这个其实就只是他把一些步骤单独写入了几个函数
并且也将公司字符串加密了而已
在AppDelegate::AppDelegate你可以看到他在设置好tj版本号后调用了sub_369C50
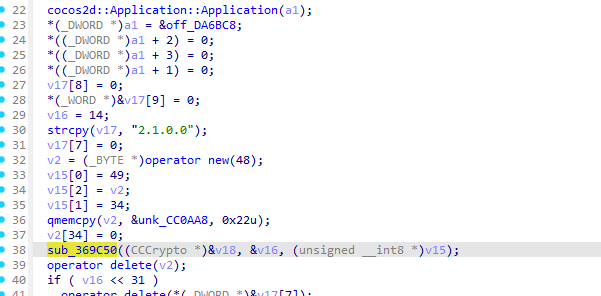
然后可以看到拼接字符串的两个常量字符串
对应解密代码的
phase1_str = f"hello{COMPANY_SHORT},world{company_full}"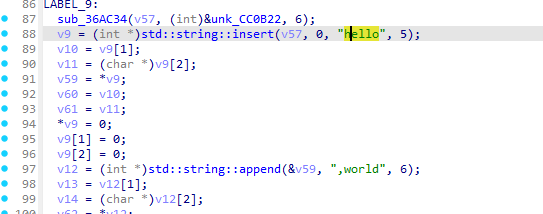
在看看之前我发的一些分析可以知道公司短名在拼接字符串前就做完了所以着重看一下sub_36AC34的实现
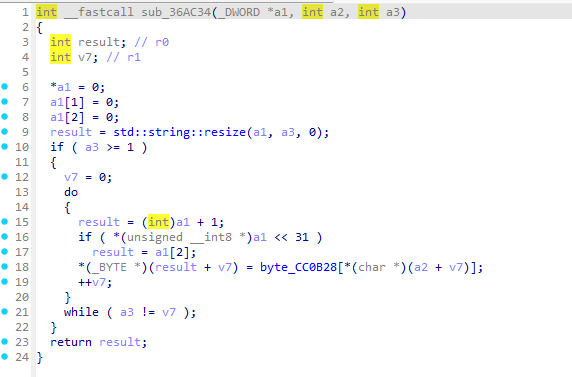
可以看到sub_36AC34其实就是使用密钥编码表来解密某个字符串
这里的密码表是
unsigned char byte_CC0B28[] =
{
0x15, 0x28, 0x69, 0x79, 0x7C, 0x3E, 0x0B, 0x21, 0x36, 0x6F,
0x66, 0x4E, 0x62, 0x2D, 0x77, 0x60, 0x73, 0x2A, 0x29, 0x0D,
0x44, 0x37, 0x6B, 0x5C, 0x00, 0x5A, 0x0F, 0x0C, 0x5E, 0x64,
0x1A, 0x65, 0x57, 0x6E, 0x4D, 0x7A, 0x47, 0x74, 0x40, 0x43,
0x02, 0x72, 0x45, 0x18, 0x5F, 0x32, 0x10, 0x08, 0x71, 0x11,
0x16, 0x6C, 0x30, 0x17, 0x14, 0x4B, 0x05, 0x63, 0x25, 0x35,
0x7F, 0x1E, 0x3B, 0x26, 0x01, 0x0E, 0x6A, 0x59, 0x13, 0x09,
0x2B, 0x50, 0x70, 0x03, 0x27, 0x53, 0x5B, 0x5D, 0x56, 0x68,
0x54, 0x2F, 0x23, 0x6D, 0x2C, 0x46, 0x1B, 0x4A, 0x12, 0x78,
0x1C, 0x4C, 0x4F, 0x61, 0x75, 0x51, 0x3F, 0x52, 0x20, 0x67,
0x39, 0x04, 0x48, 0x24, 0x55, 0x34, 0x31, 0x33, 0x3D, 0x22,
0x76, 0x42, 0x7D, 0x1D, 0x1F, 0x06, 0x7B, 0x2E, 0x3C, 0x0A,
0x58, 0x19, 0x41, 0x7E, 0x38, 0x3A, 0x49, 0x07
};
而加密的字符串表是传入的第二个参数a2
回到上级函数查看调用方法
sub_36AC34(v57, (int)&unk_CC0B22, 6);
那么可以知道unk_CC0B22是一个加密的字符串编码表
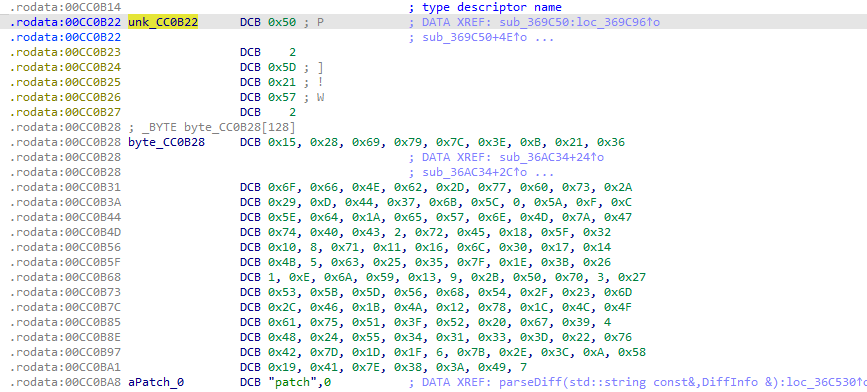
unsigned char unk_CC0B22[] =
{
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02
};
使用python代码可以解密
def decode_str():
decoded_bytes = [byte_CC0B28[b] for b in unk_CC0B22]
return bytes(decoded_bytes).decode('latin1')
可以得到公司名 TianJi
继续分析可以看到他再次调用了sub_36AC34
这次就是公司全名解码了
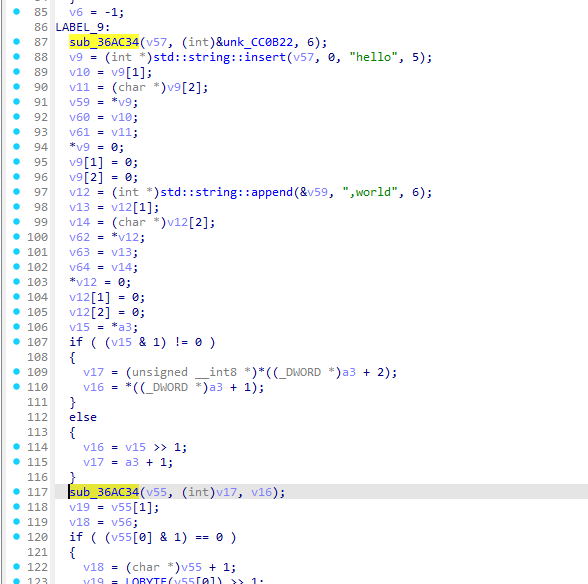
但是这次传入的参数并不是加密码表的指针而是一个基于a3的指针而a3是sub_369C50的第三个参数
int __fastcall sub_369C50(CCCrypto *a1, unsigned __int8 *a2, unsigned __int8 *a3)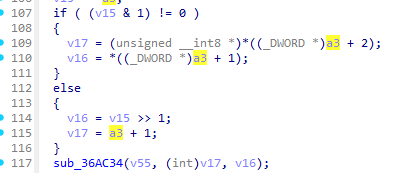
回到AppDelegate::AppDelegate查看sub_369C50的调用方法
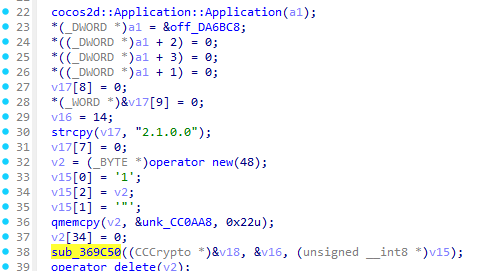
可以看到v15并没有什么有价值的东西
但是我们看到了
qmemcpy(v2, &unk_CC0AA8, 0x22u);这或许是IDA不能完美反汇编ARM的问题这里的unk_CC0AA8实际上才是加密的公司全名编码表
unsigned char unk_CC0AA8[] =
{
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02, 0x62, 0x7E, 0x21, 0x0A,
0x09, 0x29, 0x53, 0x5D, 0x25, 0x02, 0x09, 0x21, 0x62, 0x50,
0x1F, 0x39, 0x4F, 0x21, 0x09, 0x33, 0x09, 0x63, 0x03, 0x62,
0x7E, 0x21, 0x39, 0x75, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00
};
这里我们注意到unk_CC0AA8的长度为0x28(40)
而qmemcpy只复制0x22(34)长度
所以最终我们只保留
unsigned char unk_CC0AA8[] =
{
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02, 0x62, 0x7E, 0x21, 0x0A,
0x09, 0x29, 0x53, 0x5D, 0x25, 0x02, 0x09, 0x21, 0x62, 0x50,
0x1F, 0x39, 0x4F, 0x21, 0x09, 0x33, 0x09, 0x63, 0x03, 0x62,
0x7E, 0x21, 0x39, 0x75
};
继续分析sub_369C50就能看到日期位的字符串常量注意这里不一定是这种日期格式也有一些公司喜欢改成其他字符串
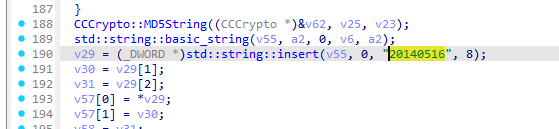
所以最终的密钥生成代码是
import hashlib
unk_CC0AA8 = [
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02, 0x62, 0x7E, 0x21, 0x0A,
0x09, 0x29, 0x53, 0x5D, 0x25, 0x02, 0x09, 0x21, 0x62, 0x50,
0x1F, 0x39, 0x4F, 0x21, 0x09, 0x33, 0x09, 0x63, 0x03, 0x62,
0x7E, 0x21, 0x39, 0x75
]
unk_CC0B22 = [
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02
]
byte_CC0B28 = [
0x15, 0x28, 0x69, 0x79, 0x7C, 0x3E, 0x0B, 0x21, 0x36, 0x6F,
0x66, 0x4E, 0x62, 0x2D, 0x77, 0x60, 0x73, 0x2A, 0x29, 0x0D,
0x44, 0x37, 0x6B, 0x5C, 0x00, 0x5A, 0x0F, 0x0C, 0x5E, 0x64,
0x1A, 0x65, 0x57, 0x6E, 0x4D, 0x7A, 0x47, 0x74, 0x40, 0x43,
0x02, 0x72, 0x45, 0x18, 0x5F, 0x32, 0x10, 0x08, 0x71, 0x11,
0x16, 0x6C, 0x30, 0x17, 0x14, 0x4B, 0x05, 0x63, 0x25, 0x35,
0x7F, 0x1E, 0x3B, 0x26, 0x01, 0x0E, 0x6A, 0x59, 0x13, 0x09,
0x2B, 0x50, 0x70, 0x03, 0x27, 0x53, 0x5B, 0x5D, 0x56, 0x68,
0x54, 0x2F, 0x23, 0x6D, 0x2C, 0x46, 0x1B, 0x4A, 0x12, 0x78,
0x1C, 0x4C, 0x4F, 0x61, 0x75, 0x51, 0x3F, 0x52, 0x20, 0x67,
0x39, 0x04, 0x48, 0x24, 0x55, 0x34, 0x31, 0x33, 0x3D, 0x22,
0x76, 0x42, 0x7D, 0x1D, 0x1F, 0x06, 0x7B, 0x2E, 0x3C, 0x0A,
0x58, 0x19, 0x41, 0x7E, 0x38, 0x3A, 0x49, 0x07
]
def decode_company_name():
decoded_bytes = [byte_CC0B28[b] for b in unk_CC0AA8]
return bytes(decoded_bytes).decode('latin1')
def decode_company_names():
decoded_bytes = [byte_CC0B28[b] for b in unk_CC0B22]
return bytes(decoded_bytes).decode('latin1')
def to_confuse(s):
s = s.upper()
return s.replace('_', '+').replace('.', ';').replace('6', ';')
def generate_key(version):
COMPANY_SHORT = str(decode_company_names())
DATE_STRING = "20140516"
company_full = decode_company_name()
version_main = version[:version.rfind('.')] if '.' in version else version
phase1_str = f"hello{COMPANY_SHORT},world{company_full}"
processed_phase1 = to_confuse(phase1_str)
md5_phase1 = hashlib.md5(processed_phase1.encode('utf-8')).hexdigest()
phase2_str = f"{md5_phase1}{DATE_STRING}{version_main}{COMPANY_SHORT}"
processed_phase2 = to_confuse(phase2_str)
reversed_str = processed_phase2[::-1]
final_key = hashlib.md5(reversed_str.encode('utf-8')).hexdigest()
return final_key
if __name__ == "__main__":
# 测试输出
test_version = "2.1.0.0"
print(f"Version: {test_version}")
print(f"Generated Key: {generate_key(test_version)}")
# 验证解码结果
print(f"\nDecoded Company Full Name: {decode_company_name()}")
print(f"Decoded Company Name: {decode_company_names()}")
得到的结果
Version: 2.1.0.0
Generated Key: d222827fe9d372a524908c6d0a96cba3
Decoded Company Full Name: TianJi Information Technology Inc.
Decoded Company Name: TianJi