ミストトレインガールズ〜霧の世界の車窓から〜 X - FANZA GAMES
抓了好几次。
https://assets4.mist-train-girls.com/production-client-web/254/src/settings.js
这里面有小人立绘
url类似于
。
不过据观察角色立绘等都不在里面,在哪里也一直没找到。
角色的url类似于
CG的url类似于
timestamp只能确定20250701是年月日,1500没变过。
不知道有没有大佬见过这种的?
ミストトレインガールズ〜霧の世界の車窓から〜 X - FANZA GAMES
抓了好几次。
https://assets4.mist-train-girls.com/production-client-web/254/src/settings.js
这里面有小人立绘
url类似于
。
不过据观察角色立绘等都不在里面,在哪里也一直没找到。
角色的url类似于
CG的url类似于
timestamp只能确定20250701是年月日,1500没变过。
不知道有没有大佬见过这种的?
https://assets4.mist-train-girls.com/production-client-web/255/src/settings.js
https://assets4.mist-train-girls.com/production-client-web/255/src/project.js
cocos2djs这是uuid列表
不过他不是json而是直接写入了js
不过我也没看懂他packedAssets节点里的文件怎么加载的(就是没见过bushi
下载安卓版本或者pc, 这2个版本用的unity, 它只有网页端用的是c2d
安卓端清单应该就是
不过好像加密了。
没加密, 它只是brotli压缩
是我见的太少了。
上面两个好像只是CG的资源文件。
上面抓到的都是CG的资源清单。
这边提供一个提取CGurl的py
import os
import json
import re
def extract_bundle_urls():
# 配置参数
search_str = "catalog_ex_hd"
target_key = "m_InternalIds"
bundle_suffix = ".bundle"
url_prefix_base = "https://native-assets3.mist-train-girls.com/production-assets/SavedAssets/Exe/Adult/{version}/adult_spine_stills_assets_spine/"
output_file = "output.txt"
# 存储所有提取的URL
all_urls = []
# 获取当前目录下所有包含指定字符串的JSON文件
for filename in os.listdir('.'):
if (search_str in filename) and filename.endswith('.json'):
print(f"处理文件: {filename}")
# 提取版本号(匹配catalog_ex_hd_后的字符串,直到.json前)
version_match = re.search(f'{search_str}_(.*)\.json', filename)
if not version_match:
print(f"警告: {filename} 文件名格式不符合要求,无法提取版本号,已跳过")
continue
version = version_match.group(1)
url_prefix = url_prefix_base.format(version=version)
try:
# 读取JSON文件
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
# 检查是否包含目标键
if target_key in data and isinstance(data[target_key], list):
# 提取包含.bundle的字符串
for item in data[target_key]:
if bundle_suffix in item:
# 去除'/'前包括'/'的字符
if '/' in item:
bundle_name = item.split('/')[-1]
# 生成完整URL
full_url = url_prefix + bundle_name
all_urls.append(full_url)
except json.JSONDecodeError:
print(f"警告: {filename} 不是有效的JSON文件,已跳过")
except Exception as e:
print(f"处理 {filename} 时出错: {str(e)}")
# 将结果写入输出文件
with open(output_file, 'w', encoding='utf-8') as f:
for url in all_urls:
f.write(url + '\n')
print(f"处理完成,共提取 {len(all_urls)} 个URL,已保存到 {output_file}")
if __name__ == "__main__":
extract_bundle_urls()
目前不知道角色立绘在哪。
文本有鉴权。
666这不是迷雾列车少女吗 ![]()
DMM web版本
這個我是用暴力破解方式,他的清單不好找
但URL很有規則所以好破
[角色編號]=1~248 (當時挖的時候只有到248,剛剛測有249)
[進化]=2~4 (我猜測應該是角色進化星數什麼的,暫稱進化)
[固定數字]=105、107、205、207、305、307
[進化跟固定數字可能有其他值]
以34為例大概會這樣
Spines/Stills/34/23420105/still_configuration.json
Spines/Stills/34/23430105/still_configuration.json
Spines/Stills/34/23440105/still_configuration.json
Spines/Stills/34/23440107/still_configuration.json
Spines/Stills/34/23440205/still_configuration.json
Spines/Stills/34/23440207/still_configuration.json
Spines/Stills/34/23440305/still_configuration.json
Spines/Stills/34/23440307/still_configuration.json
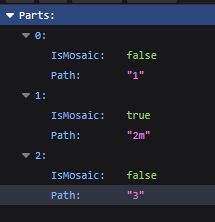
再將其組合出
https:// assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/34/23420105/1.png
https:// assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/34/23420105/1.atlas
https:// assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/34/23420105/1.skel
https:// assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/34/23420105/2m.png
https:// assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/34/23420105/2m.atlas
https:// assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/34/23420105/2m.skel
https:// assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/34/23420105/3.png
https:// assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/34/23420105/3.atlas
https:// assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/34/23420105/3.skel
光上面挖出來就高達9GB 可見量之多
這是我暴力破解挖到的1~248角色URL
205+207我少用out=去分類,在自己補上out=吧,不然下載會全塞再一起
still URL.rar (97.9 KB)
文件名错了。
web版 png是直接抓取
unity解出來的png 檔案較小
我暴力挖的版本可能有缺
或許可以用安卓版本數字清單去填成web版本URL
import os
import json
import re
def extract_still_config_urls():
# 配置参数
search_str = "catalog_ex_hd"
target_key = "m_InternalIdPrefixes"
start_str = "Assets"
url_prefix_base = "https://assets4.mist-train-girls.com/production-client-web-assets/Spines/Stills/{character}/{number}/still_configuration.json"
output_file = "output_still_configuration.txt"
# 存储所有提取的URL
all_urls = []
# 获取当前目录下所有包含指定字符串的JSON文件
for filename in os.listdir('.'):
if (search_str in filename) and filename.endswith('.json'):
print(f"处理文件: {filename}")
try:
# 读取JSON文件
with open(filename, 'r', encoding='utf-8') as f:
data = json.load(f)
# 检查是否包含目标键且为列表
if target_key in data and isinstance(data[target_key], list):
# 提取以Assets开头的字符串
for item in data[target_key]:
if isinstance(item, str) and item.startswith(start_str):
# 按'/'分割路径
path_parts = item.split('/')
# 确保路径至少有足够的部分(倒数第二个和最后一个)
if len(path_parts) >= 2:
# 如果倒数第二个部分是"Main",则改为0
character = path_parts[-2] if path_parts[-2] != "Main" else "0"
number = path_parts[-1]
# 生成完整URL
full_url = url_prefix_base.format(character=character, number=number)
all_urls.append(full_url)
except json.JSONDecodeError:
print(f"警告: {filename} 不是有效的JSON文件,已跳过")
except Exception as e:
print(f"处理 {filename} 时出错: {str(e)}")
# 将结果写入输出文件
with open(output_file, 'w', encoding='utf-8') as f:
for url in all_urls:
f.write(url + '\n')
print(f"处理完成,共提取 {len(all_urls)} 个URL,已保存到 {output_file}")
if __name__ == "__main__":
extract_still_config_urls()
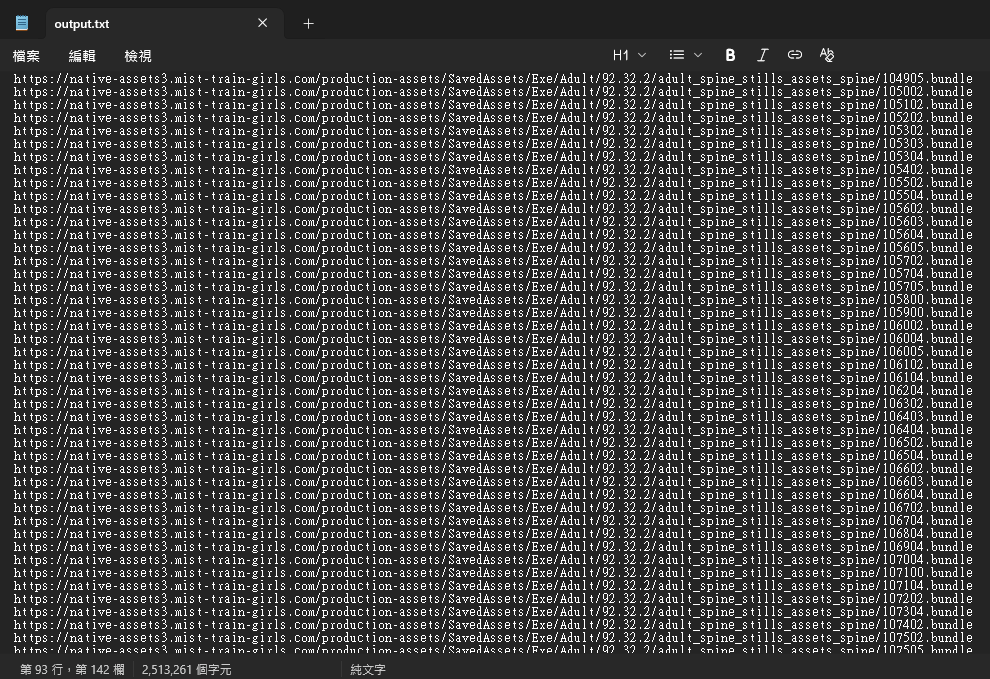
可以提取出still_configuration.json的url。有4个失败了,与其他url格式不同。

{kind=link}
{kind=link}
{kind=link}
{kind=link}