由于总有人会问一些基础的问题,让人不想重复回答。所以可以把这个简单又不失优雅的扔过去,而省去无用的时间。还在更新中。
这篇文章尽量不涉及代码(所以不涉及逆向),让真正的小白也可以看懂,甚至十分有九分的了然于胸(因为我也是小白,就不班门弄斧了,仅仅抛砖引玉一下)。
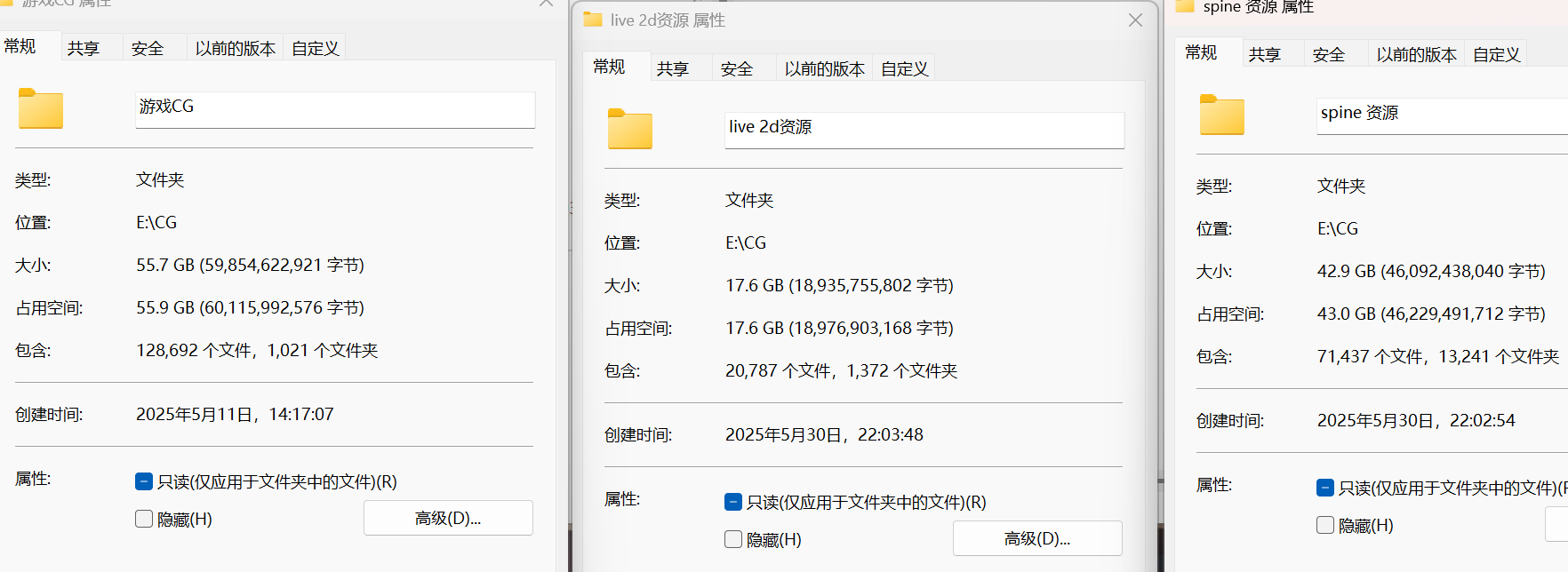
资源文件
存储地址
-
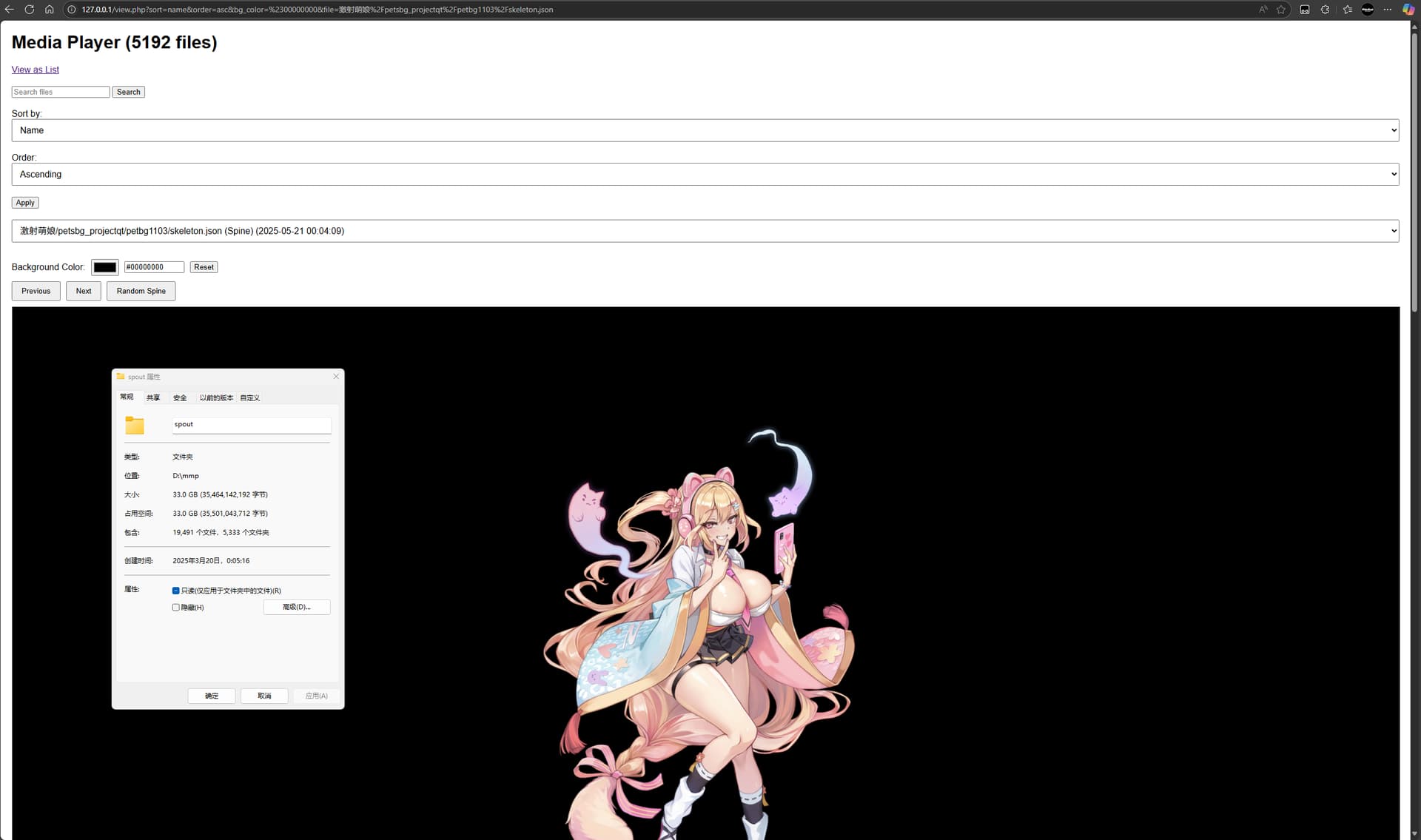
存储在Android/data/“包名”(使用自带的文件管理器或MT管理器即可查看)
-
存储在data/data/“包名”(这个需要root或者模拟器才能查看)
-
有些游戏热更新会在需要时才下载对应的资源文件,如果可以抓到文件清单且没有鉴权什么的就可以直接全部下载下来(这里不细讲)
数据结构
总言:文件有很多后缀,但判断文件类型往通过文件头尾判断。
如果不确定是什么文件,可以用十六进制(Hex)打开查看文件头确定,这里使用的工具是HxD,这在之后的解包工具有介绍。
.
1.unity资源文件的特征是文件头部有“UnityFS”标识头(后面跟版本号),这种可以被assetstudio读取。
如果不具有标识头且文本混乱,则可能加密。

.
2.zip格式文件具有“PK”文件头(还有其他地方也有标识,但是不好找)。
所以有时候别问为什么assetstudio无法读取,是你这就是个没后缀的压缩包而已。

.
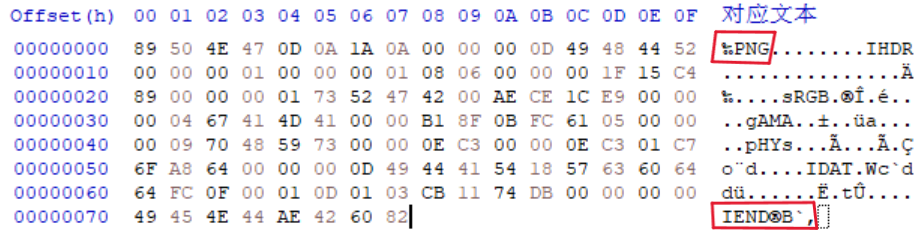
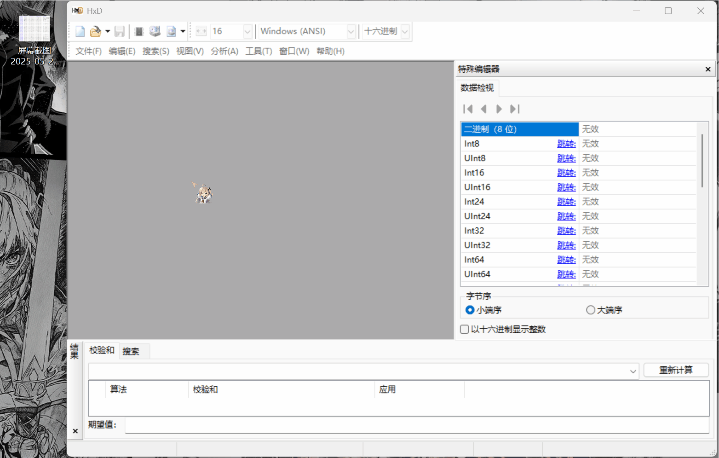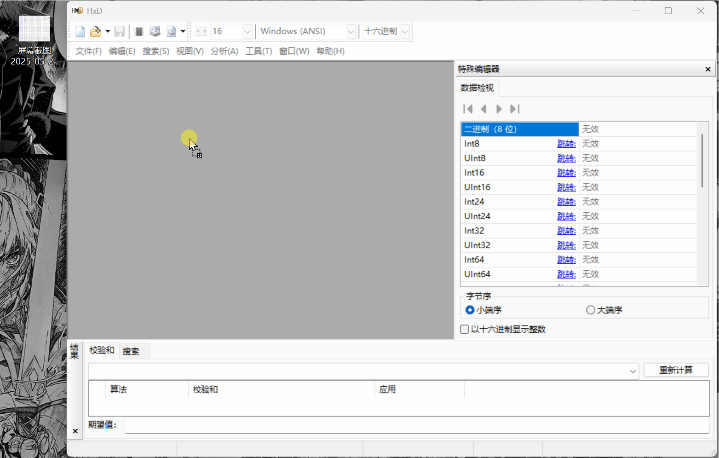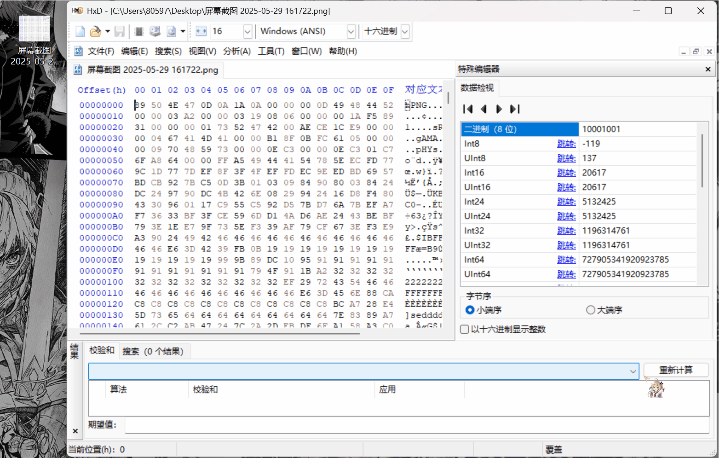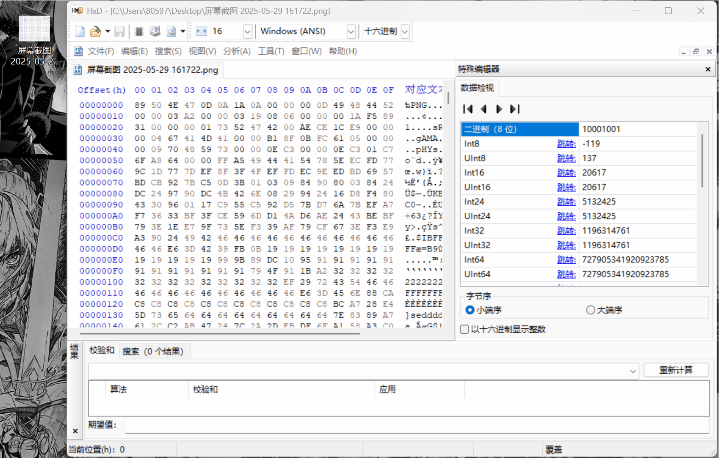
3.png格式图片具有“89 50 4E 47”文件头和“49 45 4E 44 AE 42 60 82”文件尾
.
4.cocos2d引擎的ccbi文件(这个没怎么解过,因为看着数据很少)
.
.
解包工具
assetstudio
版本&简介&下载地址
assetstudio是常用的用于解包未加密unity资源文件的工具,下面是对这几个版本的简介。
原版:味大无需多盐,可惜已经很久没有更新了,作者blog也停了。
团结引擎:顾名思义,支持untiy团结引擎的解包。
Raz版:支持一些加密方式的解密(unityCN,fakeheader),不过有点问题(有问题就换个版本assetstudio)。
aelurum版:支持自动检索导出一些正常的live2d文件。
简单使用
如果你的电脑比较杂鱼,请不要一次注入太多文件。
拆分文件夹文件.py
import os
import shutil
def split_files(source_folder, num_parts, operation):
# 获取源文件夹中的所有文件
files = [f for f in os.listdir(source_folder) if os.path.isfile(os.path.join(source_folder, f))]
if not files:
print("源文件夹中没有文件。")
return
# 计算每个部分应包含的文件数量
num_files = len(files)
files_per_part = num_files // num_parts
remainder = num_files % num_parts
start_index = 0
for i in range(num_parts):
# 创建新的文件夹
part_folder = os.path.join(source_folder, f"part_{i + 1}")
os.makedirs(part_folder, exist_ok=True)
print(f"正在创建文件夹: {part_folder}")
# 计算该部分应包含的文件数量
if i < remainder:
end_index = start_index + files_per_part + 1
else:
end_index = start_index + files_per_part
# 根据操作类型移动或复制文件到新文件夹
print(f"开始将文件{'移动' if operation == 'move' else '复制'}到 {part_folder}...")
for file in files[start_index:end_index]:
file_path = os.path.join(source_folder, file)
new_file_path = os.path.join(part_folder, file)
if operation == 'move':
shutil.move(file_path, new_file_path)
else:
shutil.copy(file_path, new_file_path)
print(f"已将 {file} {'移动' if operation == 'move' else '复制'}到 {part_folder}")
start_index = end_index
print(f"已完成将文件{'移动' if operation == 'move' else '复制'}到 {part_folder}")
if __name__ == "__main__":
source_folder = input("请输入源文件夹的地址: ")
# 去除多余的引号
source_folder = source_folder.strip('"\'')
num_parts = int(input("请输入要分成的份数: "))
operation = input("请选择操作类型(输入 'move' 进行移动,输入 'copy' 进行复制): ")
while operation not in ['move', 'copy']:
operation = input("输入无效,请重新输入操作类型(输入 'move' 进行移动,输入 'copy' 进行复制): ")
print("开始拆分文件...")
split_files(source_folder, num_parts, operation)
print("文件拆分完成。")
input("按回车键退出...")
1.导入文件:
直接将要解包的文件拖入即可。
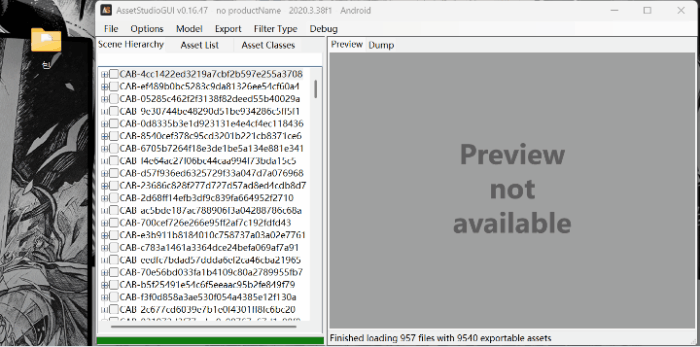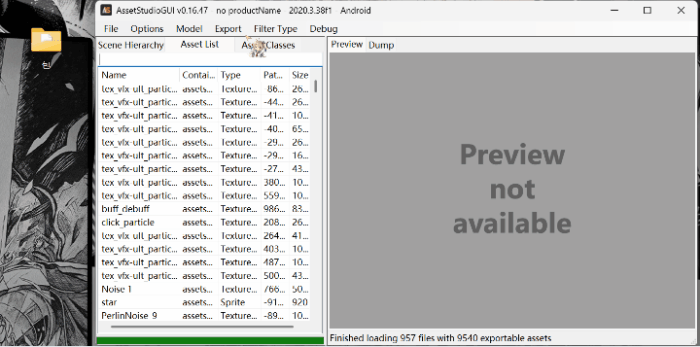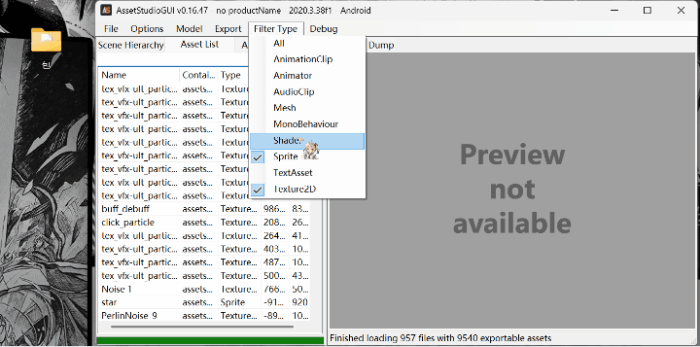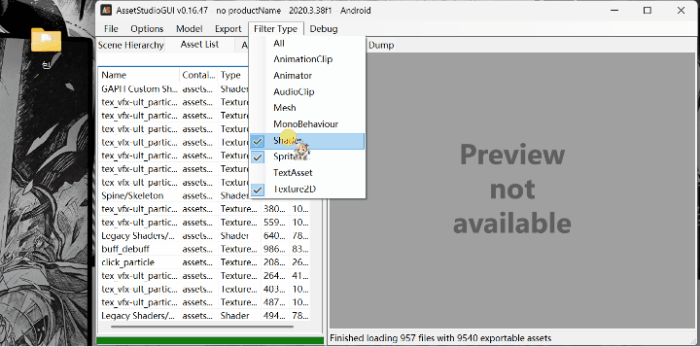
2.筛选文件:
点击asset list ; 点击filter type
3.导出文件:
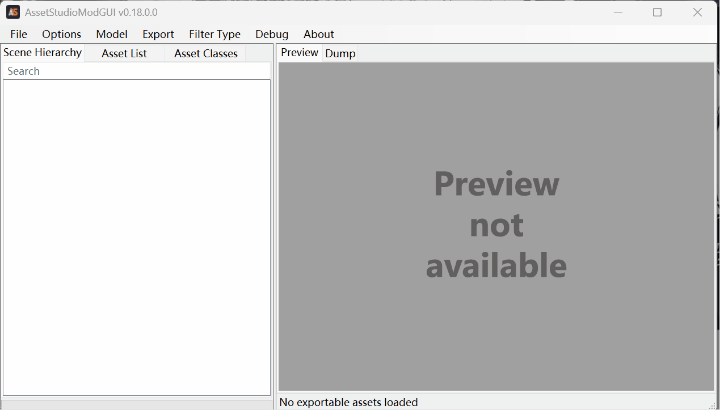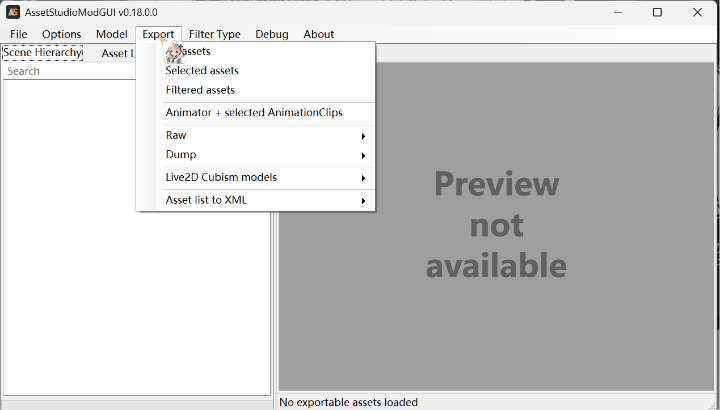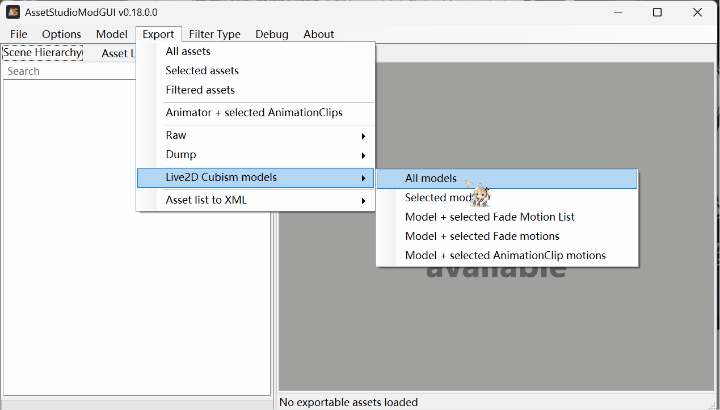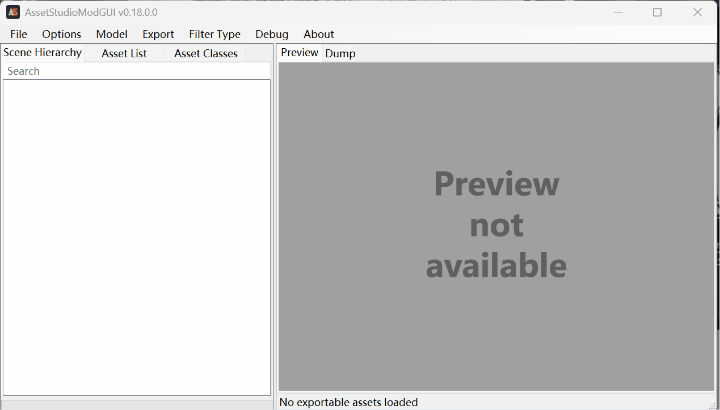
点击export ; 菜单中all asset是导出所有资源;slelected asset是导出选中的资源;filtered asset是导出筛选的资源。
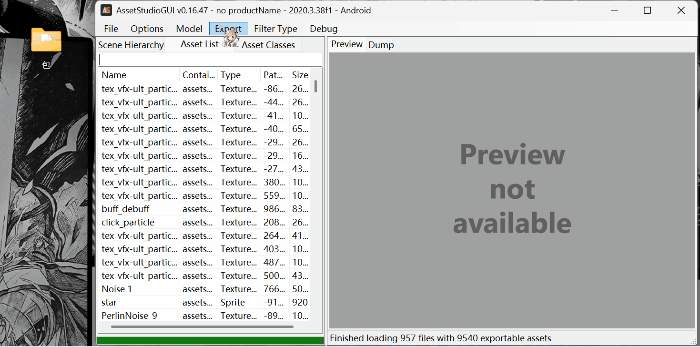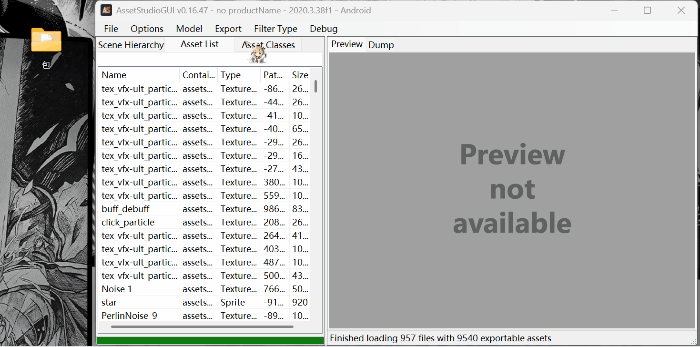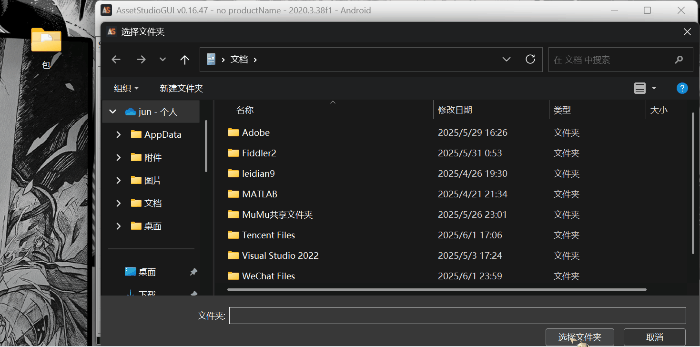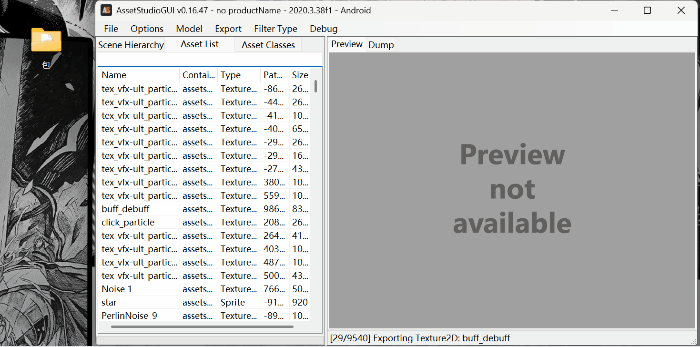
4.Raz版拓展:
支持个别解密。
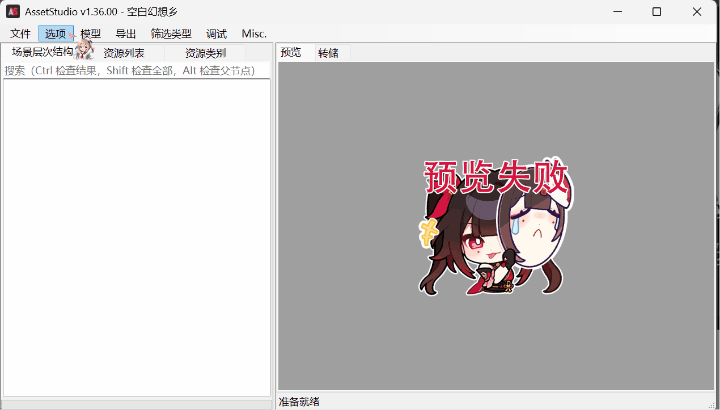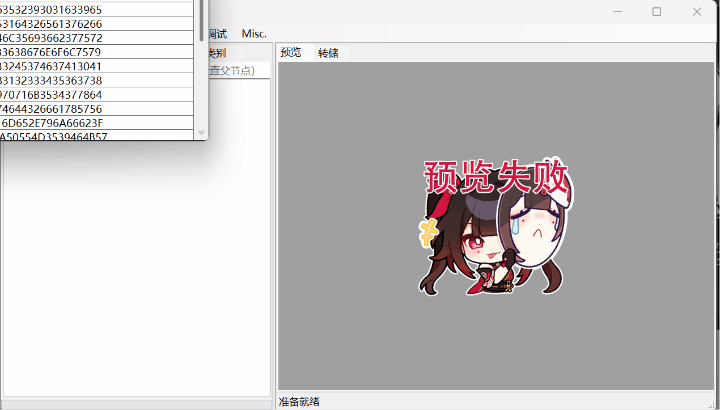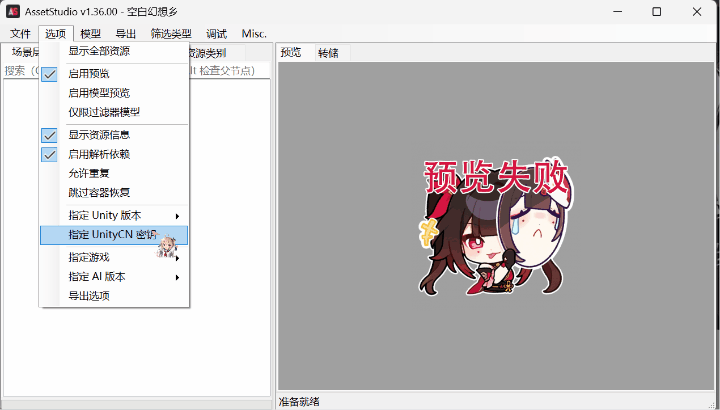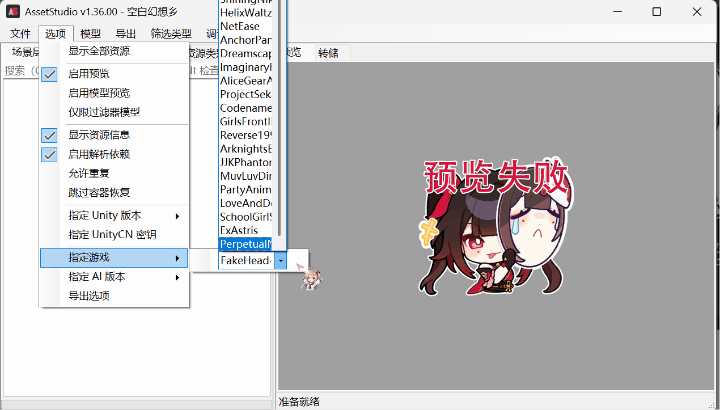
5.aelurum版拓展:
支持z自动检索正常live2d并导出。
.
Hxd(非必须)
简单使用
1.双击图标打开:
.
2.拖入文件即可查看:
.
3.字符串搜索:
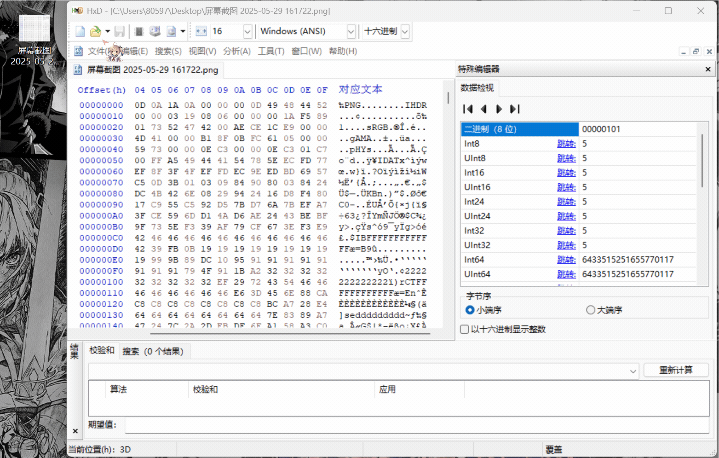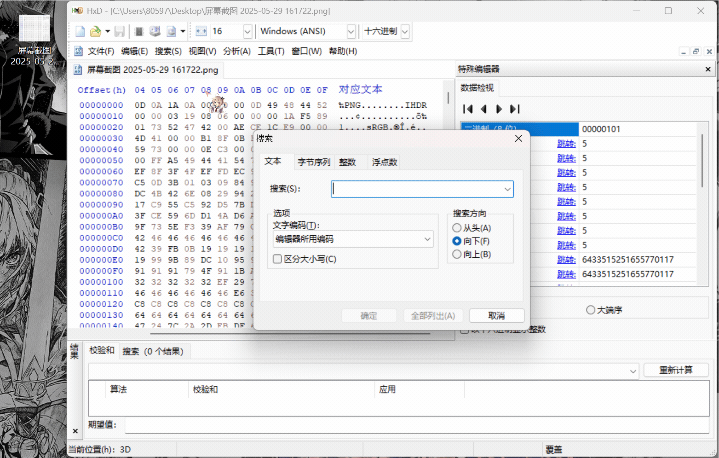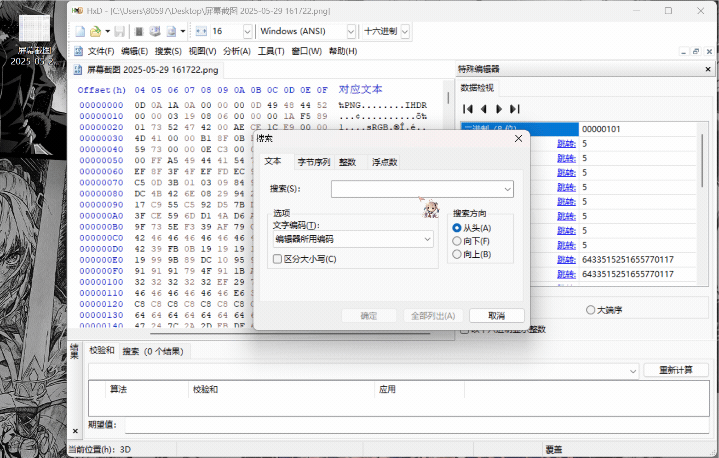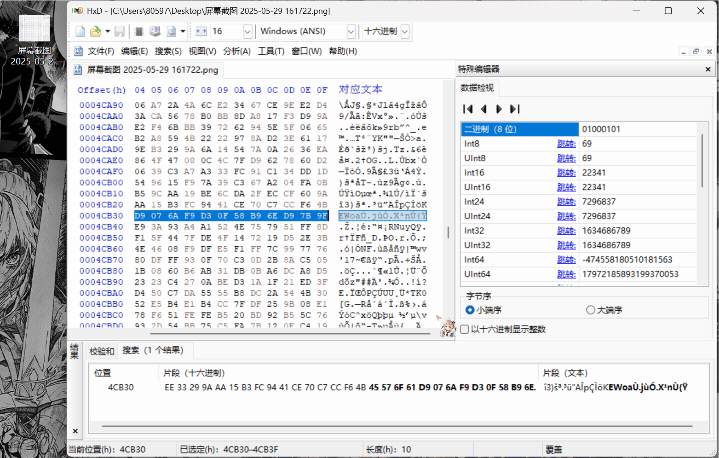
.
python环境(非必须)
主要用于方便地使用一些大佬给的批处理脚本(因为库的数量及配置方便程度也极其适用于小白使用)。
题外话:喜欢我c++抓毛的链接库吗,不过vs有vcpkg以后简单了很多。
教程的话网上很多,如果只是想用的话可以通过ai写一点简单的脚本。
ps:使用的话可以新建一个txt文件然后输入脚本再改后缀为py双击即可运行:

.
有些脚本会含有外部库,可以通过问ai来确定如何安装那些库,就pip install一下。
(示例: “代码”,此代码需要哪些外部库,如何安装。)
.
.
导出后的资源文件
spine模型
spine模型由三种文件构成:.skel或.json+.atlas+.png
(.skel或.json+.atlas同名,图片可能有多张)
skel和atlas在筛选的TextAsset类里一般同名,png 在Texture2D类里。
导出
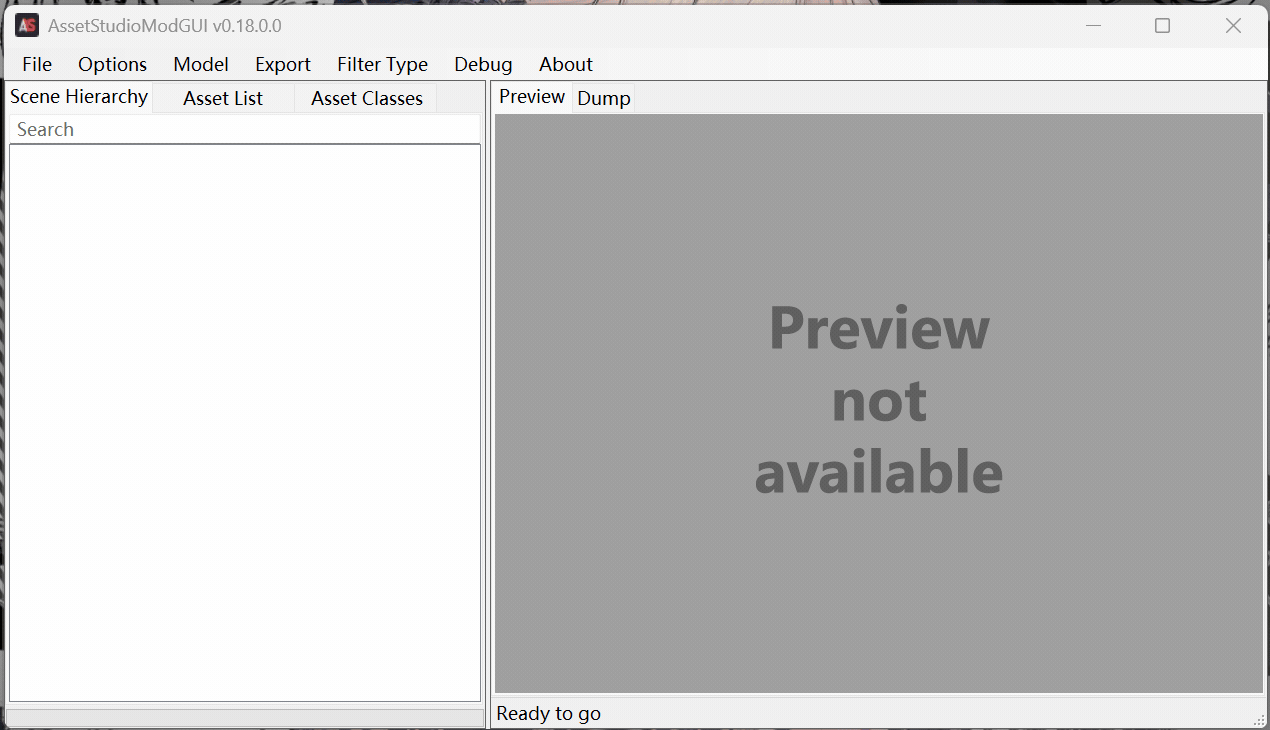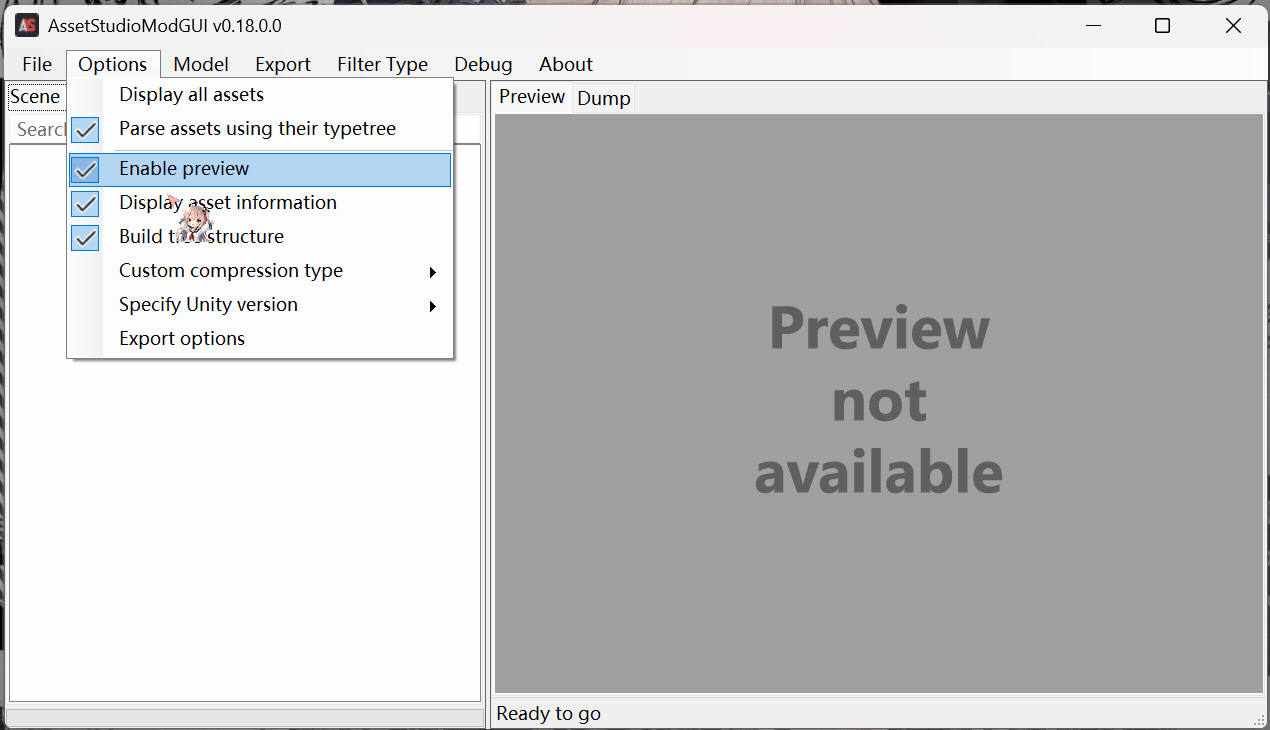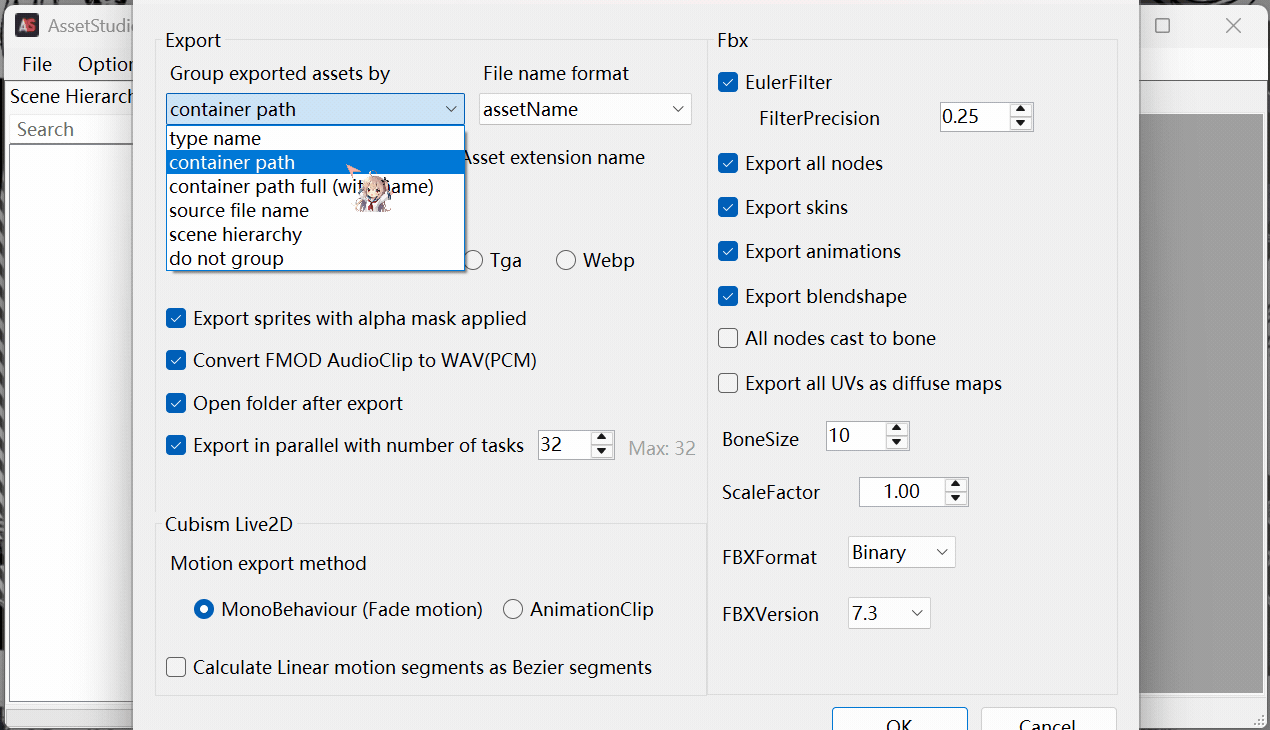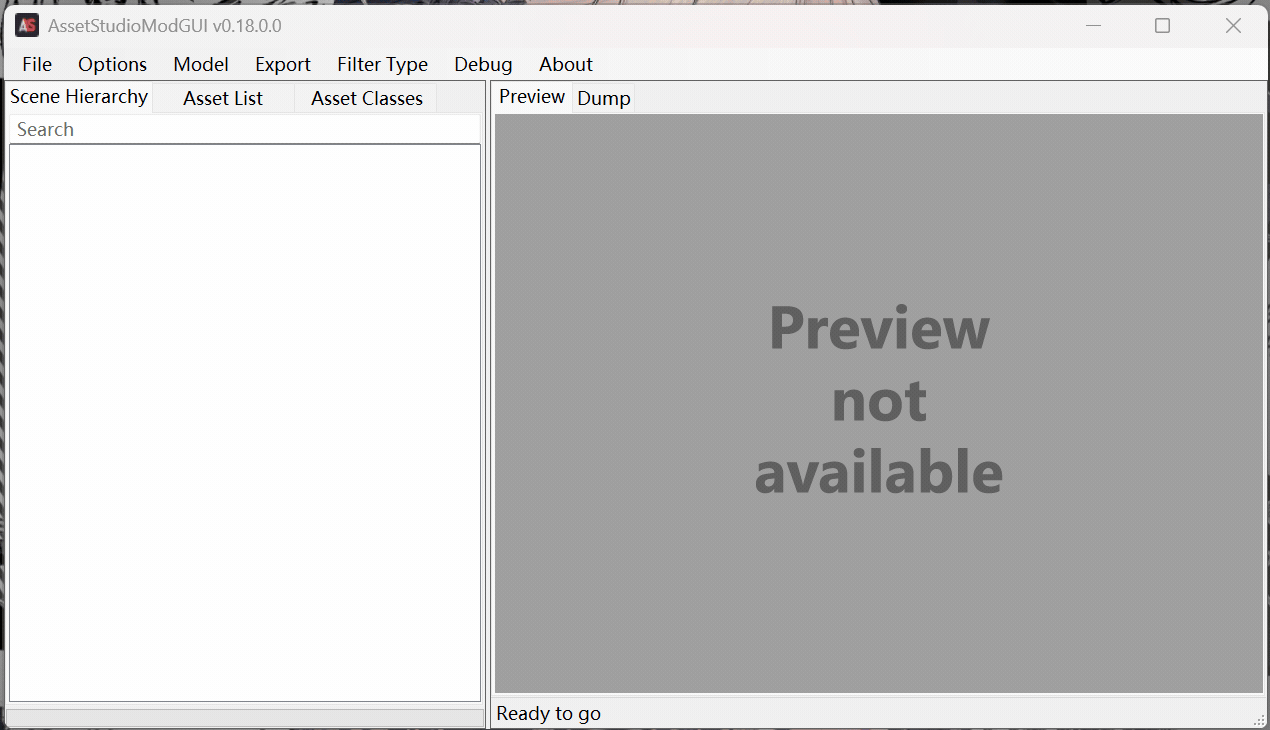
有的游戏spine模型都是同名的,导出会覆盖掉,可以按照容器路径导出:
.
导出后.skel/.json/.atlas普遍会具有.asset/.prefab后缀,可以用ai写个py批处理一下。
去除.skel/.atlas/.json文件后缀.py
import os
def has_suffix(filename, suffixes):
"""检查文件是否包含指定后缀(不区分大小写)"""
filename = filename.lower()
for suffix in suffixes:
if filename.endswith(suffix.lower()):
return True
return False
def process_file(file_path):
"""处理单个文件:删除.asset/.prefab后缀"""
try:
# 分离文件名和扩展名
base_name = os.path.basename(file_path)
if has_suffix(base_name, ('.asset', '.prefab')):
# 找到最后一个点的位置
dot_index = base_name.rfind('.')
if dot_index != -1:
new_base_name = base_name[:dot_index]
new_file_path = os.path.join(os.path.dirname(file_path), new_base_name)
# 执行重命名
os.rename(file_path, new_file_path)
print(f"重命名: {file_path} -> {new_file_path}")
except Exception as e:
print(f"处理文件 {file_path} 失败: {str(e)}")
def process_folder(folder_path):
"""递归处理文件夹"""
try:
print(f"开始处理文件夹: {folder_path}")
for root, _, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
process_file(file_path)
except Exception as e:
print(f"访问文件夹 {folder_path} 时出错: {str(e)}")
if __name__ == "__main__":
# 获取用户输入的文件夹路径
folder_path = input("请输入要处理的文件夹路径: ").strip()
# 去除首尾可能存在的引号
if (folder_path.startswith('"') and folder_path.endswith('"')) or (folder_path.startswith("'") and folder_path.endswith("'")):
folder_path = folder_path[1:-1]
# 使用原始字符串
folder_path = r"{}".format(folder_path)
# 检查路径是否存在
if not os.path.exists(folder_path):
print(f"错误:路径 {folder_path} 不存在!")
else:
process_folder(folder_path)
print("\n处理完成!")
input("按任意键退出控制台...")
加.json后缀.py
import os
def has_suffix(filename):
"""
检查文件是否有后缀
:param filename: 文件名
:return: 有后缀返回 True,否则返回 False
"""
return bool(os.path.splitext(filename)[1])
def process_folder(folder_path):
"""
处理文件夹,递归遍历子文件夹,为无后缀文件添加 .json 后缀
:param folder_path: 文件夹路径
"""
try:
print(f"开始处理文件夹: {folder_path}")
for root, _, files in os.walk(folder_path):
print(f"正在处理子文件夹: {root}")
for file in files:
if not has_suffix(file):
old_file_path = os.path.join(root, file)
new_file_path = os.path.join(root, file + '.json')
try:
os.rename(old_file_path, new_file_path)
print(f"已将 {old_file_path} 重命名为 {new_file_path}")
except OSError as e:
print(f"重命名文件 {old_file_path} 失败: {e}")
except Exception as e:
print(f"处理文件夹 {folder_path} 时发生未知错误: {e}")
if __name__ == "__main__":
folder_path = input("请输入要处理的文件夹路径: ")
# 去除路径首尾的引号
folder_path = folder_path.strip('"\'')
if not os.path.exists(folder_path):
print(f"输入的文件夹路径 {folder_path} 不存在,请检查后重新运行。")
else:
process_folder(folder_path)
print("处理结束。")
input("按任意键关闭控制台...")
整理提取spine模型.py
用于懒得找spine模型路径的时候,(如果模型名称都相同就不能使用)
import os
import shutil
import re
import concurrent.futures
import multiprocessing
def process_atlas_file(root, file, destination_folder, operation):
# 获取 .atlas 文件的基本名称
base_name = os.path.splitext(file)[0]
# 创建以 .atlas 文件命名的文件夹
target_folder = os.path.join(destination_folder, base_name)
if not os.path.exists(target_folder):
os.makedirs(target_folder)
print(f"已创建子文件夹: {target_folder}")
# 处理 .atlas 文件
atlas_file_path = os.path.join(root, file)
if operation == 'copy':
shutil.copy2(atlas_file_path, target_folder)
print(f"已复制 .atlas 文件: {atlas_file_path} 到 {target_folder}")
else:
shutil.move(atlas_file_path, target_folder)
print(f"已移动 .atlas 文件: {atlas_file_path} 到 {target_folder}")
# 寻找并处理 .json 或 .skel 文件
for ext in ['.json', '.skel']:
related_file = base_name + ext
related_file_path = os.path.join(root, related_file)
if os.path.exists(related_file_path):
if operation == 'copy':
shutil.copy2(related_file_path, target_folder)
print(f"已复制 {ext} 文件: {related_file_path} 到 {target_folder}")
else:
shutil.move(related_file_path, target_folder)
print(f"已移动 {ext} 文件: {related_file_path} 到 {target_folder}")
# 寻找并处理包含名称的 .png 文件
pattern = re.compile(rf'{re.escape(base_name)}.*\.png$')
for png_file in os.listdir(root):
if pattern.match(png_file):
png_file_path = os.path.join(root, png_file)
if operation == 'copy':
shutil.copy2(png_file_path, target_folder)
print(f"已复制 .png 文件: {png_file_path} 到 {target_folder}")
else:
shutil.move(png_file_path, target_folder)
print(f"已移动 .png 文件: {png_file_path} 到 {target_folder}")
def find_and_copy_files(source_folder, destination_folder, operation):
# 确保目标文件夹存在
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
print(f"已创建目标文件夹: {destination_folder}")
atlas_files = []
# 遍历源文件夹及其子文件夹,找出所有 .atlas 文件
for root, _, files in os.walk(source_folder):
for file in files:
if file.endswith('.atlas'):
atlas_files.append((root, file))
# 获取 CPU 核心数
cpu_count = multiprocessing.cpu_count()
# 使用线程池并行处理 .atlas 文件
with concurrent.futures.ThreadPoolExecutor(max_workers=cpu_count) as executor:
futures = []
for root, file in atlas_files:
future = executor.submit(process_atlas_file, root, file, destination_folder, operation)
futures.append(future)
# 等待所有任务完成
for future in concurrent.futures.as_completed(futures):
try:
future.result()
except Exception as e:
print(f"处理文件时出现错误: {e}")
if __name__ == "__main__":
source_folder = input("请输入源文件夹路径: ").strip()
destination_folder = input("请输入目标文件夹路径: ").strip()
# 去除引号
source_folder = source_folder.strip('"\'')
destination_folder = destination_folder.strip('"\'')
operation = input("请选择操作(输入 'copy' 进行复制,输入 'move' 进行移动): ").strip().lower()
if operation not in ['copy', 'move']:
print("输入的操作无效,请输入 'copy' 或 'move'。")
elif os.path.exists(source_folder):
print("开始查找并处理文件...")
find_and_copy_files(source_folder, destination_folder, operation)
print("文件处理完成。")
else:
print("源文件夹路径不存在,请检查后重新输入。")
input("按回车键退出程序...")
.
查看
有的游戏png和atlas纹理的大小不匹配,看着是碎的,可以让ai写个脚本来修改纹理以匹配atlas:
根据atlas修改纹理.py
需要opencv库
import os
import re
import cv2
import numpy as np
import concurrent.futures
import multiprocessing
def process_atlas_file(atlas_path, target_dir):
"""处理单个atlas文件,读取其中的图片信息并调整对应图片大小"""
try:
with open(atlas_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
except Exception as e:
print(f"无法读取文件 {atlas_path}: {e}")
return
image_size_map = {}
current_image = None
# 解析atlas文件,建立图片与size的映射关系
for i, line in enumerate(lines):
line = line.strip()
# 检查是否是图片名称行(.png结尾)
if line.endswith('.png'):
current_image = line
# 检查下一行是否存在且包含size信息
if i + 1 < len(lines):
next_line = lines[i + 1].strip()
size_match = re.search(r'size:\s*(\d+),\s*(\d+)', next_line)
if size_match:
width = int(size_match.group(1))
height = int(size_match.group(2))
image_size_map[current_image] = (width, height)
else:
print(f"警告: 在图片 {current_image} 后未找到对应的size信息")
else:
print(f"警告: 在图片 {current_image} 后未找到对应的size信息")
if not image_size_map:
print(f"在文件 {atlas_path} 中未找到有效的图片-size映射")
return
# 获取atlas文件所在目录
atlas_dir = os.path.dirname(atlas_path)
# 处理每个图片
for image_name, (width, height) in image_size_map.items():
# 构建图片的完整路径
image_path = os.path.join(atlas_dir, image_name)
# 检查图片文件是否存在
if not os.path.exists(image_path):
print(f"图片文件不存在: {image_path}")
continue
try:
# 使用支持中文路径的方法读取图片
with open(image_path, 'rb') as f:
img_array = np.asarray(bytearray(f.read()), dtype=np.uint8)
img = cv2.imdecode(img_array, cv2.IMREAD_UNCHANGED)
if img is None:
print(f"无法读取图片: {image_path}")
continue
# 获取原始图片尺寸
original_height, original_width = img.shape[:2]
# 如果图片尺寸与atlas中指定的尺寸不一致,则调整大小
if original_width != width or original_height != height:
print(f"调整图片大小: {image_name} 从 {original_width}x{original_height} 到 {width}x{height}")
# 使用高质量的调整方法
resized_img = cv2.resize(img, (width, height), interpolation=cv2.INTER_AREA)
# 使用支持中文路径的方法保存图片
success, encoded_img = cv2.imencode('.png', resized_img)
if success:
with open(image_path, 'wb') as f:
f.write(encoded_img)
print(f"成功调整并保存图片: {image_path}")
else:
print(f"无法保存图片: {image_path}")
else:
print(f"图片尺寸已符合要求: {image_path}")
except Exception as e:
print(f"处理图片 {image_path} 时出错: {e}")
def main():
while True:
"""主函数:获取用户输入的文件夹路径,遍历处理所有atlas文件"""
# 获取用户输入的文件夹路径
folder_path = input("请输入要处理的文件夹路径(输入 'q' 退出): ").strip()
if folder_path.lower() == 'q':
break
# 检查路径是否存在
if not os.path.exists(folder_path):
print(f"错误:路径不存在 - {folder_path}")
continue
# 检查是否是文件夹
if not os.path.isdir(folder_path):
print(f"错误:{folder_path} 不是一个文件夹")
continue
# 遍历文件夹中的所有文件,找出所有.atlas文件
atlas_files = []
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.endswith('.atlas'):
atlas_path = os.path.join(root, file)
atlas_files.append(atlas_path)
# 获取 CPU 核心数
num_cpus = multiprocessing.cpu_count()
# 使用线程池并行处理.atlas文件
with concurrent.futures.ThreadPoolExecutor(max_workers=num_cpus) as executor:
futures = [executor.submit(process_atlas_file, atlas_path, folder_path) for atlas_path in atlas_files]
for future in concurrent.futures.as_completed(futures):
try:
future.result()
except Exception as e:
print(f"处理过程中出现异常: {e}")
print("\n处理完成!")
if __name__ == "__main__":
try:
# 检查是否安装了OpenCV库
import cv2
print("OpenCV库已安装,版本:", cv2.__version__)
except ImportError:
print("错误:未安装OpenCV库。请先安装:pip install opencv-python")
else:
main()
.
工具
官方查看器:需要java9+,而且功能很少,不过轻便。
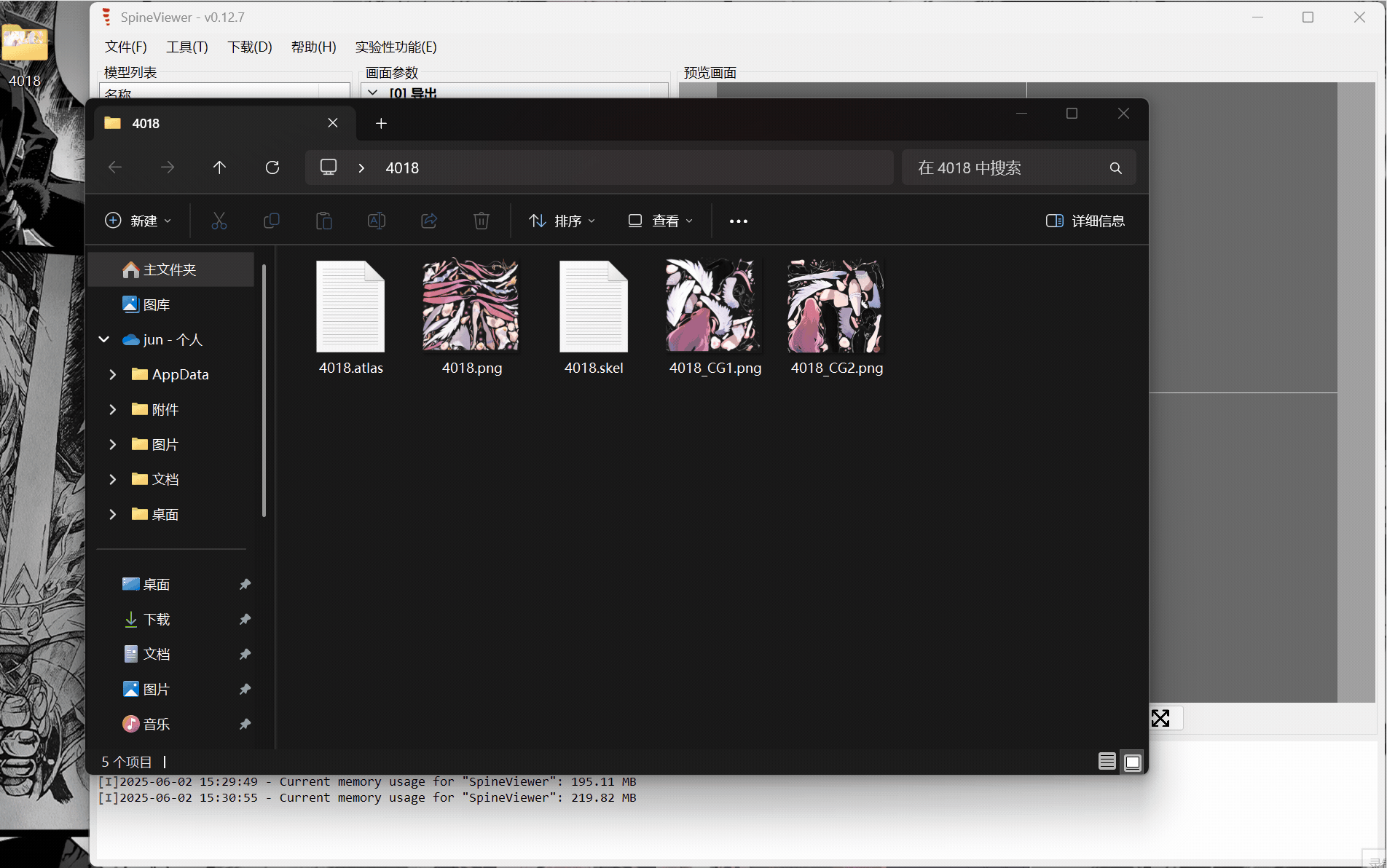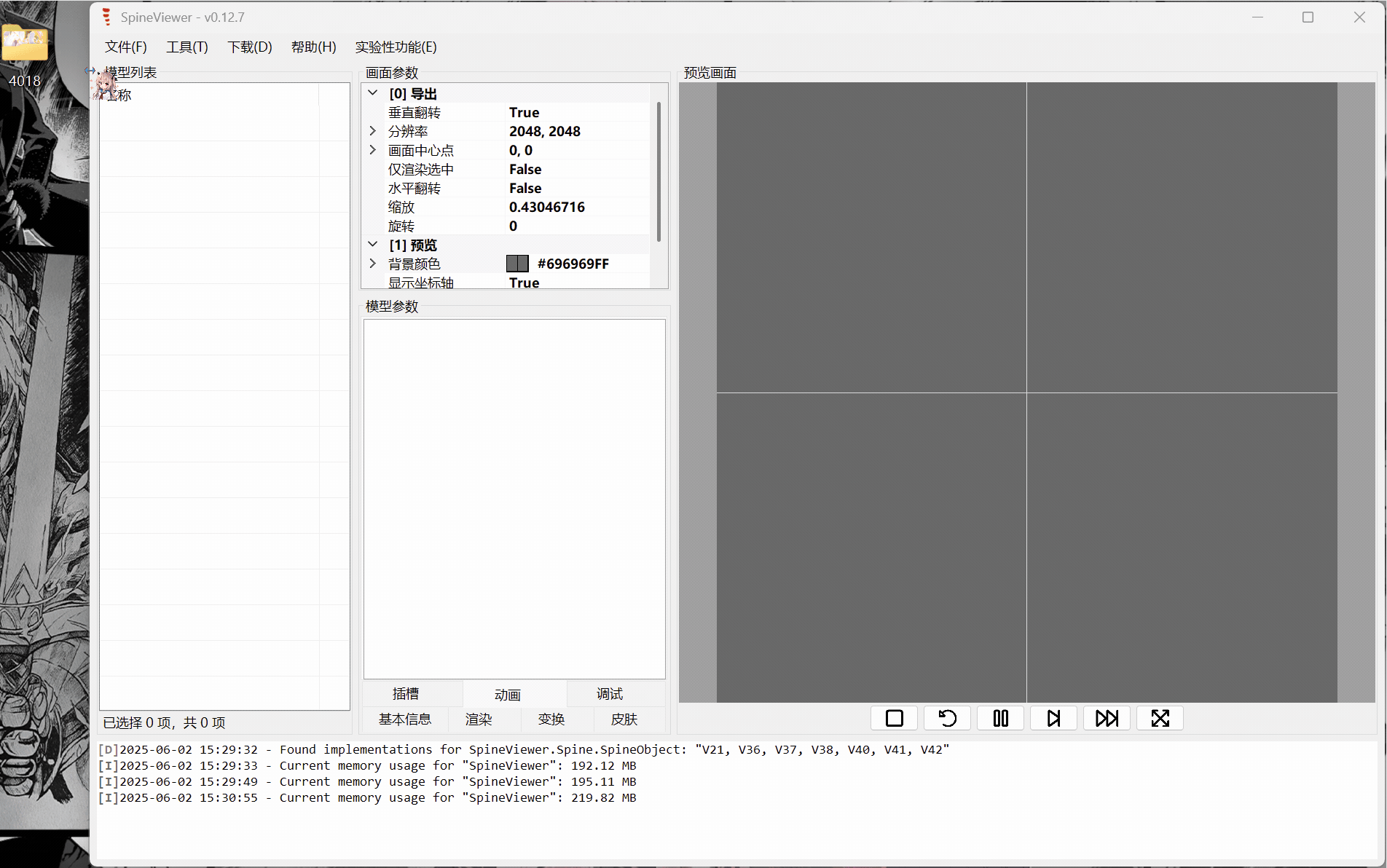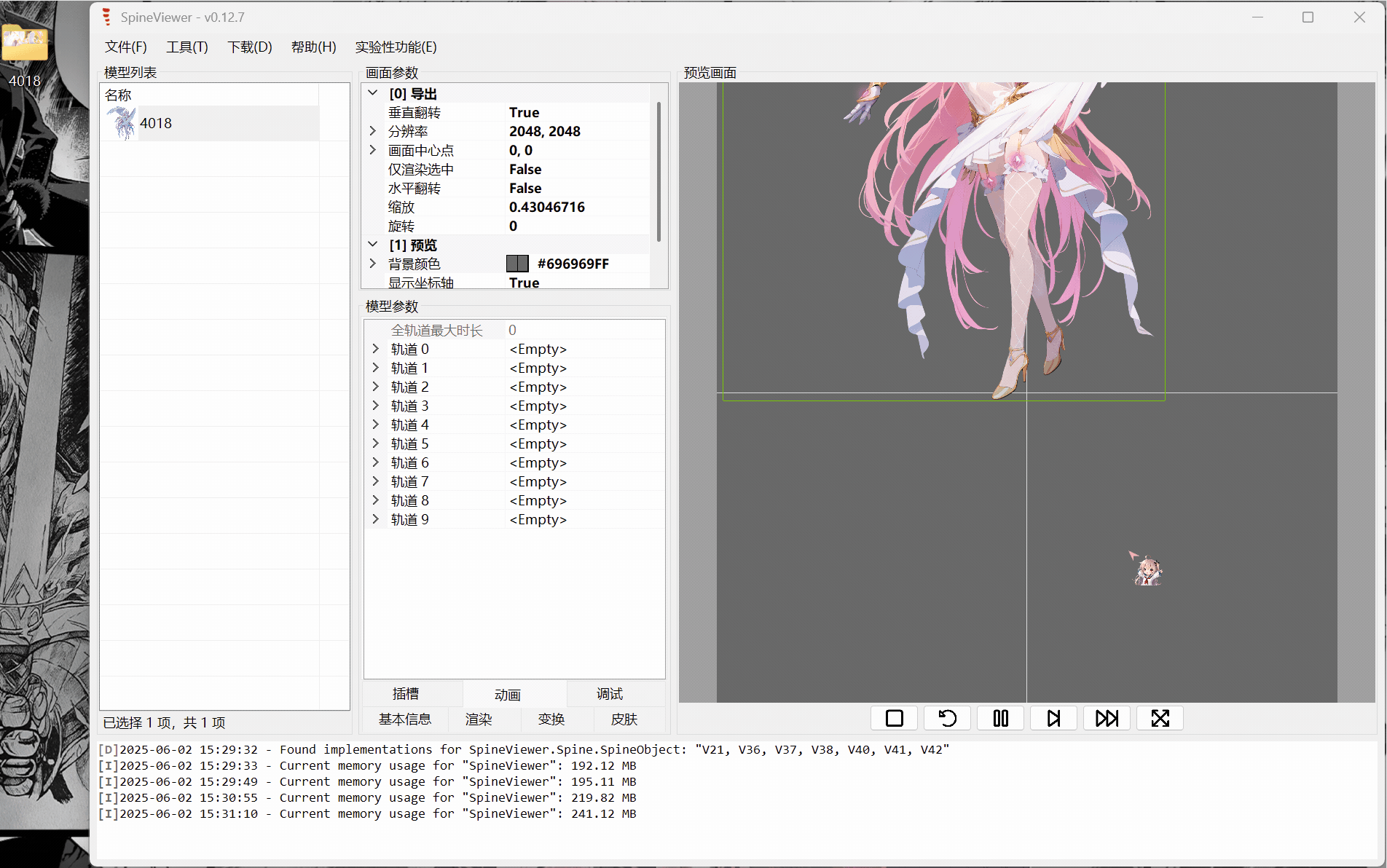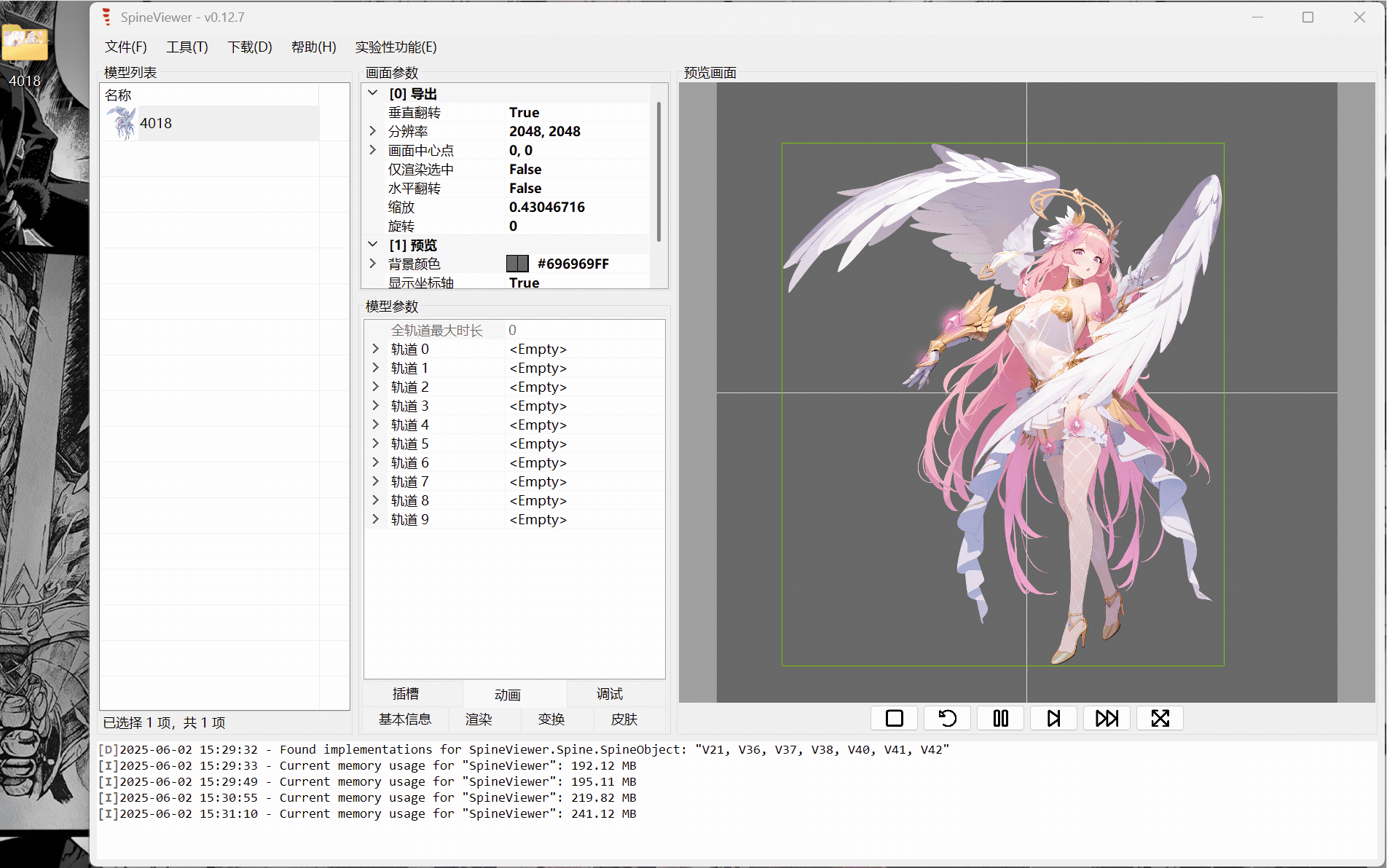
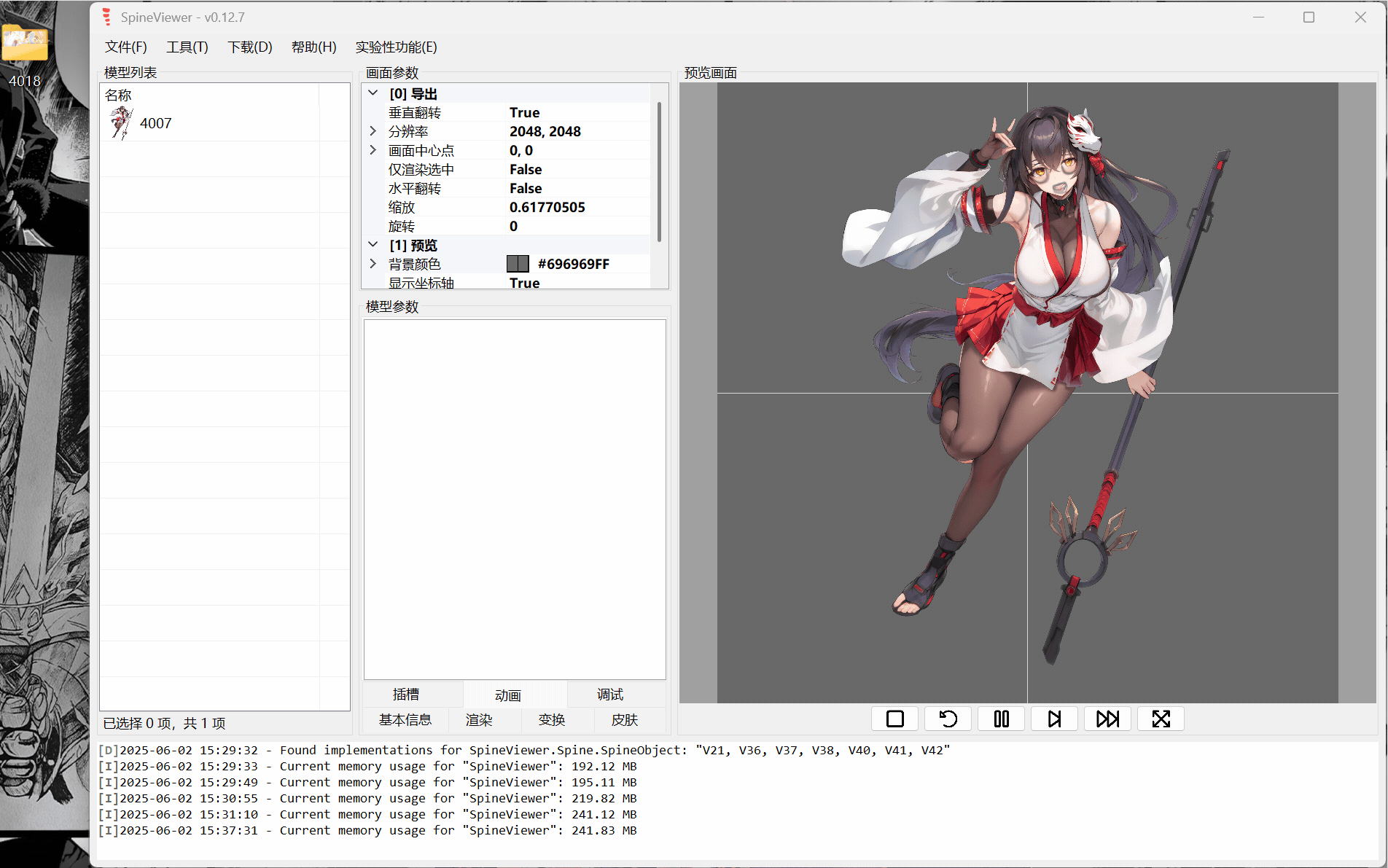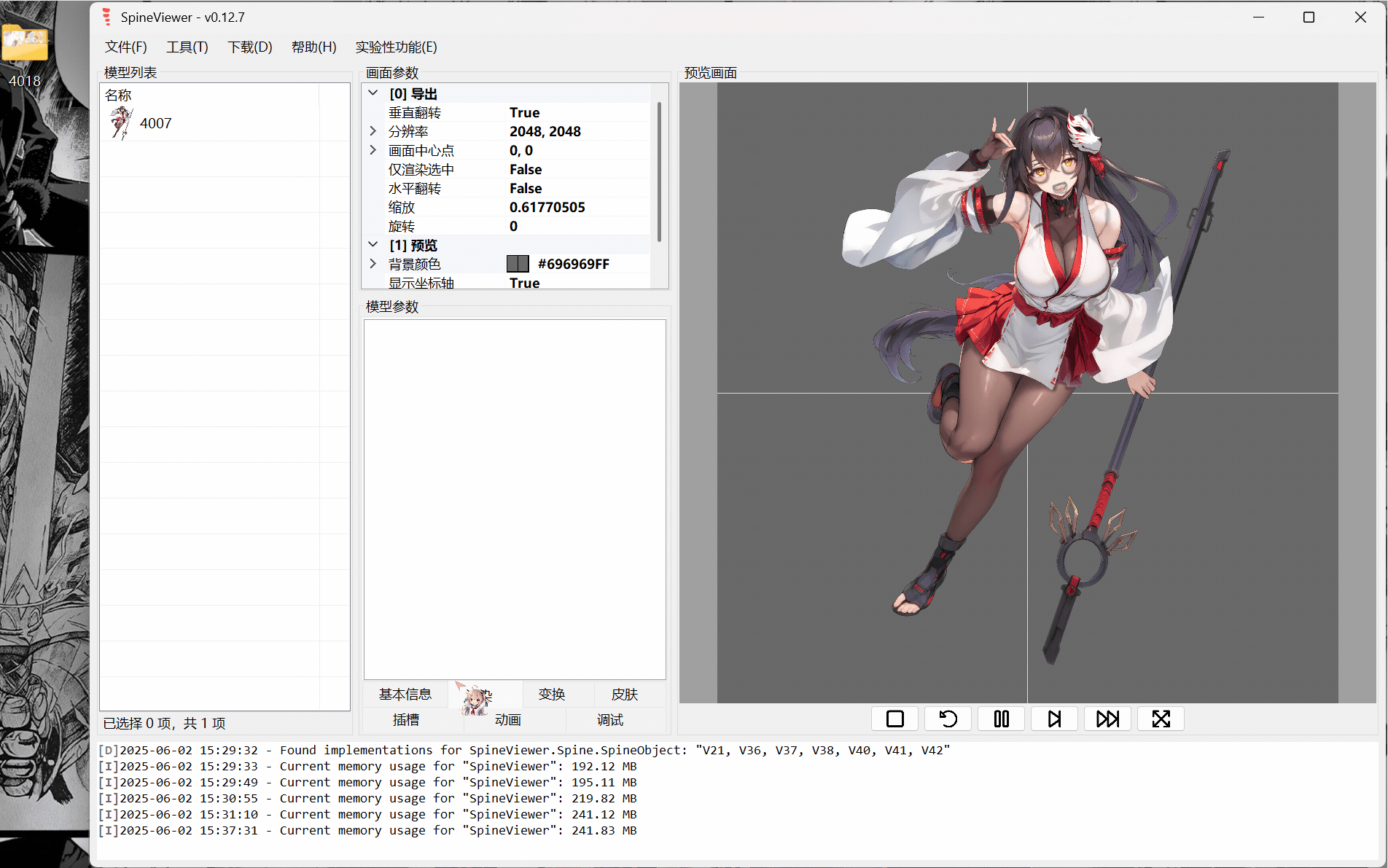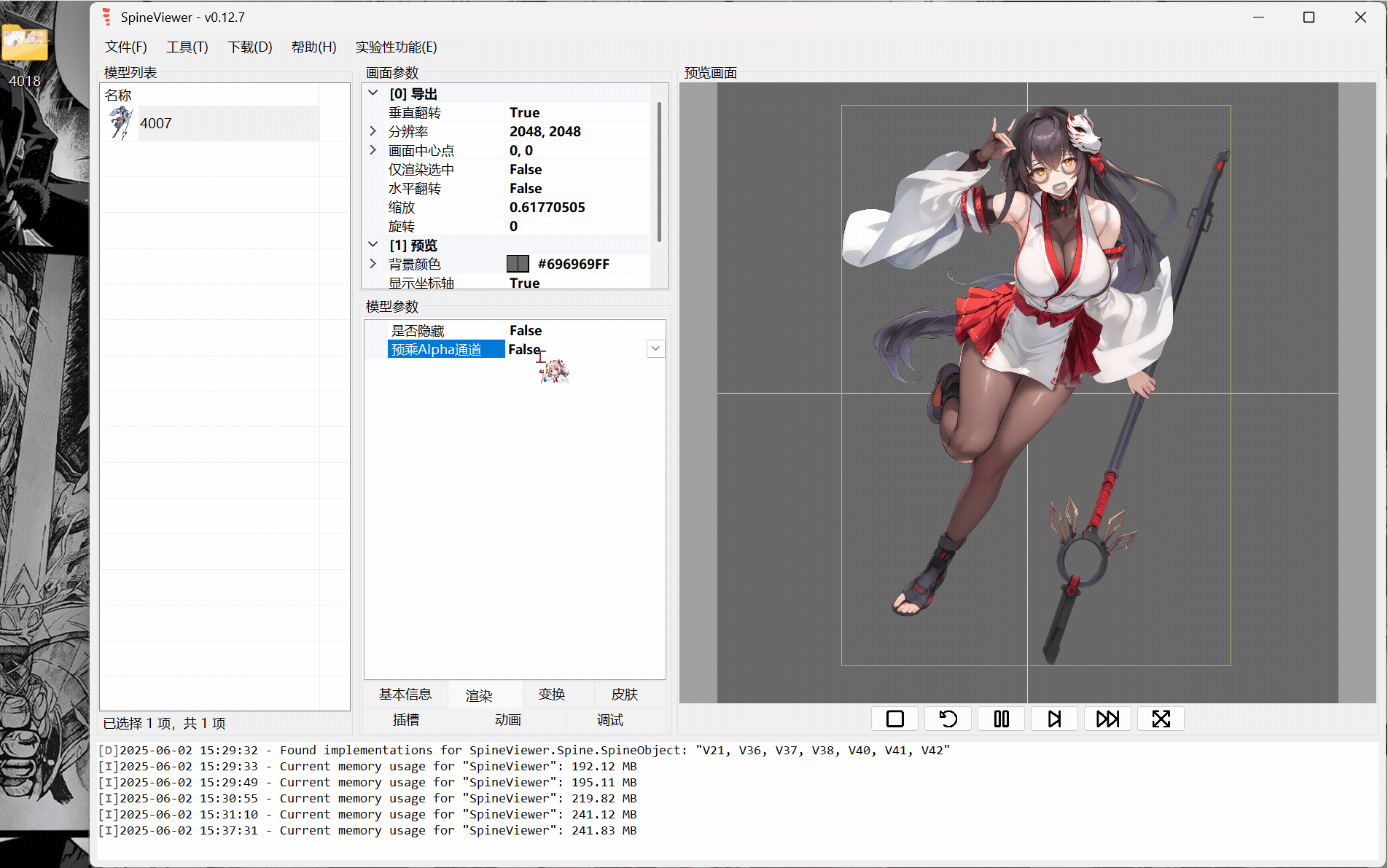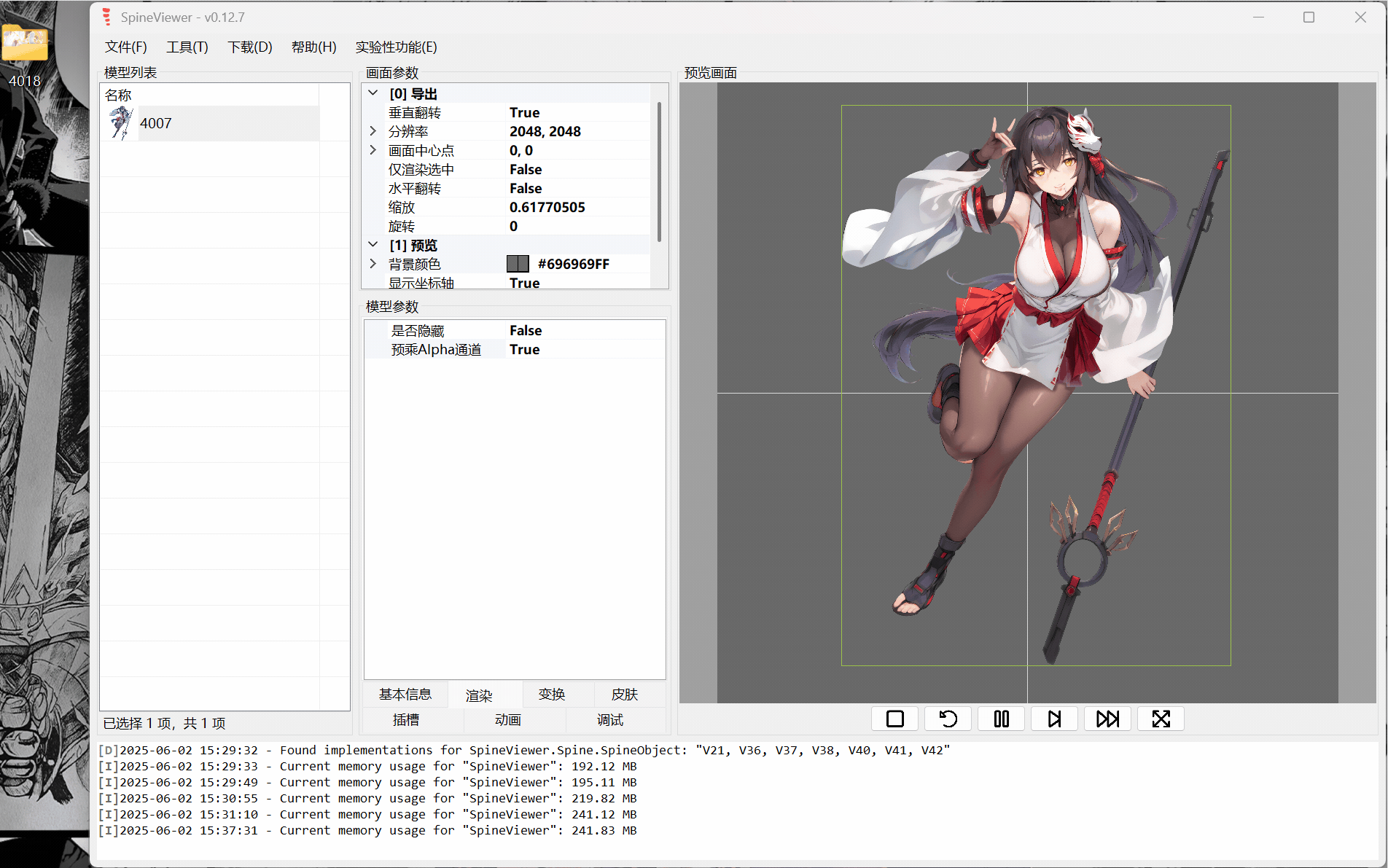
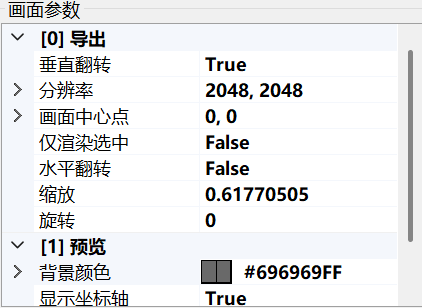
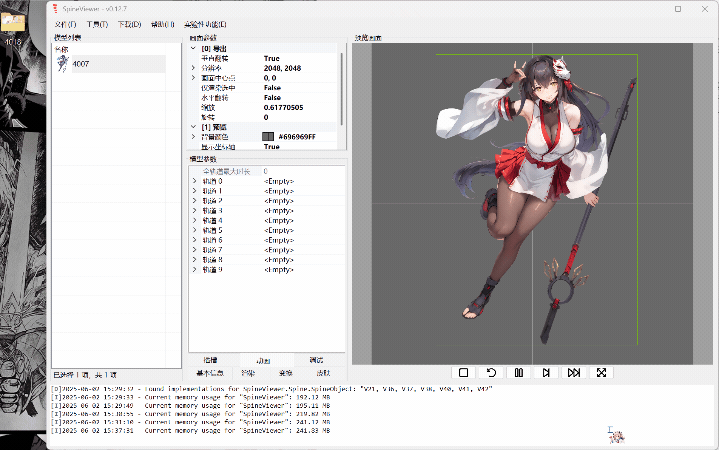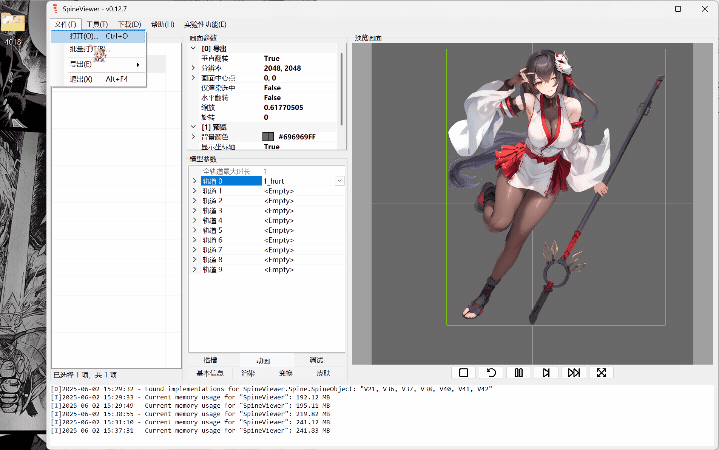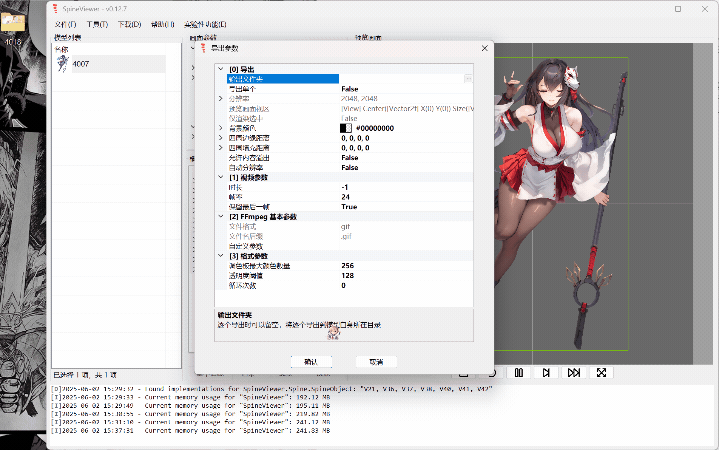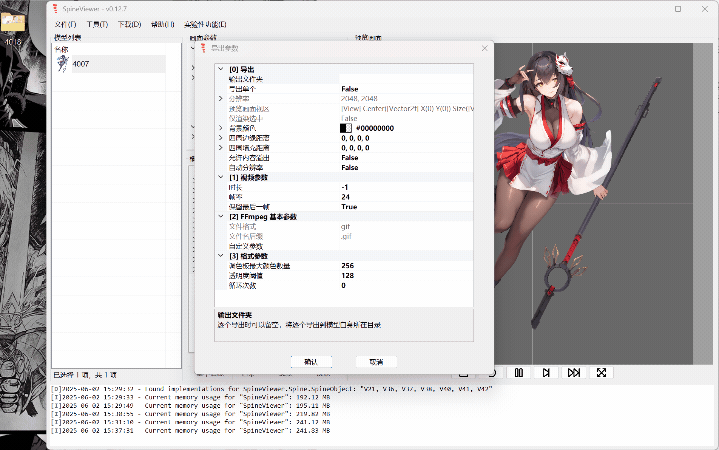
ww-rm:最推荐,支持导入插入多个spine模型,支持开关插槽,支持导出gif、mkv(需要文件目录里塞个ffmpeg,exe或添加ffmpeg.exe环境变量)。 FFmpeg
下面就只示范ww-rm的使用。
anosu:支持修改插槽透明(有些动作强绑插槽的ww-rm解决不了的可以用这个),支持导出gif。


.
live2d(还没怎么了解,空的)
.
“PSB”文件头的E-MOTE动画文件
将psb拖到FreeMoteViewer.exe上就可以打开了。
如果不行请参照wiki研究: Home · UlyssesWu/FreeMote Wiki · GitHub
.
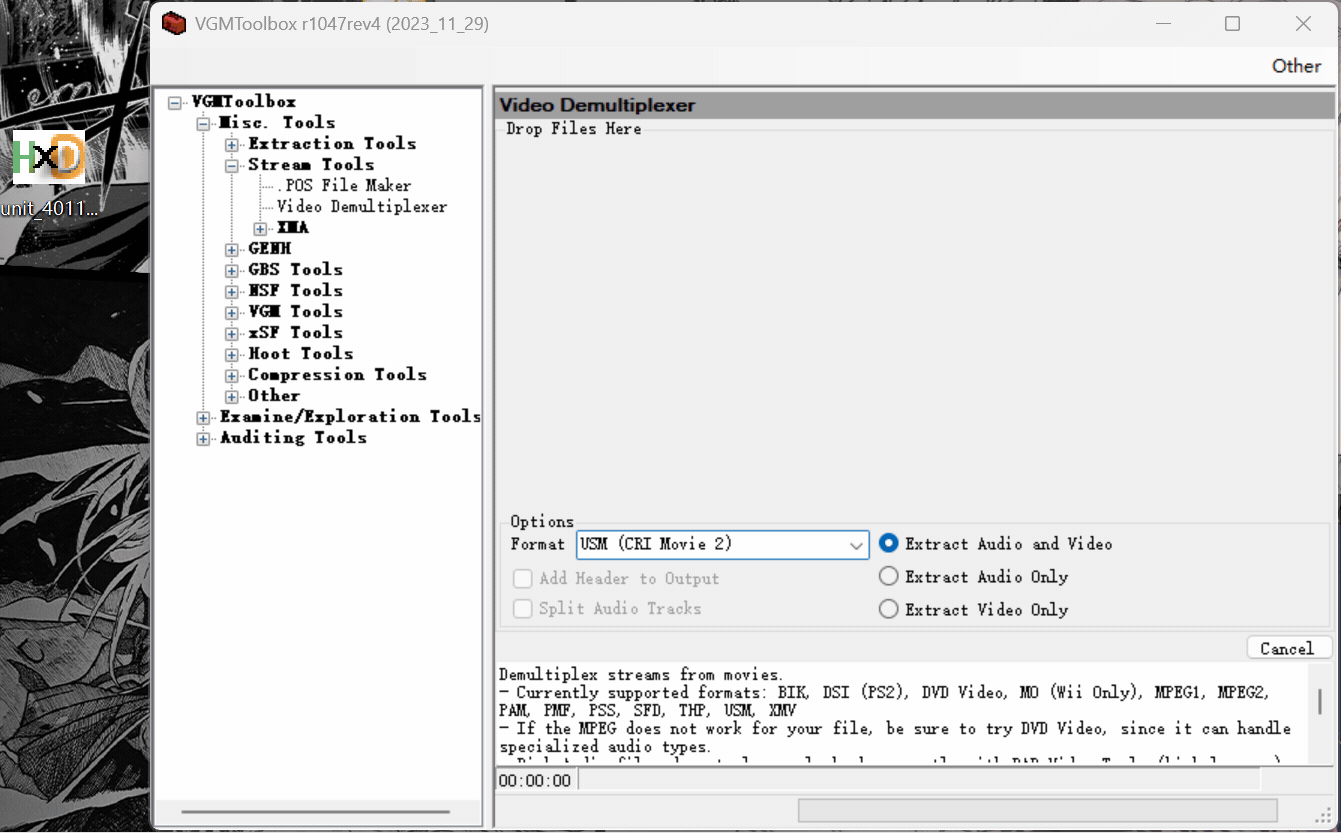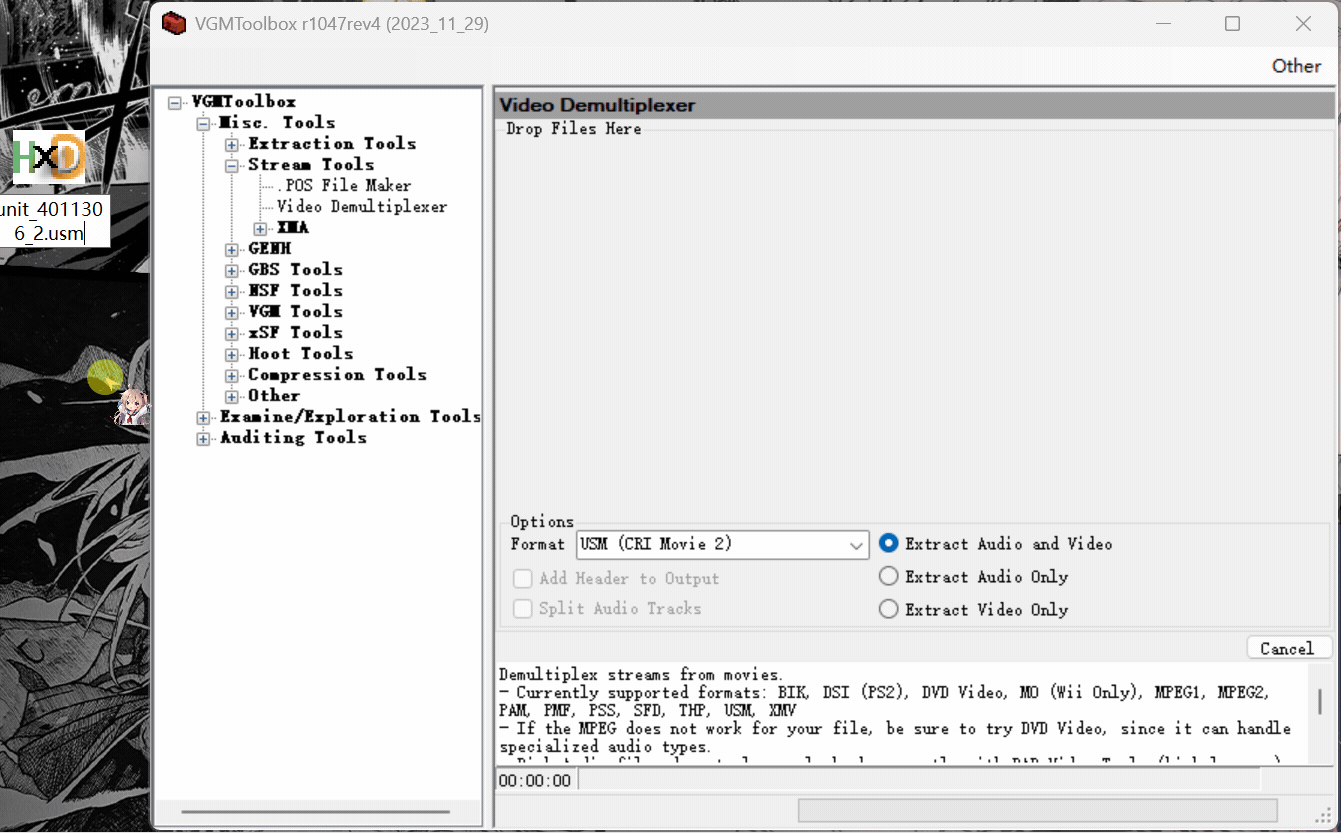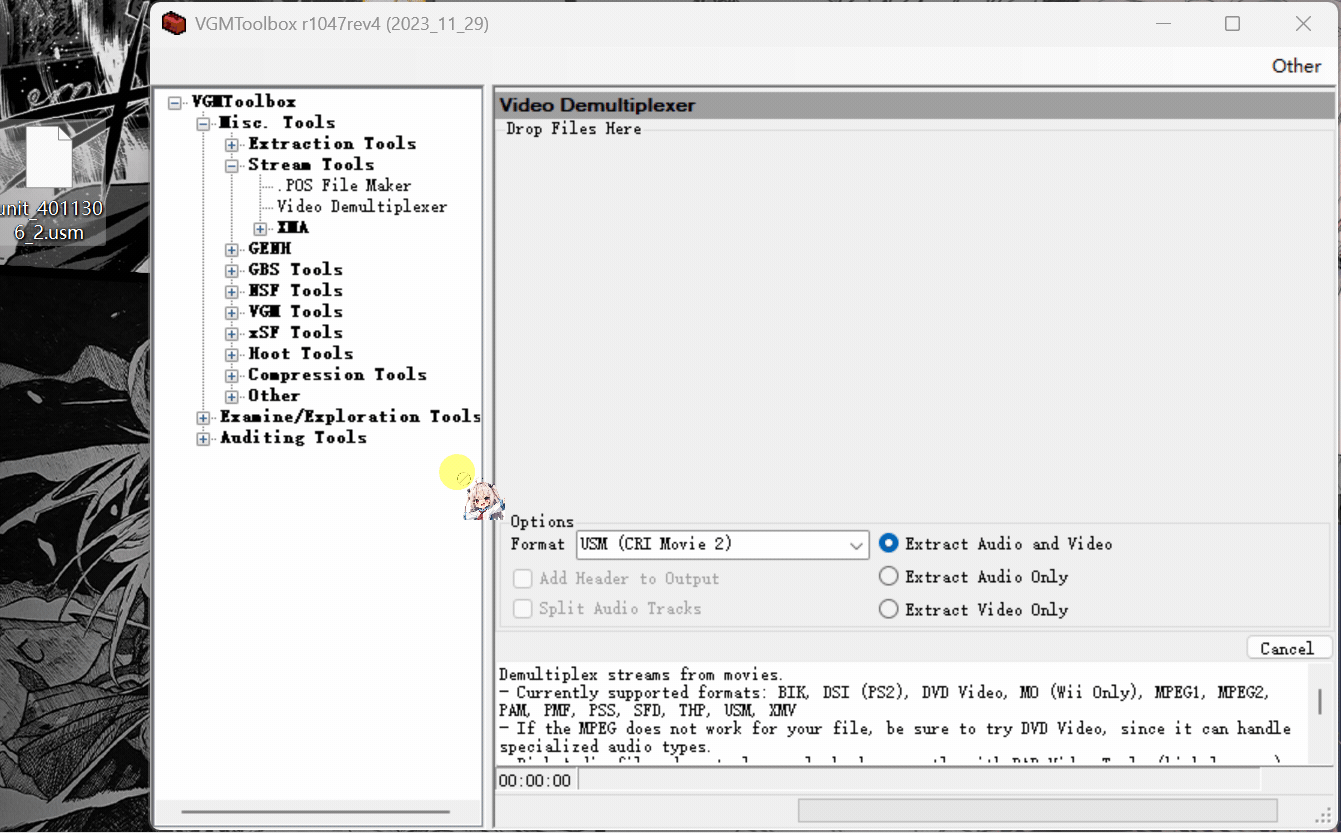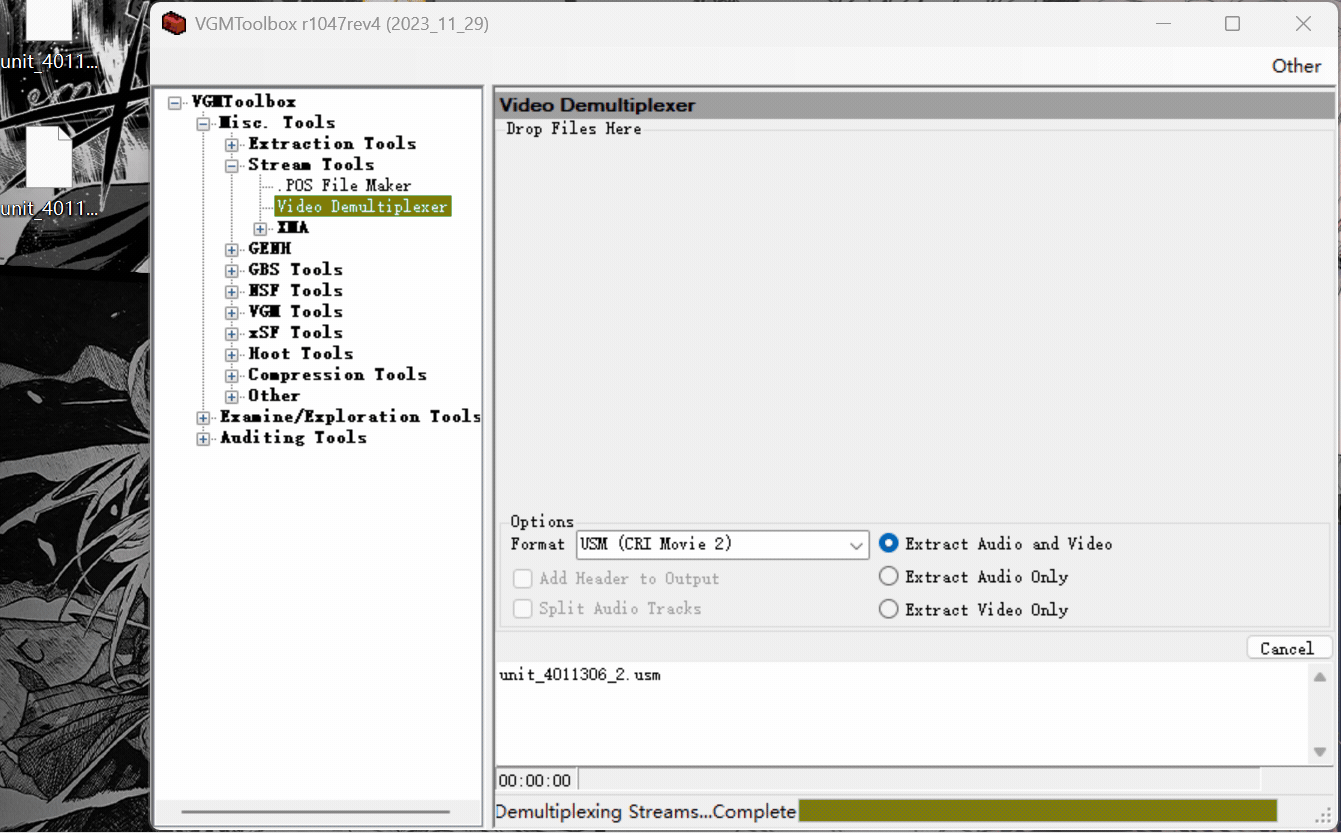
usm文件(一种压缩类型,文件头“CRID”)
使用
打开相应解码器:
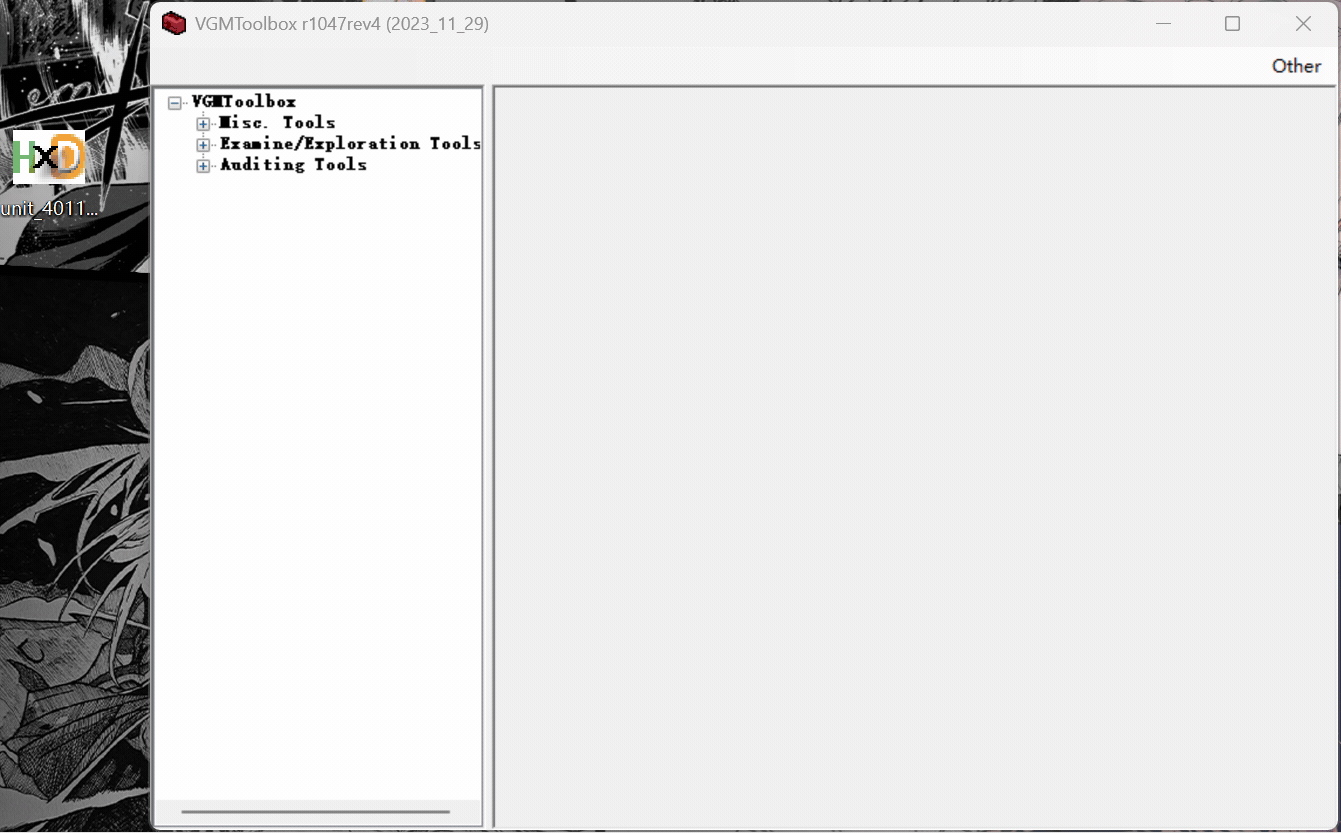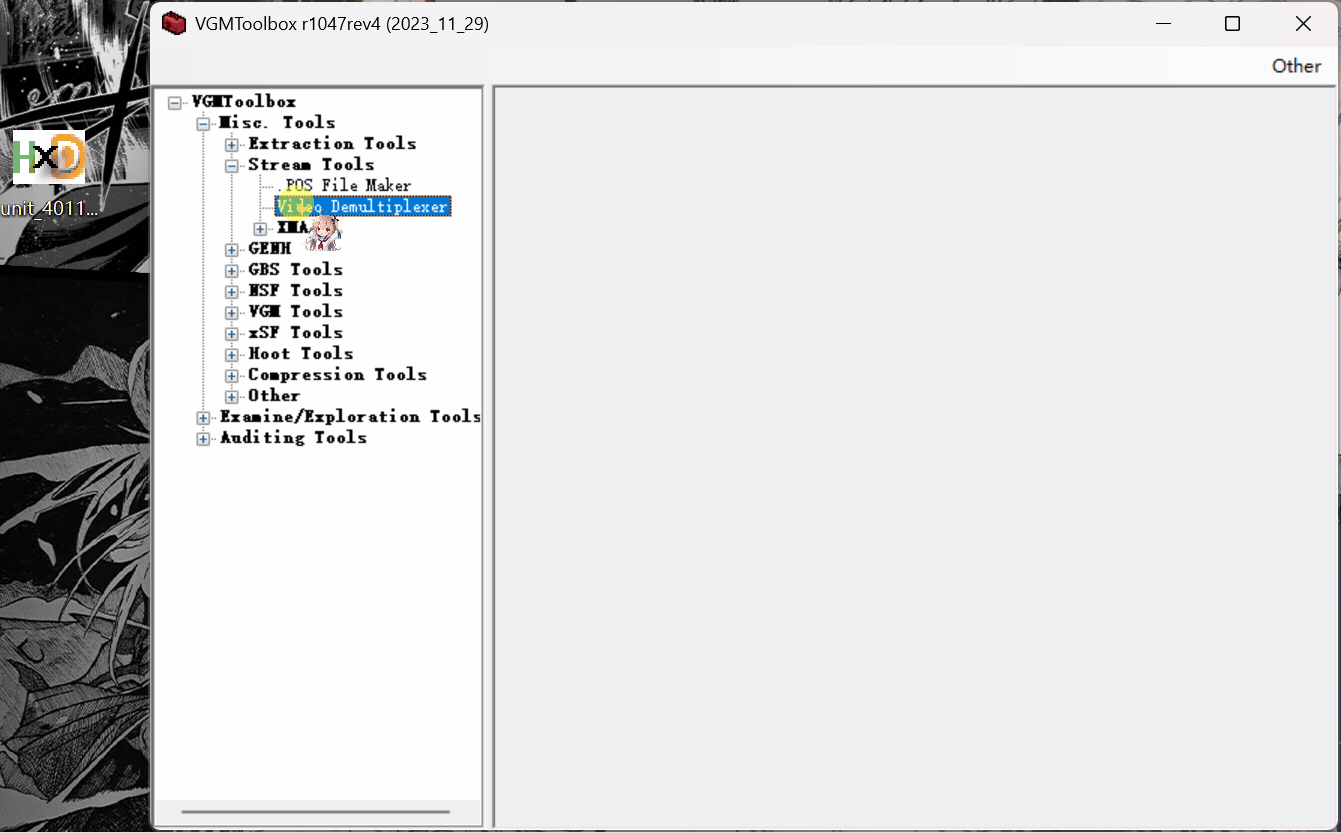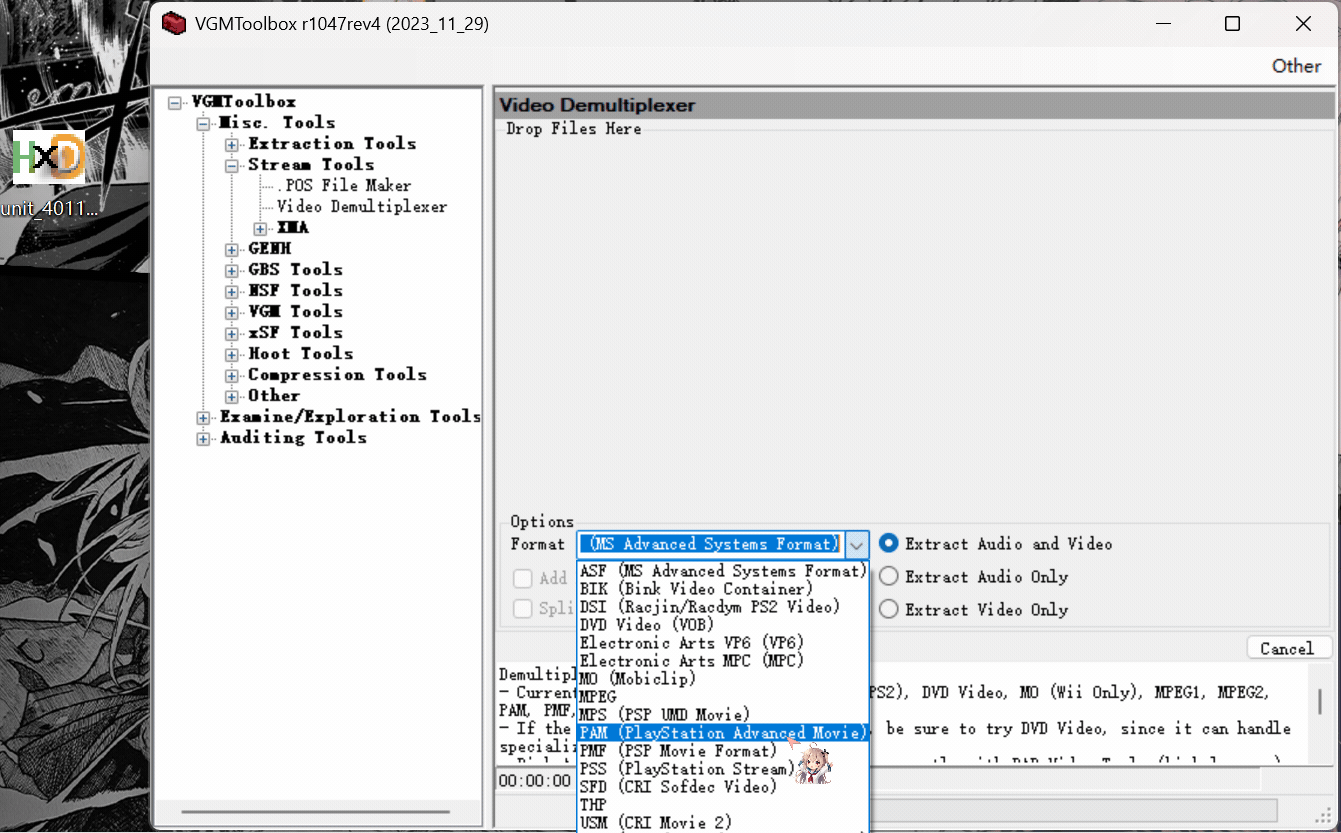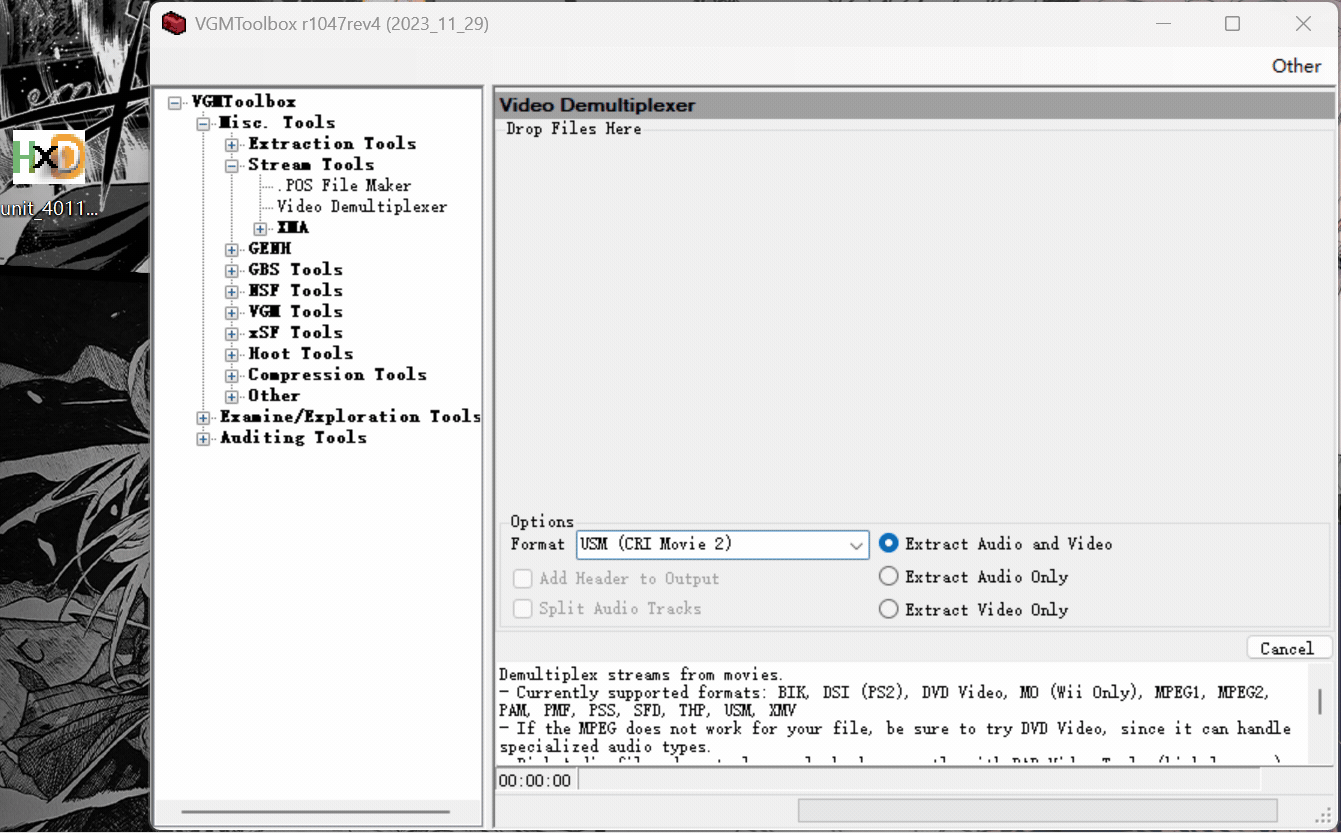
拖入未加密usm解码出.m2v视频文件:
m2v转mp4
需要opencv库
import cv2
import os
import concurrent.futures
def convert_m2v_to_mp4(input_file, output_file):
# 打开输入视频文件
cap = cv2.VideoCapture(input_file)
if not cap.isOpened():
print(f"无法打开输入视频文件: {input_file}")
return None
# 获取视频的帧率、宽度和高度
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# 定义视频编码器和创建 VideoWriter 对象
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_file, fourcc, fps, (width, height))
while True:
ret, frame = cap.read()
if ret:
# 将帧写入输出视频文件
out.write(frame)
else:
break
# 释放资源
cap.release()
out.release()
cv2.destroyAllWindows()
print(f"成功将 {input_file} 转换为 {output_file}")
return input_file
def process_folder(folder_path):
m2v_files = []
for root, _, files in os.walk(folder_path):
for file in files:
if file.endswith('.m2v'):
input_file = os.path.join(root, file)
output_file = os.path.splitext(input_file)[0] + '.mp4'
m2v_files.append((input_file, output_file))
# 获取 CPU 核心数并计算线程数
import multiprocessing
num_threads = max(1, multiprocessing.cpu_count() // 2)
converted_files = []
with concurrent.futures.ThreadPoolExecutor(max_workers=num_threads) as executor:
# 提交任务到线程池
futures = [executor.submit(convert_m2v_to_mp4, input_file, output_file) for input_file, output_file in m2v_files]
# 等待所有任务完成并收集转换后的文件
for future in concurrent.futures.as_completed(futures):
result = future.result()
if result:
converted_files.append(result)
# 在主线程中询问是否删除原文件
for input_file in converted_files:
choice = input(f"是否要删除原文件 {input_file}?(y/n): ").strip().lower()
if choice == 'y':
try:
os.remove(input_file)
print(f"已删除原文件 {input_file}")
except Exception as e:
print(f"删除原文件 {input_file} 时出错: {e}")
if __name__ == "__main__":
folder_path = input("请输入包含 .m2v 文件的文件夹路径: ")
if os.path.exists(folder_path):
process_folder(folder_path)
else:
print("输入的文件夹路径不存在,请检查后重新输入。")
input("end")
.
.
.
.
有些加密的站内的大佬已经给出解密脚本,按照脚本解密文件即可。
cocos2d xxtea解密器
xxtea解密.zip (19.4 KB)
AES-CBC解密.py
需要pycryptodome库
import os
import sys
import concurrent.futures
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import multiprocessing
def text_to_hex(text, length_bytes):
"""将文本转换为指定长度的十六进制字符串"""
bytes_data = text.encode('utf-8')
hex_data = bytes_data.hex()
# 截断或填充到指定长度
target_length = length_bytes * 2 # 每字节对应2个十六进制字符
if len(hex_data) > target_length:
hex_data = hex_data[:target_length]
else:
hex_data = hex_data.ljust(target_length, '0')
return hex_data
def decrypt_file(file_path, key, iv):
try:
with open(file_path, 'rb') as f:
ciphertext = f.read()
cipher = AES.new(key, AES.MODE_CBC, iv)
decrypted_data = unpad(cipher.decrypt(ciphertext), AES.block_size)
output_path = os.path.splitext(file_path)[0]
with open(output_path, 'wb') as f:
f.write(decrypted_data)
return f"已解密: {file_path} -> {output_path}"
except Exception as e:
return f"解密失败 {file_path}: {str(e)}"
def traverse_directory(directory, key, iv):
files_to_process = []
for root, dirs, files in os.walk(directory):
for file in files:
files_to_process.append(os.path.join(root, file))
# 获取CPU核心数,设置线程池大小
cpu_count = multiprocessing.cpu_count()
thread_count = max(1, cpu_count) # 至少1个线程
print(f"使用 {thread_count} 个线程进行解密")
with concurrent.futures.ThreadPoolExecutor(max_workers=thread_count) as executor:
# 提交所有文件解密任务
future_to_file = {executor.submit(decrypt_file, file_path, key, iv): file_path for file_path in files_to_process}
# 收集并打印结果
for future in concurrent.futures.as_completed(future_to_file):
result = future.result()
print(result)
def main():
while True:
# 获取文件或目录路径
path = input("请输入文件或文件夹路径(输入q退出): ").strip()
if path.lower() == 'q':
break
if not os.path.exists(path):
print("路径不存在,请检查后重试。")
continue
# 获取密钥和IV
key_input = input("请输入16/24/32字节密钥(十六进制或普通文本): ").strip()
iv_input = input("请输入16字节IV(十六进制或普通文本): ").strip()
# 自动转换非十六进制输入
try:
key = bytes.fromhex(key_input)
except ValueError:
key_length = 32 # 默认16字节密钥
if len(key_input) >= 24:
key_length = 48 # 24字节密钥
if len(key_input) >= 32:
key_length = 64 # 32字节密钥
key_hex = text_to_hex(key_input, key_length // 2)
key = bytes.fromhex(key_hex)
print(f"已将密钥转换为十六进制: {key_hex[:16]}...")
try:
iv = bytes.fromhex(iv_input)
except ValueError:
iv_hex = text_to_hex(iv_input, 16)
iv = bytes.fromhex(iv_hex)
print(f"已将IV转换为十六进制: {iv_hex}")
# 验证密钥和IV长度
if len(key) not in [16, 24, 32]:
print("密钥长度必须是16、24或32字节。")
continue
if len(iv) != 16:
print("IV长度必须是16字节。")
continue
# 处理文件或目录
if os.path.isfile(path):
print(decrypt_file(path, key, iv))
else:
traverse_directory(path, key, iv)
# 询问是否继续
while True:
choice = input("是否继续? (y/n): ").strip().lower()
if choice == 'y':
break
elif choice == 'n':
return
else:
print("无效的选择,请输入y或n")
if __name__ == "__main__":
try:
from Crypto.Cipher import AES
except ImportError:
print("缺少pycryptodome库,请先安装: pip install pycryptodome")
sys.exit(1)
main()
最后,实在没有办法的时候,如何优雅的求助:
请贴出游戏下载地址或安装包,不要只发加密的资源文件,那个对解密没什么用。