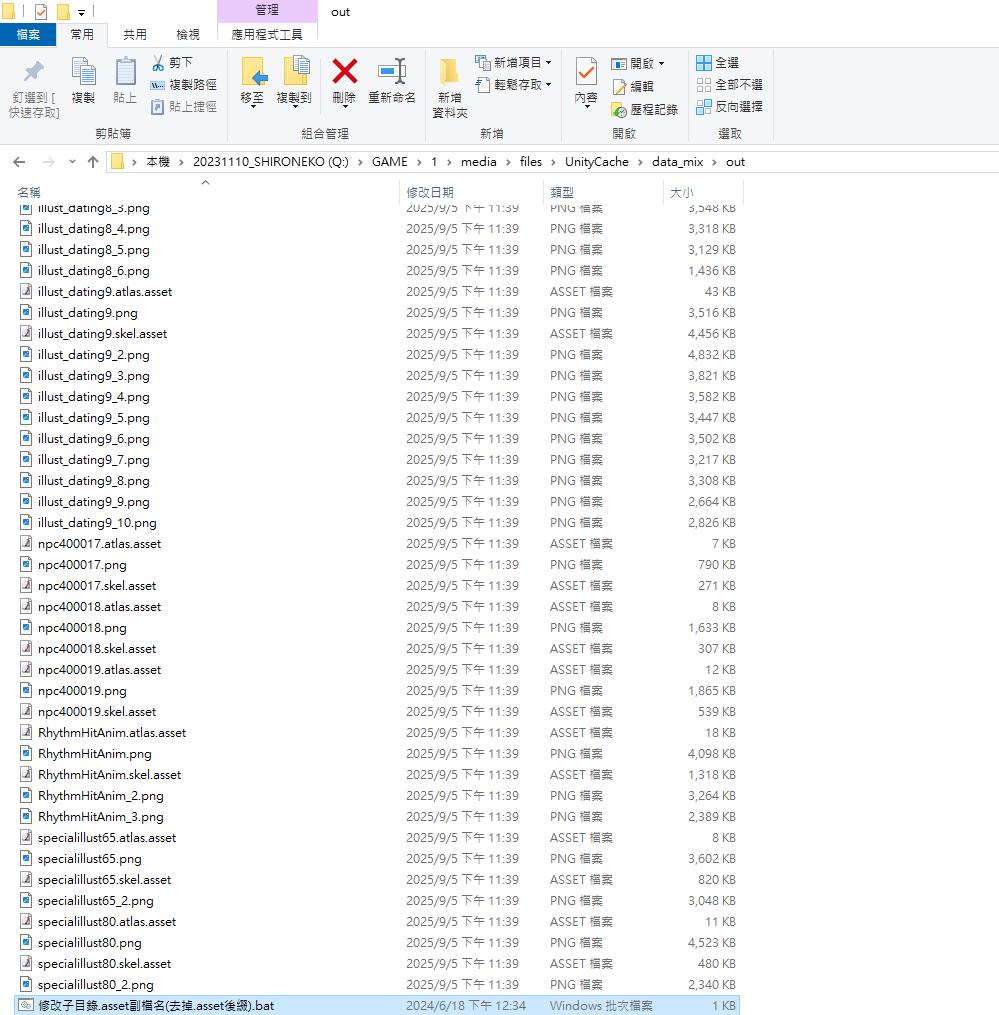
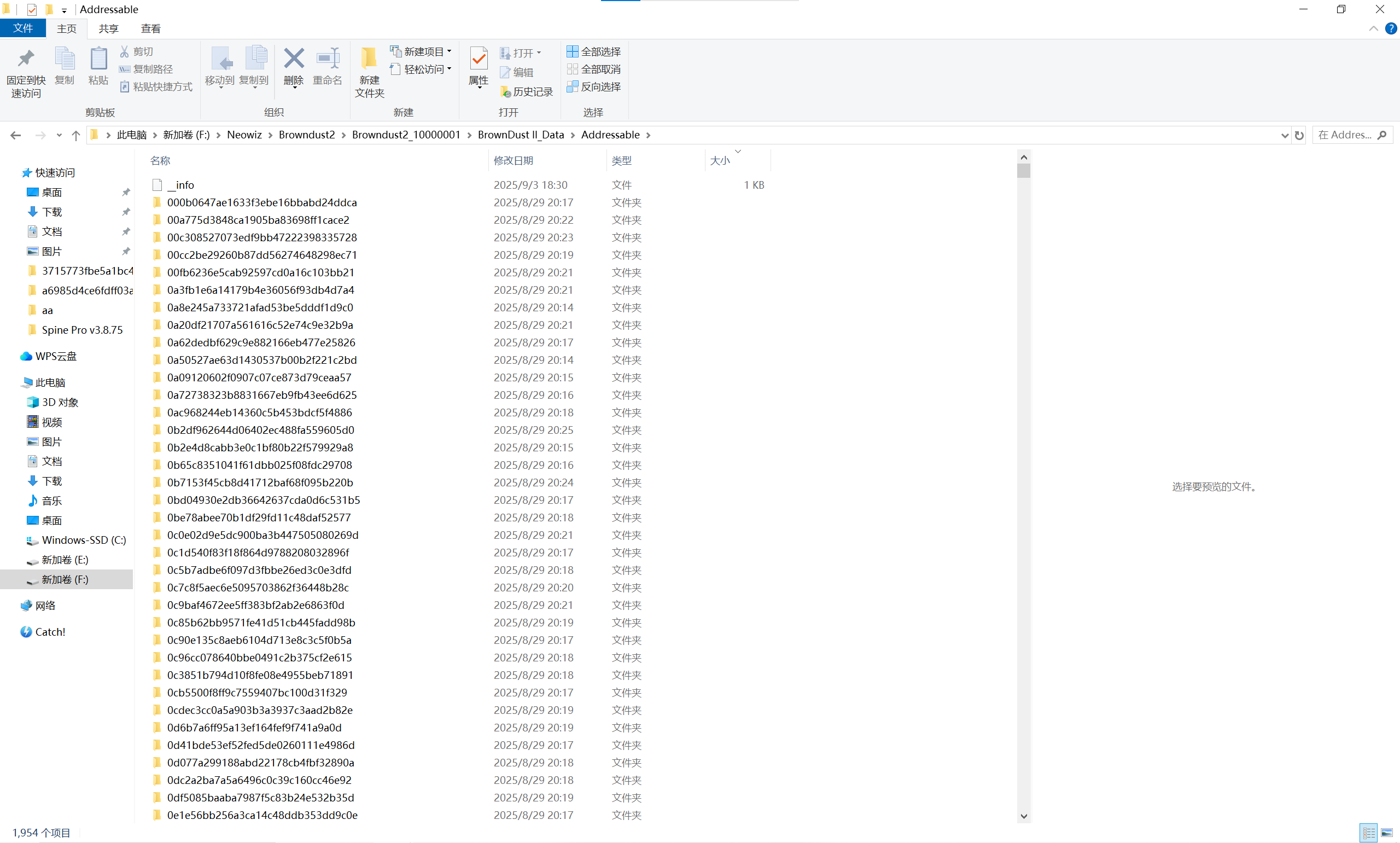
我是直接在本地资源文件中通过文件大小判断角色模型文件大概在Addressable文件夹中,但里面项目繁多,如下所示
我找了几个_data文件,加上.bundle后缀后尝试用as解包,能导出一些文件,但这样工程量未免太大了吧
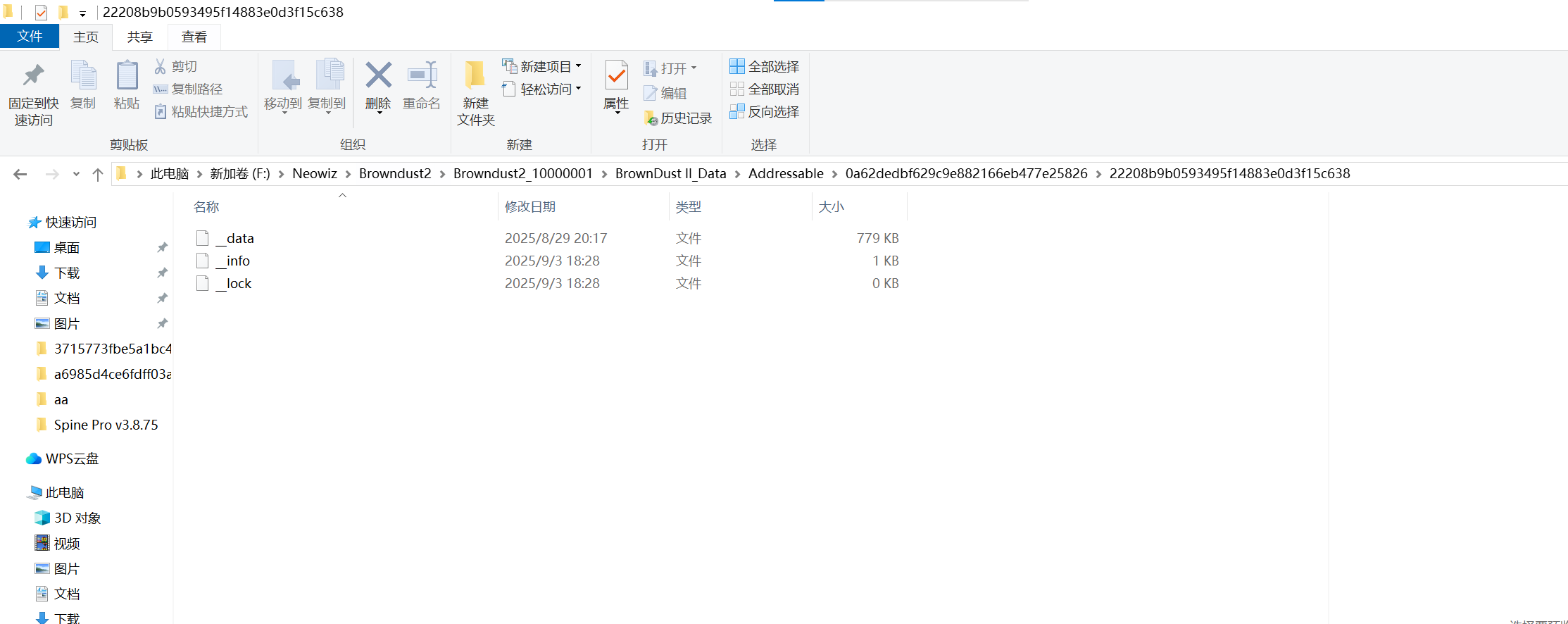
不知道这个方法对不对,求大佬解答一下
游戏安装包:下载链接:https://wwhu.lanzoub.com/igPFS33th1sh 密码:g3xp
我是直接在本地资源文件中通过文件大小判断角色模型文件大概在Addressable文件夹中,但里面项目繁多,如下所示
我找了几个_data文件,加上.bundle后缀后尝试用as解包,能导出一些文件,但这样工程量未免太大了吧
不知道这个方法对不对,求大佬解答一下
游戏安装包:下载链接:https://wwhu.lanzoub.com/igPFS33th1sh 密码:g3xp
但是这么多文件该怎么解包找到角色模型文件啊,是要用脚本还是其他的方法呢,大佬求教
前言 :
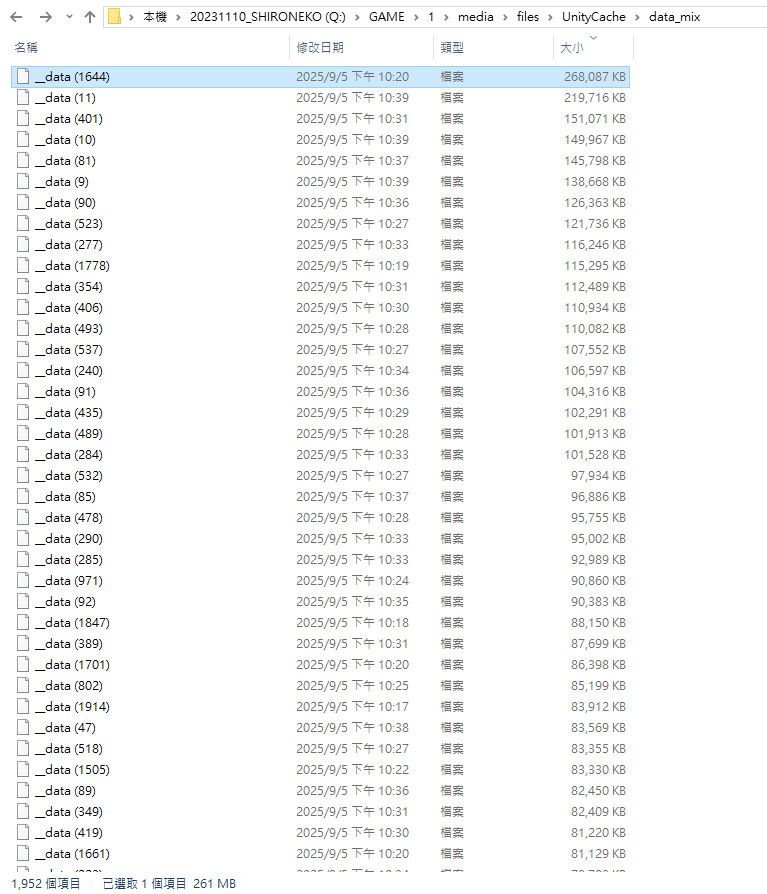
遊戲資料都下載到本地後
原AB包文件名會變更
\hash\hash\__data 型式
本質一樣是AB包
可以使用RAZ版AssetStudio開啟
Step01
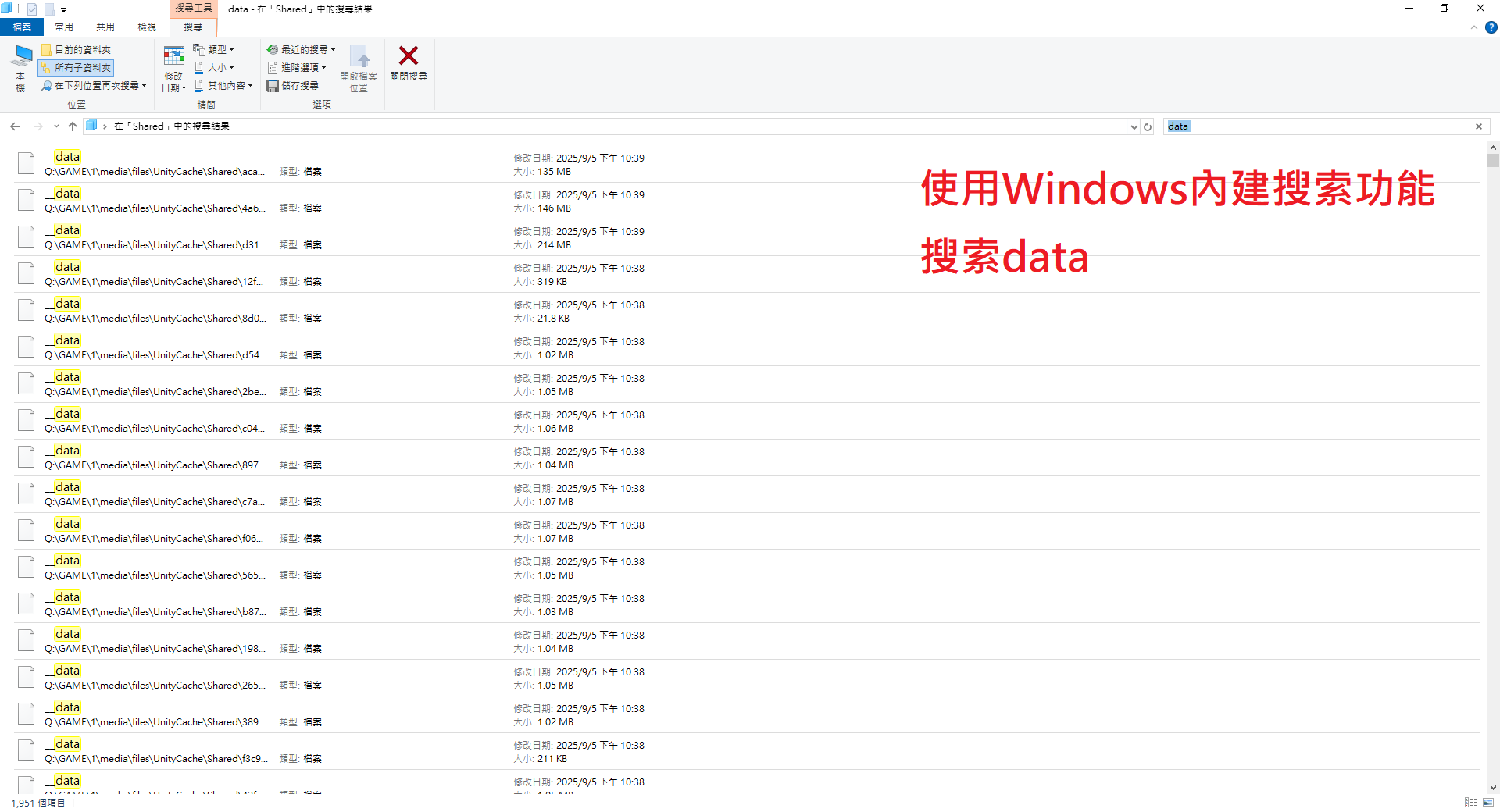
使用Windows內建搜索功能
搜索data
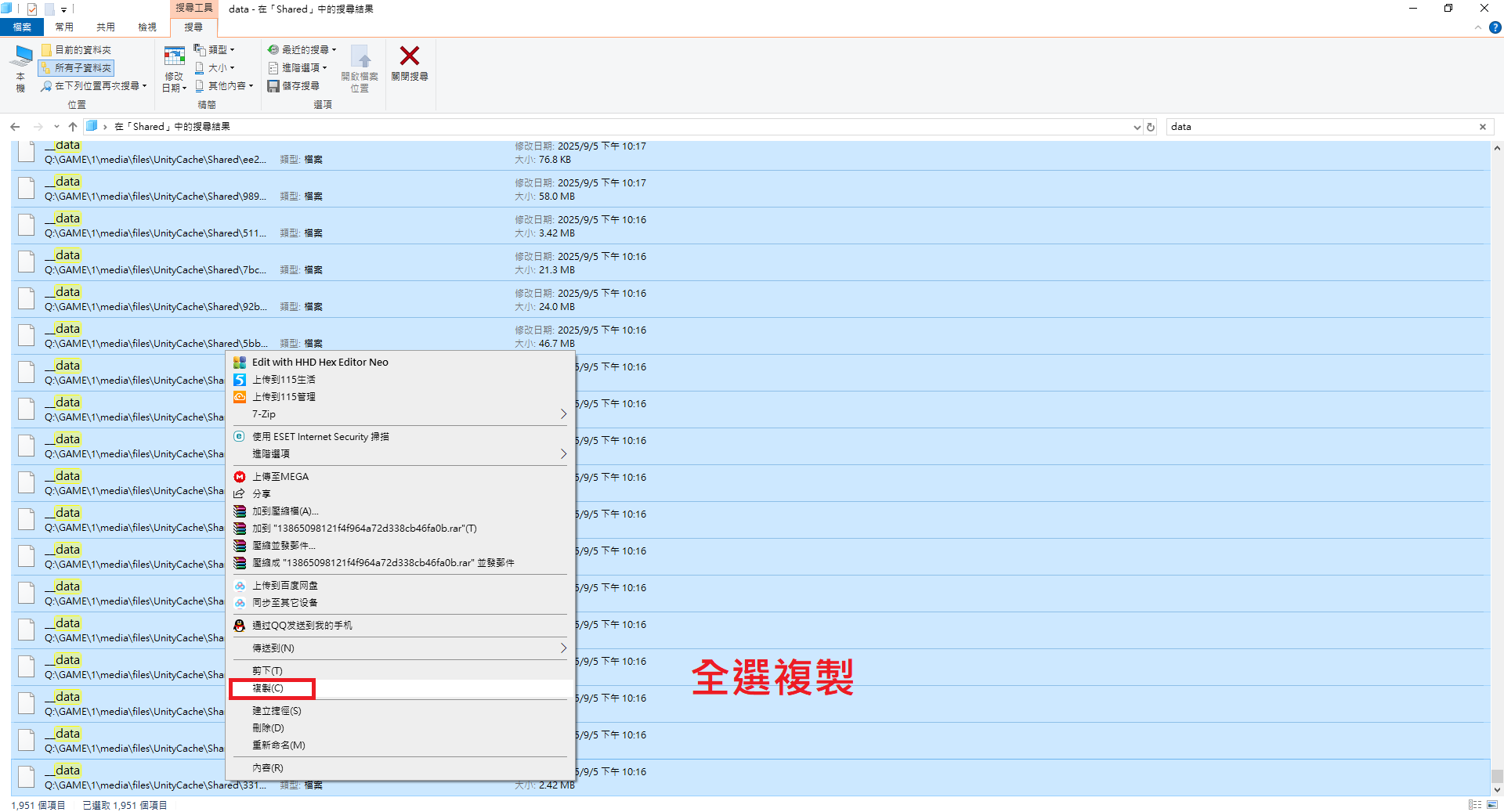
全選複製
Step02
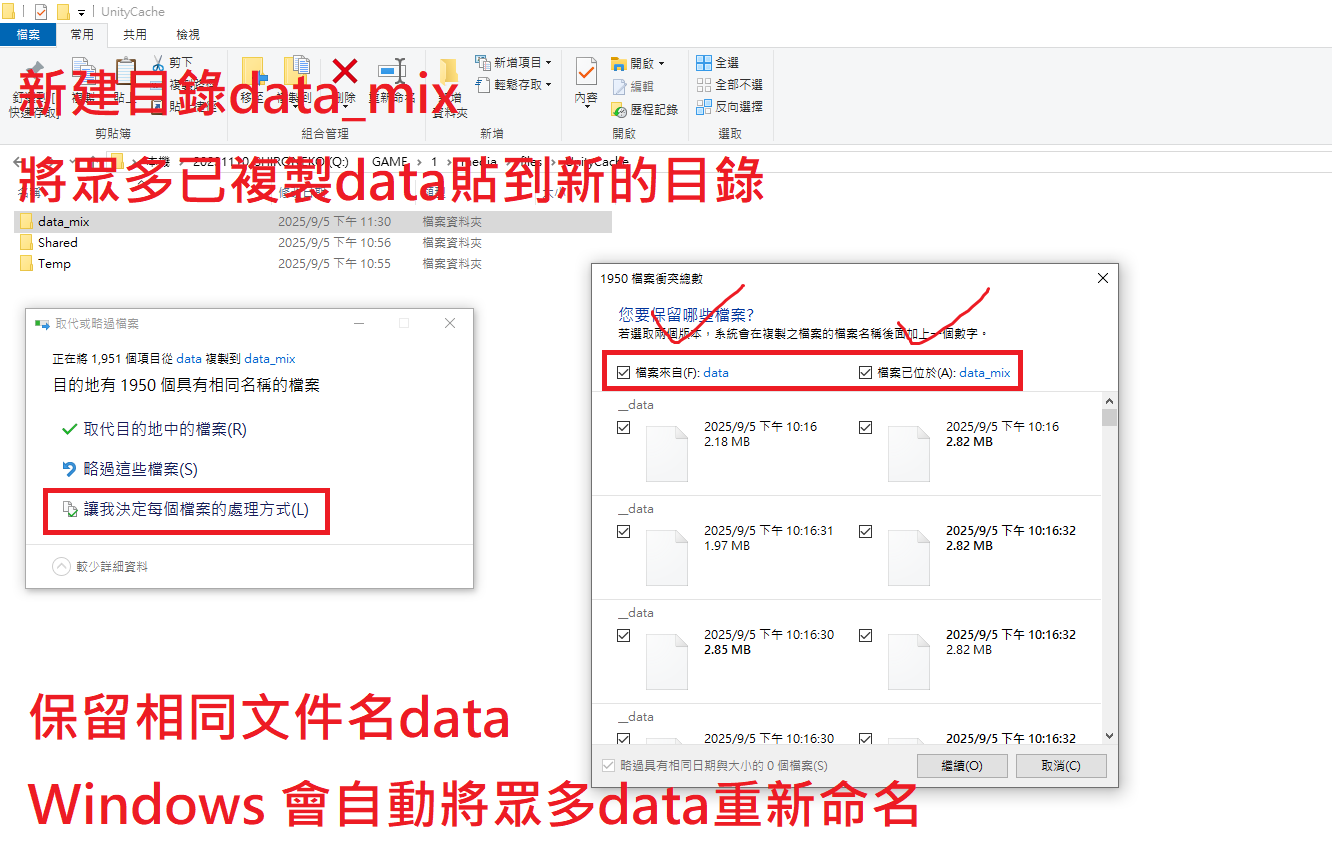
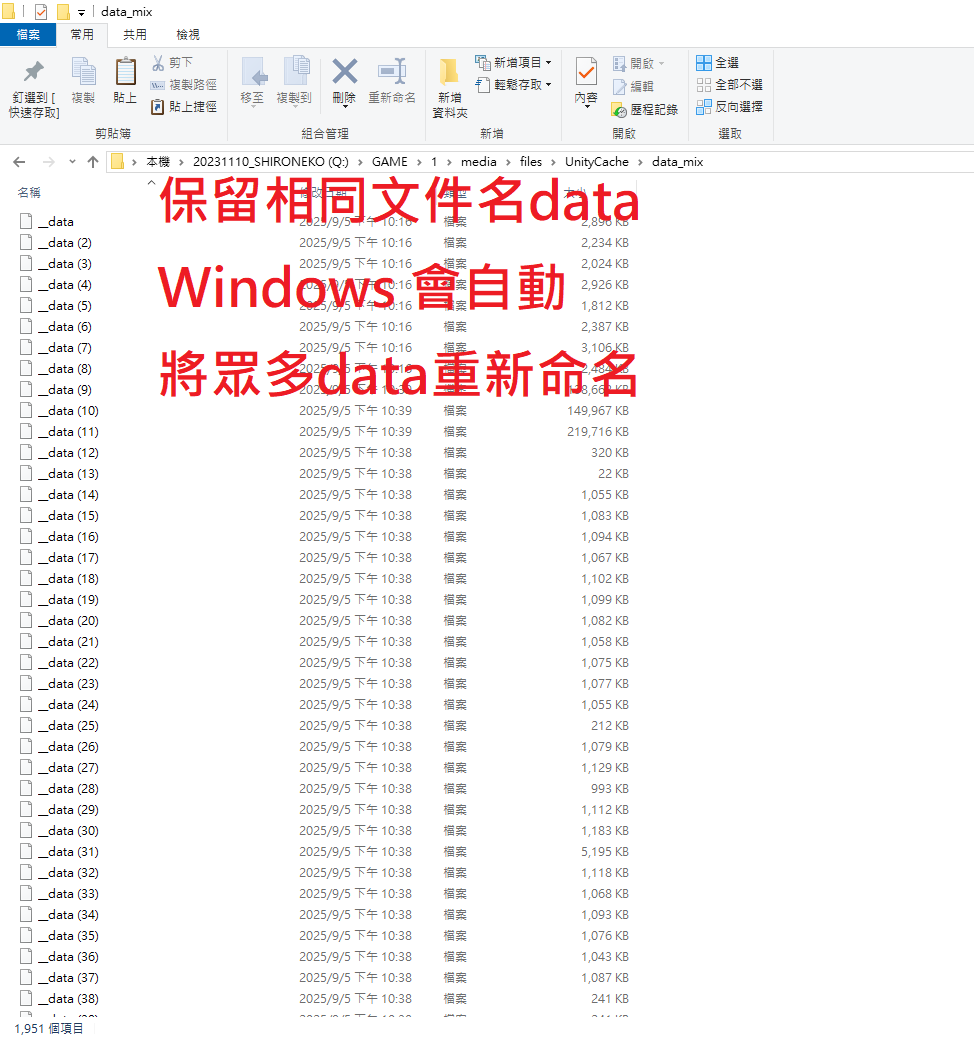
新建目錄data_mix
將眾多已複製data貼到新的目錄
Step03
保留相同文件名data
Windows 會自動將眾多data重新命名
Step04
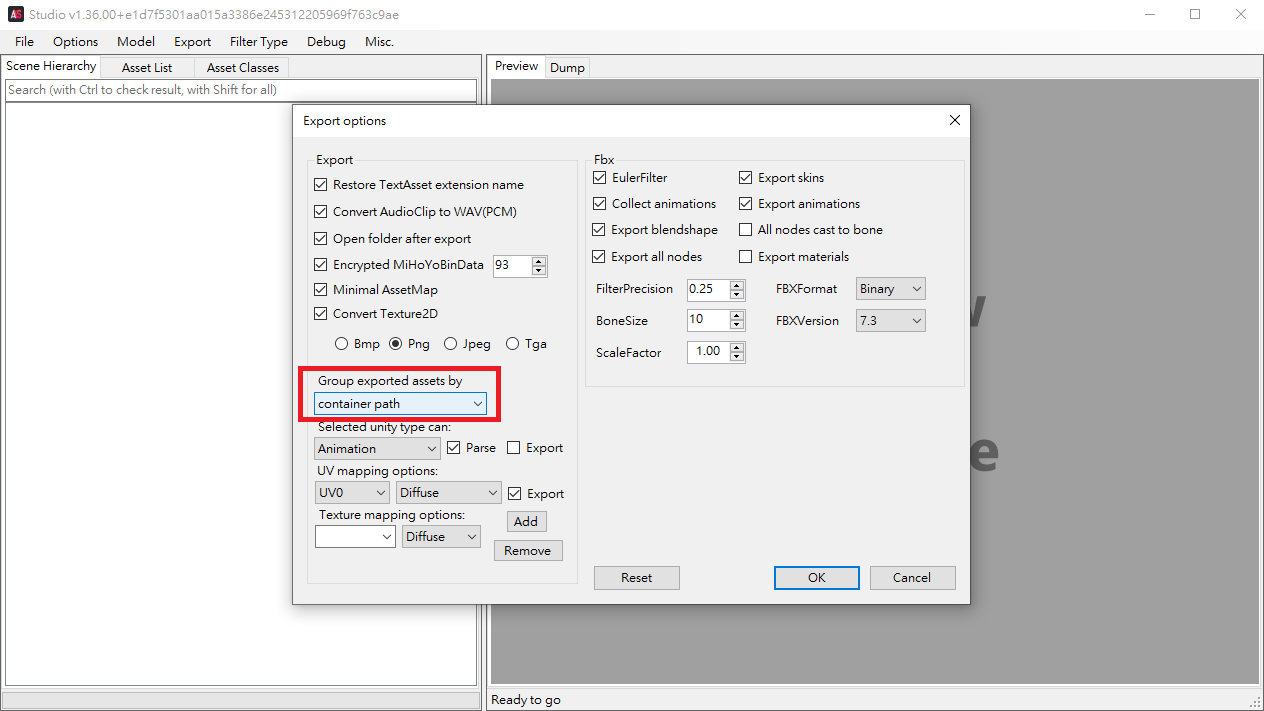
Raz 版AssetStudio設定 Options —> Export options —> Group exported assets by container path
效果 : 解包出來的資料會依AB包自帶路徑生成目錄 , 會將遊戲資料分類好
Step05
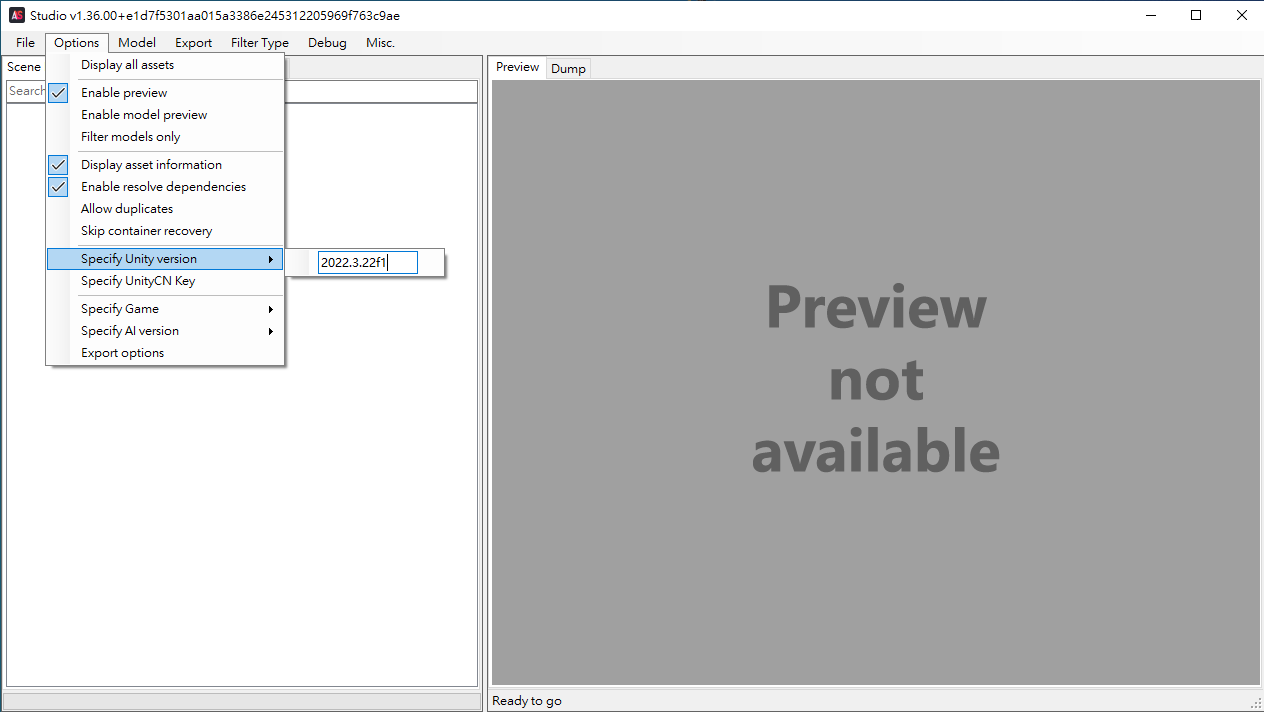
Raz 版AssetStudio設定 Options —> Specify Unity version —> 填入2022.3.22f1
效果 : 繞過File Header 文件頭簡單的偽裝 , 可直接讀取AB包內資料
Step06
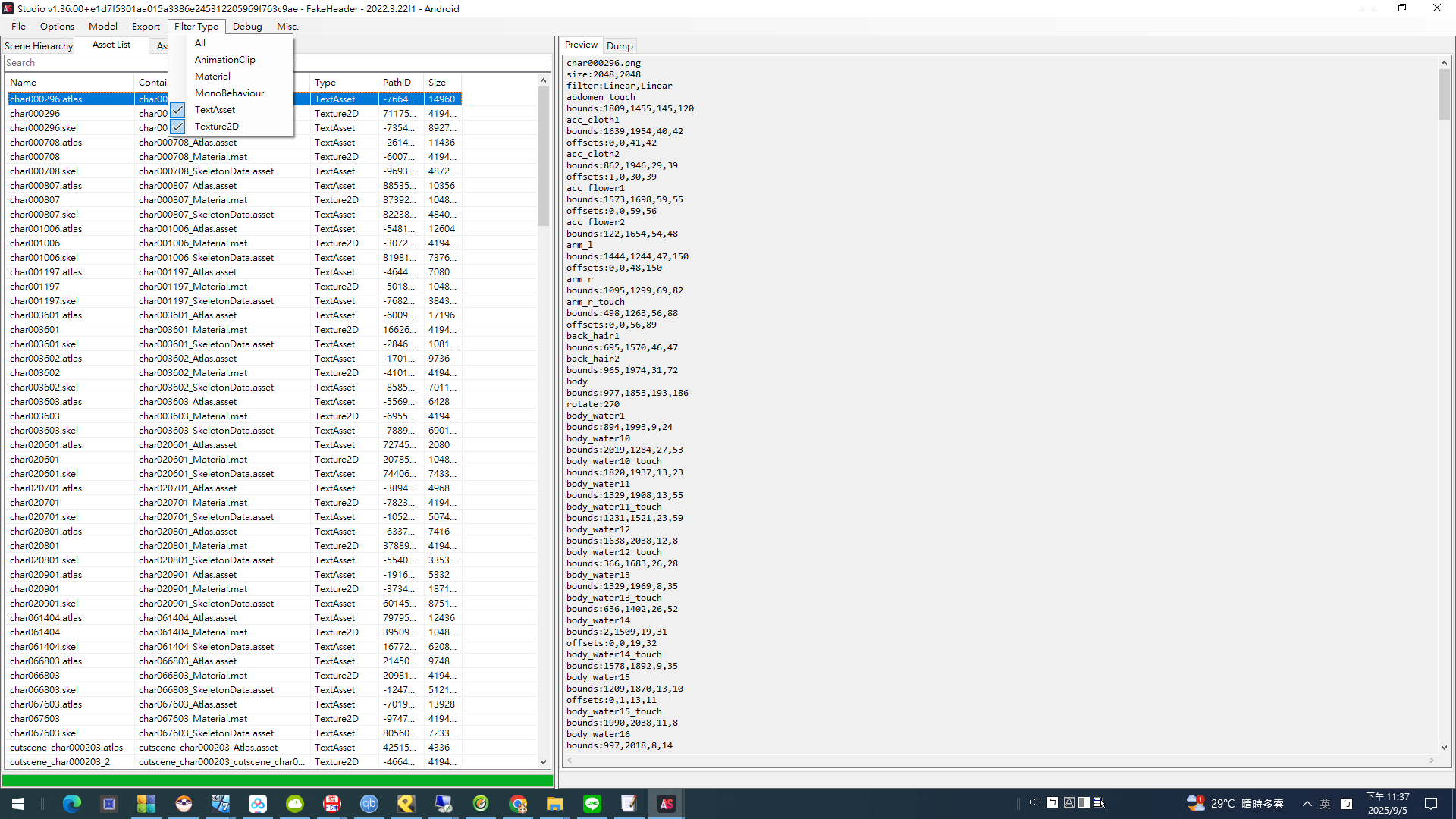
Raz 版AssetStudio開啟一堆data文件名AB包 , 因為樓主要角色SPINE , 可以先將眾多data依文件大小排序
先開啟最大的AB包 , 我這邊一開就中 , 第一個AB包就是SPINE文件
Step07
Raz 版AssetStudio開啟AB包後 , 輸出類別勾選 Filter Type → TextAsset , Texture2D , 輸出目錄自行生成為out
註 : Spine文件勾選這兩項就行
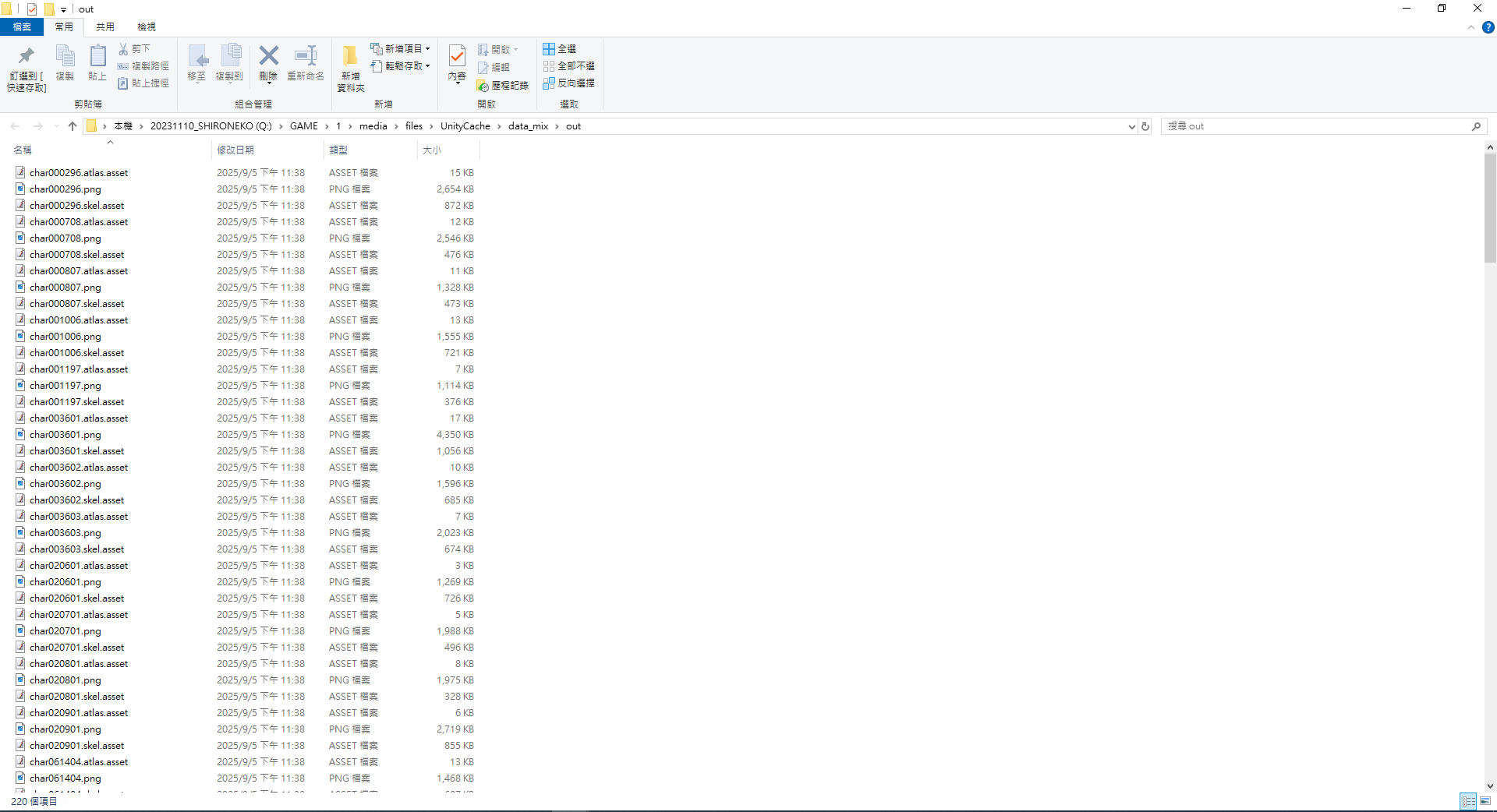
Step08
輸出完成後會看到SPINE文件多了後綴asset
使用bat批次檔去除多於後綴
修改子目錄.asset副檔名(去掉.asset後綴).rar (435 字节)
.atlas.asset ----> .atlas
.skel.asset ----> .skel
Step09
skeletonViewer-4.1.24.jar 開啟skel文件 完成

过滤container啊
你都能用as打开了
排序和搜索这两是计算机基础的
而且你不需要要改后缀名as能打开所有符合unity的文件
ok了,发现是as的问题,换了一个版本的as解决了,谢谢大佬!辛苦
解决了,谢谢大佬,辛苦
Addressable应该是用的unity的Addressable可寻址封包方式,他通过远程加载的文件会以/{hash}/_data的形式缓存,基本上只能全部加载一遍然后导出texture和TextAsset,然后脚本整理spine。
import os
import shutil
import re
import concurrent.futures
import multiprocessing
def get_unique_folder_name(destination_folder, base_name, parent_folder_name=None):
# 先尝试用父文件夹名命名
if parent_folder_name:
target_folder = os.path.join(destination_folder, parent_folder_name)
if not os.path.exists(target_folder):
return target_folder
# 若父文件夹名已存在,再尝试用atlas文件名命名
target_folder = os.path.join(destination_folder, base_name)
if not os.path.exists(target_folder):
return target_folder
# 若atlas文件名也已存在,使用atlas文件名+_number命名
number = 1
while True:
target_folder = os.path.join(destination_folder, f"{base_name}_{number}")
if not os.path.exists(target_folder):
return target_folder
number += 1
def process_atlas_file(root, file, destination_folder, operation):
# 获取 .atlas 文件的基本名称
base_name = os.path.splitext(file)[0]
# 获取 .atlas 文件原地址所在的上一级文件夹名字
parent_folder_name = os.path.basename(os.path.dirname(os.path.join(root, file)))
# 获取唯一的目标文件夹名称
target_folder = get_unique_folder_name(destination_folder, base_name, parent_folder_name)
try:
os.makedirs(target_folder)
print(f"已创建子文件夹: {target_folder}")
except FileExistsError:
# 这种情况理论上不应该发生,但为了以防万一
print(f"文件夹 {target_folder} 已存在,尝试生成新的唯一名称...")
target_folder = get_unique_folder_name(destination_folder, base_name + "_new", parent_folder_name)
os.makedirs(target_folder)
print(f"已创建新的子文件夹: {target_folder}")
# 处理 .atlas 文件
atlas_file_path = os.path.join(root, file)
if operation == 'copy':
shutil.copy2(atlas_file_path, target_folder)
print(f"已复制 .atlas 文件: {atlas_file_path} 到 {target_folder}")
else:
shutil.move(atlas_file_path, target_folder)
print(f"已移动 .atlas 文件: {atlas_file_path} 到 {target_folder}")
# 寻找并处理 .json 或 .skel 文件
for ext in ['.json', '.skel']:
related_file = base_name + ext
related_file_path = os.path.join(root, related_file)
if os.path.exists(related_file_path):
if operation == 'copy':
shutil.copy2(related_file_path, target_folder)
print(f"已复制 {ext} 文件: {related_file_path} 到 {target_folder}")
else:
shutil.move(related_file_path, target_folder)
print(f"已移动 {ext} 文件: {related_file_path} 到 {target_folder}")
# 【修改部分】从atlas文件中提取PNG文件名
png_filenames = []
try:
with open(atlas_file_path, 'r', encoding='utf-8') as f:
atlas_content = f.read()
# 匹配所有包含.png的字符串(完整文件名)
# 正则规则:匹配以任意字符开头,包含.png的完整文件名(直到换行符)
png_pattern = re.compile(r'[^\n]+\.png', re.IGNORECASE)
png_matches = png_pattern.findall(atlas_content)
# 去重处理
png_filenames = list(set(png_matches))
print(f"从.atlas文件中提取到PNG文件名: {png_filenames}")
except Exception as e:
print(f"读取.atlas文件失败: {e}")
return
# 【修改部分】用提取到的文件名匹配PNG文件
search_dirs = [root] + [os.path.join(root, d) for d in os.listdir(root) if os.path.isdir(os.path.join(root, d))]
parent_dir = os.path.dirname(root)
if parent_dir:
search_dirs.append(parent_dir)
for png_filename in png_filenames:
found = False
for search_dir in search_dirs:
png_file_path = os.path.join(search_dir, png_filename)
if os.path.exists(png_file_path) and os.path.isfile(png_file_path):
if operation == 'copy':
shutil.copy2(png_file_path, target_folder)
print(f"已复制 .png 文件: {png_file_path} 到 {target_folder}")
else:
shutil.move(png_file_path, target_folder)
print(f"已移动 .png 文件: {png_file_path} 到 {target_folder}")
found = True
break
if not found:
print(f"未找到PNG文件: {png_filename}")
def find_and_copy_files(source_folder, destination_folder, operation):
# 确保目标文件夹存在
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
print(f"已创建目标文件夹: {destination_folder}")
atlas_files = []
# 遍历源文件夹及其子文件夹,找出所有 .atlas 文件
for root, _, files in os.walk(source_folder):
for file in files:
if file.endswith('.atlas'):
atlas_files.append((root, file))
# 获取 CPU 核心数
cpu_count = multiprocessing.cpu_count()
# 使用线程池并行处理 .atlas 文件
with concurrent.futures.ThreadPoolExecutor(max_workers=cpu_count) as executor:
futures = []
for root, file in atlas_files:
future = executor.submit(process_atlas_file, root, file, destination_folder, operation)
futures.append(future)
# 等待所有任务完成
for future in concurrent.futures.as_completed(futures):
try:
future.result()
except Exception as e:
print(f"处理文件时出现错误: {e}")
if __name__ == "__main__":
source_folder = input("请输入源文件夹路径: ").strip()
destination_folder = input("请输入目标文件夹路径: ").strip()
# 去除引号
source_folder = source_folder.strip('"\'')
destination_folder = destination_folder.strip('"\'')
operation = input("请选择操作(输入 'copy' 进行复制,输入 'move' 进行移动): ").strip().lower()
if operation not in ['copy', 'move']:
print("输入的操作无效,请输入 'copy' 或 'move'。")
elif os.path.exists(source_folder):
print("开始查找并处理文件...")
find_and_copy_files(source_folder, destination_folder, operation)
print("文件处理完成。")
else:
print("源文件夹路径不存在,请检查后重新输入。")
input("按回车键退出程序...")
《棕色尘埃2-冒汗心跳的RPG》PC端资产整理为可读名称工具
能根据清单列表把.bundle文件还原为可读文件名或文件及其目录结构,并以版本号为输出目录或指定目录下输出文件的父目录。
bd2.zip (26.0 KB)