def zzmwdownloader(overwrite):
VALID_SUFFIXES = ('.basis', '.json', '.atlas.txt')
DOWNLOAD_DIR = "resdownload/转职魔王X"
TEMP_DIR = os.path.join(DOWNLOAD_DIR, "temp")
BASISU_EXE = "basisu.exe"
os.makedirs(DOWNLOAD_DIR, exist_ok=True)
os.makedirs(TEMP_DIR, exist_ok=True)
file_map = {}
if not os.path.exists(BASISU_EXE):
print(f"请下载依赖{BASISU_EXE}")
newWin = Tk()
newWin.withdraw()
confirm = messagebox.askyesno("需要下载依赖", f"此功能依赖{BASISU_EXE}是否自动下载", parent=newWin)
newWin.destroy()
if confirm:
os.system(f"aria2c https://resdownload.7sec.fun/resdownloader/{BASISU_EXE}")
print("请重新运行此功能")
return
def get_game_url():
api_url = "https://game.ero-labs.gold/api/v2/cloud/136?lang=cn"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
response = requests.get(api_url, headers=headers)
response.raise_for_status()
data = response.json()
if data.get("status") == "SUCCESS" and data.get("data"):
cloud_connect_data = data["data"].get("cloudConnectData", [])
if cloud_connect_data:
game_url = cloud_connect_data[0].get("gameUrl")
if game_url:
return game_url.replace("/index/", "/game/")
except Exception as e:
print(f"获取游戏URL出错: {e}")
return None
def get_settings_js_url(game_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
response = requests.get(game_url, headers=headers)
response.raise_for_status()
manifest_pattern = r'<link rel="manifest" href="([^"]+manifest\.json)"'
settings_pattern = r'<script src="([^"]+__settings__\.js)"'
manifest_match = re.search(manifest_pattern, response.text)
settings_match = re.search(settings_pattern, response.text)
if settings_match:
return settings_match.group(1)
elif manifest_match:
# 如果不能直接找到settings.js,尝试从manifest URL推断
manifest_url = manifest_match.group(1)
base_url = manifest_url.split("/manifest.json")[0]
return f"{base_url}/__settings__.js"
except Exception as e:
print(f"获取settings.js URL出错: {e}")
return None
def get_cdn_prefix(settings_js_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
response = requests.get(settings_js_url, headers=headers)
response.raise_for_status()
asset_prefix_pattern = r'window\.ASSET_PREFIX\s*=\s*"([^"]+)"'
match = re.search(asset_prefix_pattern, response.text)
if match:
asset_prefix = match.group(1)
cdn_prefix = asset_prefix[:-1]
return cdn_prefix
except Exception as e:
print(f"获取CDN_PREFIX出错: {e}")
return None
def get_config_filename(settings_js_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
response = requests.get(settings_js_url, headers=headers)
response.raise_for_status()
config_pattern = r'window\.CONFIG_FILENAME\s*=\s*"([^"]+)"'
match = re.search(config_pattern, response.text)
if match:
return match.group(1)
except Exception as e:
print(f"获取CONFIG_FILENAME出错: {e}")
return None
def get_config_data(config_url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
response = requests.get(config_url, headers=headers)
response.raise_for_status()
return response.json()
except Exception as e:
print(f"获取config.json数据出错: {e}")
return None
def basis_to_png_threadsafe(basis_path):
basename = os.path.splitext(os.path.basename(basis_path))[0]
work_dir = os.path.join(TEMP_DIR, basename)
try:
os.makedirs(work_dir, exist_ok=True)
temp_basis_path = os.path.join(work_dir, os.path.basename(basis_path))
shutil.copy(basis_path, temp_basis_path)
result = subprocess.run(
[os.path.abspath(BASISU_EXE), "-file", os.path.basename(temp_basis_path)],
cwd=work_dir
)
if result.returncode != 0:
print(f"[!] basisu解码失败: {basis_path}")
return False
candidates = [
f"{basename}_unpacked_rgba_BC7_RGBA_0000.png"]
for png_file in candidates:
temp_png_path = os.path.join(work_dir, png_file)
if os.path.exists(temp_png_path):
final_png_path = os.path.join(DOWNLOAD_DIR, f"{basename}.png")
shutil.move(temp_png_path, final_png_path)
print(f"[+] 转换成功: {basis_path} → {final_png_path}")
return True
print(f"[!] 没找到有效PNG: {basis_path}")
return False
finally:
shutil.rmtree(work_dir, ignore_errors=True)
def clean_temp():
if os.path.exists(TEMP_DIR):
shutil.rmtree(TEMP_DIR)
print("[*] 已清理临时目录")
def getpngmain():
basis_files = [
os.path.join(DOWNLOAD_DIR, f)
for f in os.listdir(DOWNLOAD_DIR)
if f.endswith(".basis")
]
with ThreadPoolExecutor(max_workers=10) as executor:
future_to_path = {executor.submit(basis_to_png_threadsafe, path): path for path in basis_files}
for future in as_completed(future_to_path):
path = future_to_path[future]
try:
if future.result():
os.remove(path)
print(f"[+] 删除原文件: {path}")
except Exception as e:
print(f"[!] 处理失败 {path}: {e}")
clean_temp()
def organize_files_by_prefix(spine_prefixes):
for prefix in spine_prefixes:
folder_path = os.path.join(DOWNLOAD_DIR, prefix)
os.makedirs(folder_path, exist_ok=True)
for f in os.listdir(DOWNLOAD_DIR):
if f == prefix:
continue
if f.startswith(prefix) and os.path.isfile(os.path.join(DOWNLOAD_DIR, f)):
src = os.path.join(DOWNLOAD_DIR, f)
dst = os.path.join(folder_path, f)
shutil.move(src, dst)
print(f"[+] 移动: {f} → {folder_path}")
def rename_atlas_txt():
for f in os.listdir(DOWNLOAD_DIR):
if f.endswith(".atlas.txt"):
old_path = os.path.join(DOWNLOAD_DIR, f)
new_name = f[:-4]
new_path = os.path.join(DOWNLOAD_DIR, new_name)
os.rename(old_path, new_path)
print(f"[+] 重命名: {f} → {new_name}")
def mainload():
# 执行完整流程
game_url = get_game_url()
if not game_url:
print("无法获取游戏URL")
return
print(f"游戏URL: {game_url}")
settings_js_url = get_settings_js_url(game_url)
if not settings_js_url:
print("无法获取__settings__.js URL")
return
#print(f"获取到的__settings__.js URL: {settings_js_url}")
cdn_prefix = get_cdn_prefix(settings_js_url)
if not cdn_prefix:
print("无法获取CDN_PREFIX")
return
#print(f"获取到的CDN_PREFIX: {cdn_prefix}")
config_url = get_config_filename(settings_js_url)
if not config_url:
print("无法获取CONFIG_FILENAME")
return
print(f"config.json URL: {config_url}")
data = get_config_data(config_url)
if not data:
print("无法获取config.json数据")
return
assets = data.get("assets", {})
for asset_id, asset_info in assets.items():
file_info = asset_info.get("file")
if not file_info:
continue
url = None
filename = None
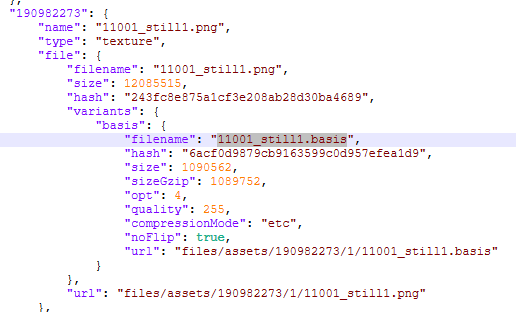
basis_variant = file_info.get("variants", {}).get("basis")
if basis_variant:
filename = basis_variant.get("filename")
url = basis_variant.get("url")
if not url or not filename:
filename = file_info.get("filename")
url = file_info.get("url")
if not filename or not url:
continue
if not filename.endswith(VALID_SUFFIXES):
continue
full_url = f"{cdn_prefix}/{url}" #cdn_prefix + url
print(full_url)
file_map[filename] = full_url
with open("zzmw.txt", "w", encoding="utf-8") as out_file:
for fname, url in file_map.items():
if fname.endswith(".json"):
out_file.write(f"{url}\n out={fname}\n\n")
os.system(f"aria2c -i zzmw.txt -j 16 -s 16 -x 16 --check-certificate=false --auto-file-renaming=false {f'{proxyaddr} ' if useproxy else ''}{'--allow-overwrite=true ' if overwrite else ''}--dir={DOWNLOAD_DIR}")
print("正在解析json...")
spine_prefixes = set()
for fname in os.listdir(DOWNLOAD_DIR):
if fname.endswith(".json"):
fpath = os.path.join(DOWNLOAD_DIR, fname)
try:
with open(fpath, "r", encoding="utf-8") as f:
j = json.load(f)
if "skeleton" in j and isinstance(j["skeleton"], dict) and "spine" in j["skeleton"]:
name_prefix = os.path.splitext(fname)[0]
spine_prefixes.add(name_prefix)
else:
os.remove(fpath)
except Exception:
os.remove(fpath)
with open("zzmw.txt", "w", encoding="utf-8") as out_file:
for fname, url in file_map.items():
if fname.endswith(".json"):
continue
for prefix in spine_prefixes:
if fname.startswith(prefix):
out_file.write(f"{url}\n out={fname}\n\n")
break
os.system(f"aria2c -i zzmw.txt -j 32 -s 16 -x 16 --check-certificate=false --auto-file-renaming=false {f'{proxyaddr} ' if useproxy else ''}{'--allow-overwrite=true ' if overwrite else ''}--dir={DOWNLOAD_DIR}")
getpngmain()
rename_atlas_txt()
organize_files_by_prefix(spine_prefixes)
mainload()
库自己补全一下
从下载器复制的源码
另外有些spine其实有无码资源有字样 调整用 的就是不过大部分没有
估计是spine可以控制附件是否导出员工没有给那几个附件取消导出
不过也说明确实存在为日本外地区设计的spine后续是否修改cg全看erolab。。。