nutaku似乎在搞夏促
和日本朋友交流的时候看了一眼活动海报似乎就是E服的前线

找了一圈似乎没有这方面的信息
游戏url
https://www.nutaku.net/zh/games/dolls-division/
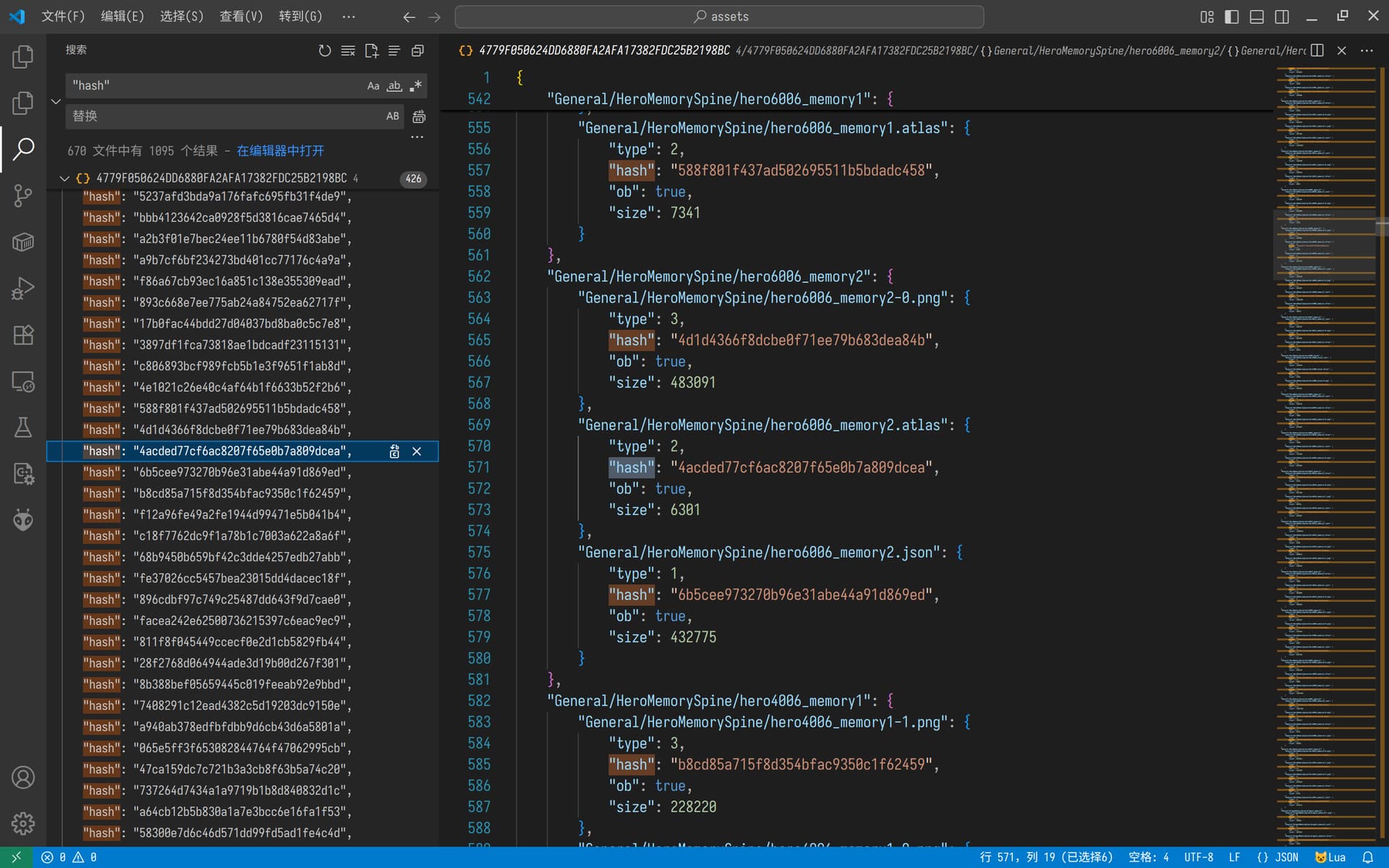
其文件名似乎为SHA-1加密,并使用文件名第一个字节作为文件夹来分区文件
看样子是cocos的引擎但是不知道文件名是如何加密的望大佬指点
SHA-1毕竟是哈希解密后只能通过审计lua代码分析文件结构来获取文件
nutaku似乎在搞夏促
和日本朋友交流的时候看了一眼活动海报似乎就是E服的前线
找了一圈似乎没有这方面的信息
游戏url
https://www.nutaku.net/zh/games/dolls-division/
其文件名似乎为SHA-1加密,并使用文件名第一个字节作为文件夹来分区文件
看样子是cocos的引擎但是不知道文件名是如何加密的望大佬指点
SHA-1毕竟是哈希解密后只能通过审计lua代码分析文件结构来获取文件
E服文件有加密,蹲个大佬解密
为啥都喜欢玩这种一眼ai的呢。。
import itertools
SIGN = b'zbobv1'
def ror(value, n):
n %= 8
return ((value >> n) | (value << (8 - n))) & 0xFF
def dec(data: bytearray) -> bytes:
if not data.endswith(SIGN):
print("不是加密文件")
return bytes(data)
dec = [
ror(data_byte ^ key_byte, key_index + 1)
for data_byte, (key_index, key_byte) in zip(data[:-len(SIGN)], itertools.cycle(enumerate(bytes([0x78, 0x21, 0x7A, 0x40, 0x6F, 0x23, 0x62, 0x24]))))
]
return bytes(dec)
if __name__ == "__main__":
with open("0046B30E6E60FC3F0046594BBF8AAD61FA3884C2", 'rb') as f:
enc = bytearray(f.read())
with open("dec.png", 'wb') as f:
f.write(dec(enc))
估计日本那边日法问题吧。。。没几个没码的
话说大佬文件名怎么得到的
我看sub_1377E9C似乎是一个哈希算法(nutaku arm64-v8a\libMyGame.so)
分析逻辑是他在加载图片时候会输出 TextureCache addImage path
字符串交叉引用找到sub_28D35DC
调用sub_28D57FC后再调用sub_1377E9C
文件名应该就是"extra_res3.json"加密后就是那个文件名
不过我看了一圈好像没找到啥函数
全是
(*(void (__fastcall **)(_QWORD *__return_ptr, __int64, _BYTE *))
这样的麻了
之前看到加密也想试试,但是函数名一坨也没搜到啥就没再看了 ![]()
d-miracle
大佬回了
from xxhash import xxh32
from hashlib import md5 as cmd5
def Get_Hash_Name(string: str) -> str:
b = string.encode()
s = xxh32(b).hexdigest() + cmd5(b).hexdigest()
return s.upper()
print(Get_Hash_Name('General/HeroSpine/hero1001.atlas'))
可以先
from xxhash import xxh32
from hashlib import md5 as cmd5
def Get_Hash_Name(string: str) -> str:
b = string.encode()
s = xxh32(b).hexdigest() + cmd5(b).hexdigest()
return s.upper()
print(Get_Hash_Name('extra_res3.json'))#4779F050624DD6880FA2AFA17382FDC25B2198BC
得到那个资源清单再生成加密文件名匹配文件解密输出
资源下载部分晚点用取证设备去抓似乎cocos的部分游戏流量不走系统代理
目前只能还原HCG文件名其他的还需要等审计完代码,或者笨办法遍历所有符合xml格式的文件(思路)
import os
import shutil
from xxhash import xxh32
from hashlib import md5 as cmd5
import itertools
import requests
import json
useproxy = proxyaddr = 0
def hjqxdownloader(overwrite):
def Get_Hash_Name(string: str) -> str:
b = string.encode()
s = xxh32(b).hexdigest() + cmd5(b).hexdigest()
return s.upper()
SIGN = b'zbobv1'
def ror(value, n):
n %= 8
return ((value >> n) | (value << (8 - n))) & 0xFF
def dec(data: bytearray) -> bytes:
if not data.endswith(SIGN):
return bytes(data)
return bytes([
ror(data_byte ^ key_byte, key_index + 1)
for data_byte, (key_index, key_byte) in zip(
data[:-len(SIGN)],
itertools.cycle(enumerate(bytes([0x78, 0x21, 0x7A, 0x40, 0x6F, 0x23, 0x62, 0x24])))
)
])
def decrypt_file(filepath):
try:
with open(filepath, 'rb') as f:
data = bytearray(f.read())
return dec(data)
except Exception as e:
print(f"读取或解密失败: {filepath},错误: {e}")
return None
def decrypt_folder(root_folder):
for root, dirs, files in os.walk(root_folder):
for file in files:
full_path = os.path.join(root, file)
try:
with open(full_path, 'rb') as f:
data = bytearray(f.read())
new_data = dec(data)
if new_data != data:
with open(full_path, 'wb') as f:
f.write(new_data)
print(f"已解密: {full_path}")
else:
print(f"跳过未加密文件: {full_path}")
except Exception as e:
print(f"处理文件失败: {full_path},错误:{e}")
manifest_url = "https://cdn.tpwslzp.xyz/images/download_res/Android/proj.manifest"
response = requests.get(manifest_url)
response.raise_for_status()
manifest = response.json()
base_url = manifest.get("packageUrl", "https://cdn.tpwslzp.xyz/images/download_res/Android/")
assets = manifest.get("assets", {})
lines = []
for path in assets:
filename = path.split('/')[-1]
full_url = base_url + path
if (not os.path.exists(os.path.join("resdownload", "dolls-division", "download", filename))) or overwrite:
lines.append(f"{full_url}\n out=download/{filename}")
with open("dolls-division.txt", "w", encoding="utf-8") as f:
f.write("\n".join(lines))
print("主资源链接已写入 dolls-division.txt")
os.system(f"aria2c -i dolls-division.txt -j 32 -s 16 -x 16 --auto-file-renaming=false {f'{proxyaddr} ' if useproxy else ''}{'--allow-overwrite=true ' if overwrite else ''}--check-certificate=false --dir=resdownload/dolls-division")
filelistname = Get_Hash_Name('extra_res3.json')
filelistpath = f"resdownload/dolls-division/download/{filelistname}"
if not os.path.exists(filelistpath):
print(f"未找到 extra_res3.json 加密文件: {filelistpath}")
return
raw_data = decrypt_file(filelistpath)
if raw_data is None:
print("extra_res3.json 解密失败")
return
try:
filelistdata = json.loads(raw_data)
except Exception as e:
print(f"extra_res3.json 解析失败: {e}")
return
extra_lines = []
for group_path, files in filelistdata.items():
for filepath in files:
hashed = Get_Hash_Name(filepath)
local_path = os.path.join("resdownload", "dolls-division", "download", hashed)
if not os.path.exists(local_path):
print(f"未找到源文件: {local_path}")
subfolder = hashed[0]
extra_url = f"https://cdn.tpwslzp.xyz/images/extra_res/Android/{subfolder}/{hashed}"
extra_lines.append(f"{extra_url}\n out=download/{hashed}")
else:
print(f"{filepath} -> {hashed}")
if extra_lines:
with open("dolls-division.txt", "w", encoding="utf-8") as f:
f.write("\n" + "\n".join(extra_lines))
print("已追加 extra_res 链接到 dolls-division.txt")
os.system(f"aria2c -i dolls-division.txt -j 32 -s 16 -x 16 --auto-file-renaming=false {f'{proxyaddr} ' if useproxy else ''}{'--allow-overwrite=true ' if overwrite else ''}--check-certificate=false --dir=resdownload/dolls-division")
decrypt_folder("resdownload/dolls-division/download")
for group_path, files in filelistdata.items():
for filepath in files:
hashed = Get_Hash_Name(filepath)
source = os.path.join("resdownload", "dolls-division", "download", hashed)
target = os.path.join("resdownload", "dolls-division", "output", filepath)
if os.path.exists(source):
os.makedirs(os.path.dirname(target), exist_ok=True)
shutil.copy2(source, target)
print(f"[cp]{filepath} -> {hashed}")
else:
print(f"[缺失]{filepath} -> {hashed}")
hjqxdownloader(0)
在整理一些资源的时候发现
也是这个加密
顺手分析了一下这个文件清单中只有Hcg没有HSkin
Hskin似乎有个plist清单文件名是 228078592606C113F5773797E81728289165E136
审计lua代码没有发现拼接路径的代码很怪,目前skin的命名逻辑为
General/HeroSpine/xxx_clothes_1.atlas
如
General/HeroSpine/general_503_clothes_1.atlas
General/HeroSpine/xxx_clothes_1-x.png
如
General/HeroSpine/general_503_clothes_1-0.png
但似乎找不到json
回头再分析一下 Dolls Division / 浩劫前线 应该也有这种资源
然后写了一个脚本用于识别atlas中所有文件贴图名字判断所有符合spine的json格式文件(其实就是文本搜索)中是否只包含这些文件
import os
import json
import re
json_root = r"D:\mmp\resdownloader\resdownload\thrones-and-beauties\download"
atlas_path = r"D:\mmp\resdownloader\resdownload\thrones-and-beauties\download\367AA0D9D6B98953EA14E4EC921032F1217B1769"
def extract_atlas_names(atlas_file):
atlas_names = set()
with open(atlas_file, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if line and not line.endswith(".png") and ":" not in line:
atlas_names.add(line)
return atlas_names
def find_spine_files(root_dir):
spine_files = []
for dirpath, _, filenames in os.walk(root_dir):
for filename in filenames:
file_path = os.path.join(dirpath, filename)
try:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
if '"spine":' in content:
spine_files.append(file_path)
except UnicodeDecodeError:
# 跳过二进制文件似乎大幅提升速度
continue
return spine_files
def check_slots(file_path, atlas_names):
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
slots = data.get("slots", [])
slot_names = {slot.get("name") for slot in slots if "name" in slot}
not_in_atlas = slot_names - atlas_names
return not_in_atlas
if __name__ == "__main__":
atlas_names = extract_atlas_names(atlas_path)
print(f"[Atlas资源名] 共 {len(atlas_names)} 个: {atlas_names}")
spine_files = find_spine_files(json_root)
print(f"[含spine文件] 共 {len(spine_files)} 个")
for file_path in spine_files:
try:
not_found = check_slots(file_path, atlas_names)
if not not_found:
print(f"{file_path} 全部资源匹配")
except Exception as e:
print(f"解析失败 {file_path}: {e}")
为便于各位佬分析这里提供一下下载器的源码
import os
import shutil
from xxhash import xxh32
from hashlib import md5 as cmd5
import itertools
import requests
import json
proxyaddr = useproxy = 0
def zgzddownloader(overwrite):
def Get_Hash_Name(string: str) -> str:
b = string.encode()
s = xxh32(b).hexdigest() + cmd5(b).hexdigest()
return s.upper()
SIGN = b'zbobv1'
def ror(value, n):
n %= 8
return ((value >> n) | (value << (8 - n))) & 0xFF
def dec(data: bytearray) -> bytes:
if not data.endswith(SIGN):
return bytes(data)
return bytes([
ror(data_byte ^ key_byte, key_index + 1)
for data_byte, (key_index, key_byte) in zip(
data[:-len(SIGN)],
itertools.cycle(enumerate(bytes([0x78, 0x21, 0x7A, 0x40, 0x6F, 0x23, 0x62, 0x24])))
)
])
def decrypt_file(filepath):
try:
with open(filepath, 'rb') as f:
data = bytearray(f.read())
return dec(data)
except Exception as e:
print(f"读取或解密失败: {filepath},错误: {e}")
return None
def decrypt_folder(root_folder):
for root, dirs, files in os.walk(root_folder):
for file in files:
full_path = os.path.join(root, file)
try:
with open(full_path, 'rb') as f:
data = bytearray(f.read())
new_data = dec(data)
if new_data != data:
with open(full_path, 'wb') as f:
f.write(new_data)
print(f"已解密: {full_path}")
else:
print(f"跳过未加密文件: {full_path}")
except Exception as e:
print(f"处理文件失败: {full_path},错误:{e}")
manifest_url = "https://cdn.gamezdjsmr.net/images/download_res/Android/proj.manifest"
response = requests.get(manifest_url)
response.raise_for_status()
manifest = response.json()
base_url = manifest.get("packageUrl", "https://cdn.gamezdjsmr.net/images/download_res/Android/")
assets = manifest.get("assets", {})
lines = []
for path in assets:
filename = path.split('/')[-1]
full_url = base_url + path
if (not os.path.exists(os.path.join("resdownload", "thrones-and-beauties", "download", filename))) or overwrite:
lines.append(f"{full_url}\n out=download/{filename}")
with open("thrones-and-beauties.txt", "w", encoding="utf-8") as f:
f.write("\n".join(lines))
print("主资源链接已写入 thrones-and-beauties.txt")
os.system(f"aria2c -i thrones-and-beauties.txt -j 32 -s 16 -x 16 --auto-file-renaming=false {f'{proxyaddr} ' if useproxy else ''}{'--allow-overwrite=true ' if overwrite else ''}--check-certificate=false --dir=resdownload/thrones-and-beauties")
filelistname = Get_Hash_Name('extra_res3.json')
filelistpath = f"resdownload/thrones-and-beauties/download/{filelistname}"
if not os.path.exists(filelistpath):
print(f"未找到 extra_res3.json 加密文件: {filelistpath}")
return
raw_data = decrypt_file(filelistpath)
if raw_data is None:
print("extra_res3.json 解密失败")
return
try:
filelistdata = json.loads(raw_data)
except Exception as e:
print(f"extra_res3.json 解析失败: {e}")
return
extra_lines = []
for group_path, files in filelistdata.items():
for filepath in files:
hashed = Get_Hash_Name(filepath)
local_path = os.path.join("resdownload", "thrones-and-beauties", "download", hashed)
if not os.path.exists(local_path):
print(f"未找到源文件: {local_path}")
subfolder = hashed[0]
extra_url = f"https://cdn.gamezdjsmr.net/images/extra_res/Android/{subfolder}/{hashed}"
extra_lines.append(f"{extra_url}\n out=download/{hashed}")
else:
print(f"{filepath} -> {hashed}")
if extra_lines:
with open("thrones-and-beauties.txt", "w", encoding="utf-8") as f:
f.write("\n" + "\n".join(extra_lines))
print("已追加 extra_res 链接到 thrones-and-beauties.txt")
os.system(f"aria2c -i thrones-and-beauties.txt -j 32 -s 16 -x 16 --auto-file-renaming=false {f'{proxyaddr} ' if useproxy else ''}{'--allow-overwrite=true ' if overwrite else ''}--check-certificate=false --dir=resdownload/thrones-and-beauties")
decrypt_folder("resdownload/thrones-and-beauties/download")
for group_path, files in filelistdata.items():
for filepath in files:
hashed = Get_Hash_Name(filepath)
source = os.path.join("resdownload", "thrones-and-beauties", "download", hashed)
target = os.path.join("resdownload", "thrones-and-beauties", "output", filepath)
if os.path.exists(source):
if (not os.path.exists(target)) or overwrite:
os.makedirs(os.path.dirname(target), exist_ok=True)
shutil.copy2(source, target)
print(f"[cp]{filepath} -> {hashed}")
else:
print(f"[缺失]{filepath} -> {hashed}")
zgzddownloader(0)
以多个atlas文件中的png名去加密,和资源比较,没找到匹配的,猜测hcg加密与spine的不同,
完全看不懂你在说什么。。。
这个脚本有多处bug其实
slots里插槽可能是嵌套的反正只能说仅供参考
大佬,关于这个游戏的角色建模和皮肤解包,您后续有进展吗