只需要给我AppDelegate::AppDelegate这个函数的伪代码即可
这里是:
void __fastcall AppDelegate::AppDelegate(AppDelegate *this)
{
char *v2; // x20
int v3; // w3
cocos2d::FileUtils *v4; // x0
unsigned __int64 v5; // x1
char *v6; // x20
cocos2d::FileUtils *v7; // x8
int v8; // w3
cocos2d::FileUtils *v9; // x0
unsigned __int64 v10; // x1
__int128 v11; // [xsp+0h] [xbp-D0h] BYREF
char *v12; // [xsp+10h] [xbp-C0h]
_BYTE v13[9]; // [xsp+20h] [xbp-B0h] BYREF
char v14; // [xsp+29h] [xbp-A7h]
__int16 v15; // [xsp+2Ah] [xbp-A6h]
int v16; // [xsp+2Ch] [xbp-A4h]
void *v17; // [xsp+30h] [xbp-A0h]
__int128 v18; // [xsp+38h] [xbp-98h] BYREF
cocos2d::FileUtils *v19; // [xsp+48h] [xbp-88h]
__int128 v20; // [xsp+50h] [xbp-80h] BYREF
char *v21; // [xsp+60h] [xbp-70h]
_BYTE v22[9]; // [xsp+68h] [xbp-68h] BYREF
char v23; // [xsp+71h] [xbp-5Fh]
__int16 v24; // [xsp+72h] [xbp-5Eh]
int v25; // [xsp+74h] [xbp-5Ch]
void *v26; // [xsp+78h] [xbp-58h]
__int128 v27; // [xsp+80h] [xbp-50h] BYREF
cocos2d::FileUtils *v28; // [xsp+90h] [xbp-40h]
__int64 v29; // [xsp+98h] [xbp-38h]
v29 = *(_QWORD *)(_ReadStatusReg(ARM64_SYSREG(3, 3, 13, 0, 2)) + 40);
cocos2d::Application::Application(this);
*(_QWORD *)this = off_10283C0;
*((_QWORD *)this + 1) = 0LL;
*((_QWORD *)this + 2) = 0LL;
*((_QWORD *)this + 3) = 0LL;
v22[0] = 14;
v26 = 0LL;
strcpy(&v22[1], "2.1.0.0");
v23 = 0;
v24 = 0;
v25 = 0;
v20 = 0uLL;
v2 = (char *)operator new(0x30uLL);
v21 = v2;
strcpy(v2 + 32, "9u");
v20 = xmmword_D3A490;
*(_OWORD *)v2 = xmmword_D3A5AC;
*((_OWORD *)v2 + 1) = unk_D3A5BC;
sub_4B9340(&v27, v22, &v20);
operator delete(v2);
if ( (v22[0] & 1) != 0 )
operator delete(v26);
if ( (v27 & 1) != 0 )
v4 = v28;
else
v4 = (cocos2d::FileUtils *)((char *)&v27 + 1);
if ( (v27 & 1) != 0 )
v5 = DWORD2(v27);
else
v5 = (unsigned __int64)(unsigned __int8)v27 >> 1;
cocos2d::FileUtils::lua_cocos2dx_ui_RichElement_equalType__Terminology(v4, (const char *)v5, 0, v3);
v17 = 0LL;
v13[0] = 14;
strcpy(&v13[1], "2.1.0.0");
v14 = 0;
v15 = 0;
v16 = 0;
v6 = (char *)operator new(0x30uLL);
v12 = v6;
v11 = xmmword_D3A4A0;
strcpy(v6 + 30, "~!9u-4--");
*(_OWORD *)v6 = xmmword_D3A5CF;
*((_OWORD *)v6 + 1) = unk_D3A5DF;
sub_4B9340(&v18, v13, &v11);
if ( (v27 & 1) != 0 )
{
*(_BYTE *)v28 = 0;
*((_QWORD *)&v27 + 1) = 0LL;
}
else
{
LOWORD(v27) = 0;
}
std::string::reserve(&v27, 0LL);
v7 = v19;
v19 = 0LL;
v28 = v7;
v27 = v18;
v18 = 0uLL;
operator delete(v6);
if ( (v13[0] & 1) != 0 )
operator delete(v17);
if ( (v27 & 1) != 0 )
v9 = v28;
else
v9 = (cocos2d::FileUtils *)((char *)&v27 + 1);
if ( (v27 & 1) != 0 )
v10 = DWORD2(v27);
else
v10 = (unsigned __int64)(unsigned __int8)v27 >> 1;
cocos2d::FileUtils::lua_cocos2dx_ui_RichElement_equalType__Terminology(v9, (const char *)v10, 1, v8);
if ( (v27 & 1) != 0 )
operator delete(v28);
}
SUB:
__int64 __fastcall sub_96C0EC(__int64 a1, int a2, _QWORD *a3, int a4)
{
int v5; // w24
int v6; // w10
__int64 v7; // x11
int v8; // w8
int v9; // w12
int v10; // w14
__int64 v11; // x14
char v12; // w15
unsigned int v13; // w20
__int64 v14; // x0
unsigned int v15; // w21
void *v16; // x22
_DWORD *v17; // x25
void *isAnchorTextDelEnabled__Profit; // x8
int v19; // w21
_BYTE *v20; // x0
unsigned int v22; // [xsp+4h] [xbp-5Ch] BYREF
unsigned __int8 v23[8]; // [xsp+8h] [xbp-58h] BYREF
__int64 v24; // [xsp+10h] [xbp-50h]
__int64 v25; // [xsp+18h] [xbp-48h]
v25 = *(_QWORD *)(_ReadStatusReg(ARM64_SYSREG(3, 3, 13, 0, 2)) + 40);
v5 = *(unsigned __int8 *)(a1 + 2);
if ( v5 != 101 && v5 != 33 )
{
v13 = *(_DWORD *)(a1 + 3);
v16 = 0LL;
v17 = (_DWORD *)(a1 + 7);
v15 = a2 - 7;
LABEL_14:
if ( v13 >= 0x3200001 )
{
if ( v16 )
lua_cocos2dx_ui_Widget_clone__Formidable(v16);
return (unsigned int)-1;
}
if ( v5 != 33 && v5 != 122 )
{
*a3 = v17;
return v15;
}
isAnchorTextDelEnabled__Profit = (void *)lua_cocos2dx_ui_RichText_isAnchorTextDelEnabled__Profit((int)(v13 + 1));
*a3 = isAnchorTextDelEnabled__Profit;
if ( *v17 == v13 )
{
v19 = LZ4_decompress_safe((int)v17 + 4, isAnchorTextDelEnabled__Profit);
if ( v16 )
lua_cocos2dx_ui_Widget_clone__Formidable(v16);
v20 = (_BYTE *)*a3;
if ( v19 == v13 )
{
v15 = v13;
v20[v13] = 0;
return v15;
}
lua_cocos2dx_ui_Widget_clone__Formidable(v20);
*a3 = 0LL;
}
return (unsigned int)-1;
}
if ( !dword_10E8E40 )
return (unsigned int)-1;
v6 = dword_10E8DC0[a4];
v7 = qword_10E8CC0[a4];
v8 = 0;
if ( v6 <= 16 )
v9 = 16;
else
v9 = dword_10E8DC0[a4];
*(_QWORD *)v23 = 0LL;
v24 = 0LL;
do
{
v10 = v8 + 15;
if ( v8 >= 0 )
v10 = v8;
v11 = (int)(v8 - (v10 & 0xFFFFFFF0));
v12 = *(_BYTE *)(v7 + v8 % v6);
++v8;
v23[v11] ^= v12 ^ *(_BYTE *)(a1 + 3 + v11);
}
while ( v8 < v9 );
v13 = *(_DWORD *)(a1 + 19);
v22 = 0;
v14 = tj_xxtea_decrypt((unsigned __int8 *)(a1 + 23), a2 - 23, v23, 0x10u, &v22);
v15 = v22;
v16 = (void *)v14;
if ( v22 )
{
v17 = (_DWORD *)v14;
goto LABEL_14;
}
return v15;
}
“sub”函数告诉我们:
“time + J/whatever + hello + ,world” → 结果:“hello,worldTianJi”
COMPANY_SHORT = “TianJi “hello,world” + “TianJi” + CompanyFullName(obfuscated)
“20140516” + version_main + “TianJi”
KEY = MD5(
reverse(
to_confuse(
MD5(phase1) +
“20140516” +
version_main +
“TianJi”)))
我不是说这样做是对的,这只是我理解并采取的做法。
我得到的结果:
795f3275fe953f6e2c6bd826fabf8915
你的这段代码和我之前说的结构不大一样的那个差不多 是否能提供so文件的下载链接 apk下载的话太麻烦
我是新用户,无法发送附件。请问我应该使用哪个网站上传.so文件?
随便都行可以使用Google Drive
好了,找到了。 libcocos2dlua.zip
我之前觉得可能是解码的问题,进一步分析后发现,游戏启动时会立即注入一个密钥(动态密钥表),如果你查找这些密钥,它们都是干净的。
0x10E8DC0 , 0x10E8CC0
我会继续调查,也许解码方式有所不同,我也不确定。
不幸的是当前时间是5:30 UTC
是开始工作的时间我需要到8:30 UTC才有时间查看了
还有你可以使用母语发言因为"谷歌翻译腔"有点重
我大致看了一下
公司的短名也是加密的
着重看一下sub_369C50中sub_36AC34的调用方法 这里是两个码表处理解密的地方
我这里有一个大致的框架
这个框架中
phase1_str 和 DATE_STRING 已经确定
COMPANY_SHORT和码表解密还没有确定
import hashlib
# 逆向出的查表数据
byte_D375B6 = [
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02, 0x62, 0x7E, 0x21, 0x0A,
0x09, 0x29, 0x53, 0x5D, 0x25, 0x02, 0x09, 0x21, 0x62, 0x50,
0x1F, 0x39, 0x4F, 0x21, 0x09, 0x33, 0x09, 0x63, 0x03, 0x62,
0x7E, 0x21, 0x39, 0x75, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00
]
byte_D375B61 = [
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02, 0x62, 0x7E, 0x21, 0x0A,
0x09, 0x29, 0x53, 0x5D, 0x25, 0x02, 0x09, 0x21, 0x62, 0x50,
0x1F, 0x39, 0x4F, 0x21, 0x09, 0x33, 0x09, 0x63, 0x03, 0x62,
0x7E, 0x21, 0x39, 0x75, 0x2D, 0x34, 0x2D, 0x2D, 0x00, 0x00
]
byte_D375D5 = [
0x15, 0x28, 0x69, 0x79, 0x7C, 0x3E, 0x0B, 0x21, 0x36, 0x6F,
0x66, 0x4E, 0x62, 0x2D, 0x77, 0x60, 0x73, 0x2A, 0x29, 0x0D,
0x44, 0x37, 0x6B, 0x5C, 0x00, 0x5A, 0x0F, 0x0C, 0x5E, 0x64,
0x1A, 0x65, 0x57, 0x6E, 0x4D, 0x7A, 0x47, 0x74, 0x40, 0x43,
0x02, 0x72, 0x45, 0x18, 0x5F, 0x32, 0x10, 0x08, 0x71, 0x11,
0x16, 0x6C, 0x30, 0x17, 0x14, 0x4B, 0x05, 0x63, 0x25, 0x35,
0x7F, 0x1E, 0x3B, 0x26, 0x01, 0x0E, 0x6A, 0x59, 0x13, 0x09,
0x2B, 0x50, 0x70, 0x03, 0x27, 0x53, 0x5B, 0x5D, 0x56, 0x68,
0x54, 0x2F, 0x23, 0x6D, 0x2C, 0x46, 0x1B, 0x4A, 0x12, 0x78,
0x1C, 0x4C, 0x4F, 0x61, 0x75, 0x51, 0x3F, 0x52, 0x20, 0x67,
0x39, 0x04, 0x48, 0x24, 0x55, 0x34, 0x31, 0x33, 0x3D, 0x22,
0x76, 0x42, 0x7D, 0x1D, 0x1F, 0x06, 0x7B, 0x2E, 0x3C, 0x0A,
0x58, 0x19, 0x41, 0x7E, 0x38, 0x3A, 0x49, 0x07
]
def decode_company_name():
"""通过查表解码隐藏的公司全名"""
decoded_bytes = [byte_D375D5[b] for b in byte_D375B6]
return bytes(decoded_bytes).decode('latin1')
def decode_company_name1():
"""通过查表解码隐藏的公司全名"""
decoded_bytes = [byte_D375D5[b] for b in byte_D375B61]
return bytes(decoded_bytes).decode('latin1')
def to_confuse(s):
"""字符替换规则"""
s = s.upper()
return s.replace('_', '+').replace('.', ';').replace('6', ';')
def generate_key(version):
# 常量定义
COMPANY_SHORT = "TianJi" # 伪代码中硬编码的短名称
DATE_STRING = "20140516" # 伪代码中插入的日期
# 1. 解码公司全名
company_full = decode_company_name() # 结果为"TianJi Information Technology Inc."
# 2. 处理版本号(去掉最后的小版本)
version_main = version[:version.rfind('.')] if '.' in version else version
# 3. 构建第一阶段字符串
phase1_str = f"hello{COMPANY_SHORT},world{company_full}"
# 4. 字符混淆处理
processed_phase1 = to_confuse(phase1_str)
# 5. 第一次MD5
md5_phase1 = hashlib.md5(processed_phase1.encode('utf-8')).hexdigest()
# 6. 构建第二阶段字符串
phase2_str = f"{md5_phase1}{DATE_STRING}{version_main}{COMPANY_SHORT}"
# 7. 二次混淆处理
processed_phase2 = to_confuse(phase2_str)
# 8. 反转字符串
reversed_str = processed_phase2[::-1]
# 9. 最终MD5生成密钥
final_key = hashlib.md5(reversed_str.encode('utf-8')).hexdigest()
return final_key
if __name__ == "__main__":
# 测试输出
test_version = "2.1.0.0"
print(f"Version: {test_version}")
print(f"Generated Key: {generate_key(test_version)}")
print(f"Company Name1: {decode_company_name1()}")
# 验证解码结果
print(f"\nDecoded Company Name: {decode_company_name()}")
Okay, I’m sorry.
Thank you very much for the script and the “subs” functions. I will analyze them further and try to understand them. I did some tests but without success.I will continue trying, and if I manage to get something working, I’ll let you know here and explain how I did it.
Assets in case you want to try. assets.zip
拿之前的改一下就行。
import sys
import struct
import lz4.block
S_XXTEA_KEY = b"\xd2\x22\x82\x7f\xe9\xd3\x72\xa5\x24\x90\x8c\x6d\x0a\x96\xcb\xa3"
XXTEA_LZ4 = 33 # '!'
XXTEA = 101 # 'e'
LZ4 = 122 # 'z'
def to_words(d):
nw = (len(d) + 3) // 4
return list(struct.unpack(f"<{nw}I", d.ljust(nw * 4, b"\0")))
def to_bytes(w):
return struct.pack(f"<{len(w)}I", *w)
def tj_xxtea_decrypt(d, dk):
DELTA = 0x9E3779B9
v = to_words(d)
k = to_words(dk)
n = len(v)
if n <= 1:
return to_bytes(v)
sv = (DELTA * (6 + 52 // n)) & 0xFFFFFFFF
while sv != 0:
e = (sv >> 2) & 3
y = v[0]
for p in range(n - 1, 0, -1):
z = v[p - 1]
mx = (((z >> 5) ^ (y << 2)) + ((y >> 3) ^ (z << 4))) & 0xFFFFFFFF
dkp = ((sv ^ y) + (k[(p & 3) ^ e] ^ z)) & 0xFFFFFFFF
v[p] = (v[p] - (mx ^ dkp)) & 0xFFFFFFFF
y = v[p]
z = v[n - 1]
mx = (((z >> 5) ^ (y << 2)) + ((y >> 3) ^ (z << 4))) & 0xFFFFFFFF
dkp = ((sv ^ y) + (k[(0 & 3) ^ e] ^ z)) & 0xFFFFFFFF
v[0] = (v[0] - (mx ^ dkp)) & 0xFFFFFFFF
sv = (sv - DELTA) & 0xFFFFFFFF
return to_bytes(v)
def decrypt_tj(i, o):
with open(i, "rb") as f:
enc = f.read()
if enc[:2] != b"tj":
return
type = enc[2]
if type in (XXTEA_LZ4, XXTEA):
us = struct.unpack("<I", enc[19:23])[0]
x_dec = tj_xxtea_decrypt(
enc[23:], bytes([S_XXTEA_KEY[i] ^ enc[3:19][i] for i in range(16)])
)
if len(x_dec) >= 4:
nw = len(x_dec) // 4
lw = struct.unpack("<I", x_dec[-4:])[0]
tl = len(x_dec)
if lw >= tl - 7 and lw <= tl - 4:
x_dec = x_dec[:lw]
if type == XXTEA:
dec = x_dec
elif type == XXTEA_LZ4:
dec = lz4.block.decompress(x_dec[4:], uncompressed_size=us)
elif type == LZ4:
dec = lz4.block.decompress(
enc[7:], uncompressed_size=struct.unpack("<I", enc[3:7])[0]
)
with open(o, "wb") as f:
f.write(dec)
if __name__ == "__main__":
decrypt_tj(sys.argv[1], "dec")
1 个赞
I’m sorry to bother you if you don’t want to talk, but I have another library from the same company, it was just distributed by a different company, and the keys I’m testing don’t seem to work.
Am I doing something wrong or am I missing something to find the key?
S_XXTEA_KEY (hex): c88bd0acf2cb8597d6fd85395562d7bf
If you can’t help, I understand. You’ve already helped me so much, and I will be eternally grateful to you.
https:// drive. google. com /file/d/19Ne7uedyBi-MPSzNuNSuv5naeQdT56-N/view?usp=sharing
https:// drive .google. com/file/d/1_zC9GnqcprGw0Hg17FLSbqAATpOSC5Ly/view?usp=drive_link
Sorry friends, I’m back.
I managed to decode it.![]()
The script is below.
Thank you for your help, without you I wouldn’t have gotten anywhere, I was looking at other functions and other things, you are true gods.
I only have one problem: I can decode all files with “tje”, but no other files that start with “tj!”
Can anyone see what’s wrong?
Edit3: It will no longer be necessary; with the key I obtained, I can decrypt it using tj_xxtea_decrypt.exe ![]()
Thanksss!!!
Traceback (most recent call last):
File "C:\Users\SuperFast\Downloads\tj_xxtea_decrypt\endless\c.py", line 113, in <module>
tj_decrypt_file(inp, out, version="2.1.0.0")
~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\SuperFast\Downloads\tj_xxtea_decrypt\endless\c.py", line 94, in tj_decrypt_file
dec = lz4.block.decompress(x[4:], uncompressed_size=us)
_block.LZ4BlockError: Decompression failed: corrupt input or insufficient space in destination buffer. Error code: 6137
# tj_dec.py
import sys, struct, hashlib
import lz4.block
MAP6 = "TianJi"
MAP34 = "TianJi Information Technology Inc."
DATE = "20460310"
def up_rules(s: str) -> str:
return s.upper().replace('_','+').replace('.',';').replace('6',';')
def md5_hex(s: str) -> str: return hashlib.md5(s.encode()).hexdigest()
def md5_raw(s: str) -> bytes: return hashlib.md5(s.encode()).digest()
def derive_s_xxtea_key(version_full: str) -> bytes:
# Fase 1
s1 = "cocos" + MAP6 + "appver" + MAP34
m1 = md5_hex(up_rules(s1))
# Fase 2
vmain = version_full[:version_full.rfind('.')] if '.' in version_full else version_full
s2p = up_rules(m1 + DATE + vmain + MAP6)[::-1]
m2 = md5_hex(s2p)
# Final: md5(reverse(m2)) em BYTES
return md5_raw(m2[::-1])
def to_words_le(b: bytes):
n = (len(b)+3)//4
return list(struct.unpack("<%dI"%n, b.ljust(n*4, b"\0")))
def from_words_le(v):
return struct.pack("<%dI"%len(v), *v)
def xxtea_decrypt(data: bytes, key16: bytes) -> bytes:
DELTA = 0x9E3779B9
v = to_words_le(data)
k = to_words_le(key16)
n = len(v)
if n <= 1:
return from_words_le(v)
sv = (DELTA * (6 + 52//n)) & 0xFFFFFFFF
while sv != 0:
e = (sv >> 2) & 3
y = v[0]
for p in range(n-1, 0, -1):
z = v[p-1]
mx = (((z>>5) ^ (y<<2)) + ((y>>3) ^ (z<<4))) & 0xFFFFFFFF
dkp= ((sv ^ y) + (k[(p & 3) ^ e] ^ z)) & 0xFFFFFFFF
v[p] = (v[p] - (mx ^ dkp)) & 0xFFFFFFFF
y = v[p]
z = v[n-1]
mx = (((z>>5) ^ (y<<2)) + ((y>>3) ^ (z<<4))) & 0xFFFFFFFF
dkp= ((sv ^ y) + (k[(0 & 3) ^ e] ^ z)) & 0xFFFFFFFF
v[0] = (v[0] - (mx ^ dkp)) & 0xFFFFFFFF
sv = (sv - DELTA) & 0xFFFFFFFF
return from_words_le(v)
def detect(data: bytes) -> str:
if data.startswith(b"\x89PNG\r\n\x1a\n"): return "PNG"
if data.startswith(b"\xFF\xD8\xFF"): return "JPEG"
if data.startswith(b"RIFF") and data[8:12]==b"WEBP": return "WEBP"
if data[:4]==b"PK\x03\x04": return "ZIP"
if data[:4]==b"\x04\x22\x4D\x18": return "LZ4 frame"
if data[:2] in (b"\x78\x9C", b"\x78\x01"): return "zlib"
if data[:4]==b"PVR\x03": return "PVRv3"
return "unknown"
def tj_decrypt_file(inp: str, outp: str, version="2.1.0.0"):
with open(inp, "rb") as f:
enc = f.read()
if enc[:2] != b"tj":
raise SystemExit("Not a tj file")
t = enc[2] # tipo: 101='e'(XXTEA), 33='!'(XXTEA+LZ4), 122='z'(LZ4)
salt = enc[3:19] # 16 bytes
# tamanho descompactado:
us = struct.unpack("<I", enc[19:23])[0] if len(enc) >= 23 else 0
payload = enc[23:]
S = derive_s_xxtea_key(version)
dk = bytes([S[i] ^ salt[i] for i in range(16)])
if t == 101: # 'e' XXTEA
x = xxtea_decrypt(payload, dk)
# tail-length heuristic (últimos 4 bytes podem apontar tamanho real)
if len(x) >= 4:
lw = struct.unpack("<I", x[-4:])[0]
if (len(x)-7) <= lw <= (len(x)-4):
x = x[:lw]
dec = x
elif t == 33: # '!' XXTEA + LZ4
x = xxtea_decrypt(payload, dk)
# drop u32 length prefix before LZ4 block, se presente
dec = lz4.block.decompress(x[4:], uncompressed_size=us)
elif t == 122: # 'z' só LZ4
dec = lz4.block.decompress(payload, uncompressed_size=us)
else:
raise SystemExit(f"Tipo desconhecido: {t}")
with open(outp, "wb") as f:
f.write(dec)
kind = detect(dec)
print(f"WROTE: {outp}")
print(f"TYPE: {kind}")
print(f"USED S_XXTEA_KEY: {S.hex()}")
print(f"USED DERIVED DK: {dk.hex()}")
if __name__ == "__main__":
inp = sys.argv[1]
out = inp + ".dec"
tj_decrypt_file(inp, out, version="2.1.0.0")
刚睡醒,我跳过了根据公司名生成key的步骤,直接hook的,解密的代码直接根据initwithimage里面的来写就行,改动都不大
1 个赞
这个其实就只是他把一些步骤单独写入了几个函数
并且也将公司字符串加密了而已
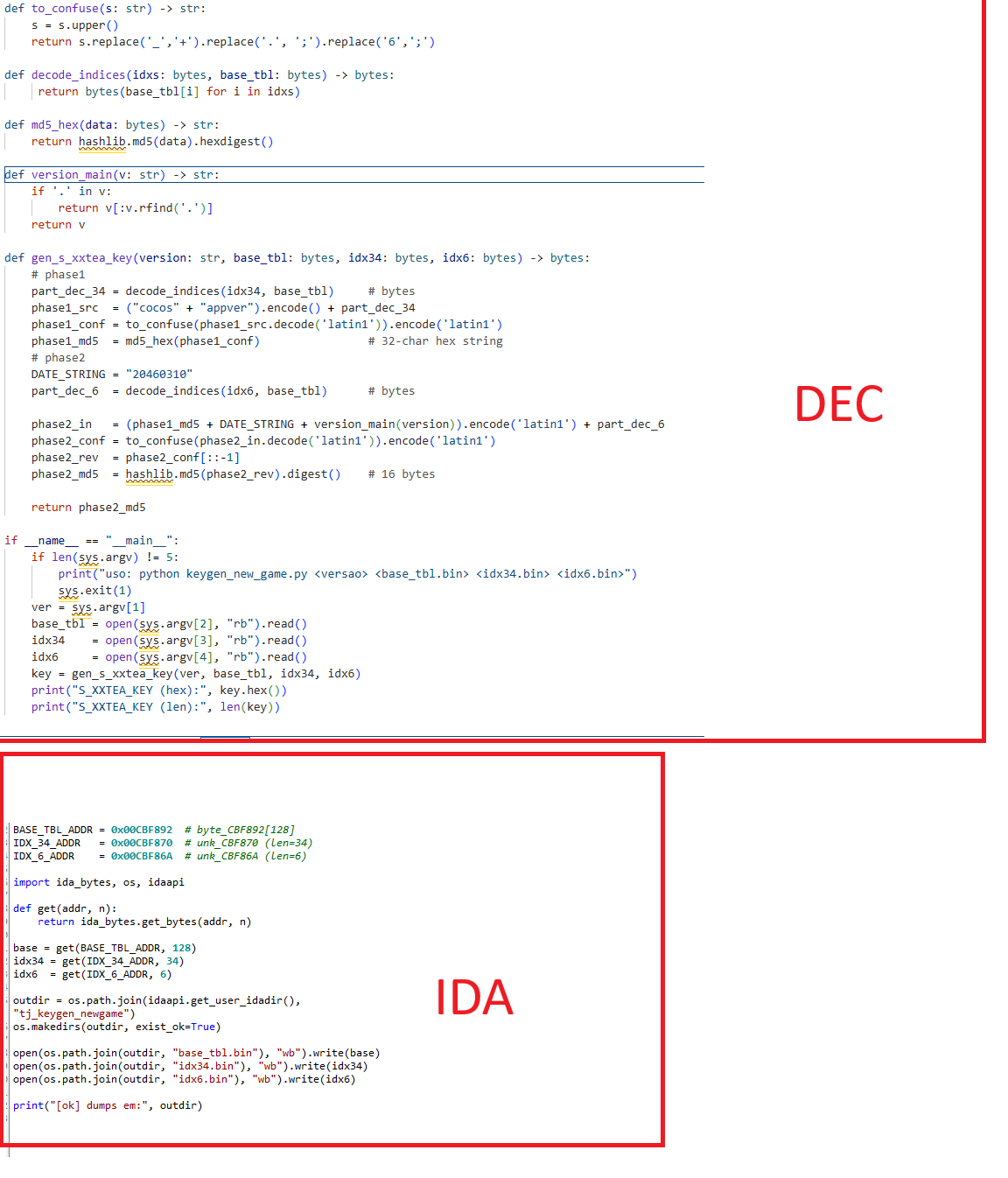
在AppDelegate::AppDelegate你可以看到他在设置好tj版本号后调用了sub_369C50
然后可以看到拼接字符串的两个常量字符串
对应解密代码的
phase1_str = f"hello{COMPANY_SHORT},world{company_full}"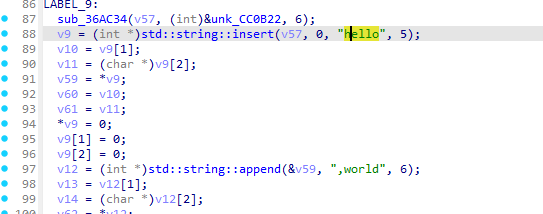
在看看之前我发的一些分析可以知道公司短名在拼接字符串前就做完了所以着重看一下sub_36AC34的实现
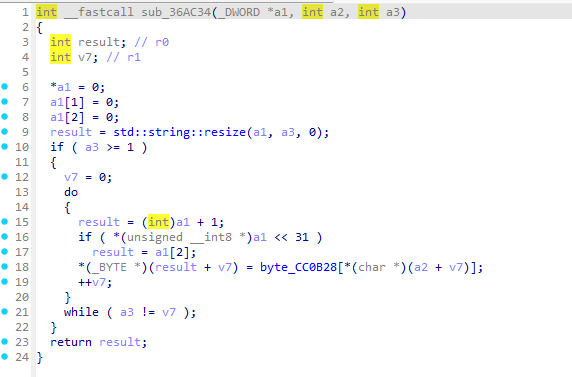
可以看到sub_36AC34其实就是使用密钥编码表来解密某个字符串
这里的密码表是
unsigned char byte_CC0B28[] =
{
0x15, 0x28, 0x69, 0x79, 0x7C, 0x3E, 0x0B, 0x21, 0x36, 0x6F,
0x66, 0x4E, 0x62, 0x2D, 0x77, 0x60, 0x73, 0x2A, 0x29, 0x0D,
0x44, 0x37, 0x6B, 0x5C, 0x00, 0x5A, 0x0F, 0x0C, 0x5E, 0x64,
0x1A, 0x65, 0x57, 0x6E, 0x4D, 0x7A, 0x47, 0x74, 0x40, 0x43,
0x02, 0x72, 0x45, 0x18, 0x5F, 0x32, 0x10, 0x08, 0x71, 0x11,
0x16, 0x6C, 0x30, 0x17, 0x14, 0x4B, 0x05, 0x63, 0x25, 0x35,
0x7F, 0x1E, 0x3B, 0x26, 0x01, 0x0E, 0x6A, 0x59, 0x13, 0x09,
0x2B, 0x50, 0x70, 0x03, 0x27, 0x53, 0x5B, 0x5D, 0x56, 0x68,
0x54, 0x2F, 0x23, 0x6D, 0x2C, 0x46, 0x1B, 0x4A, 0x12, 0x78,
0x1C, 0x4C, 0x4F, 0x61, 0x75, 0x51, 0x3F, 0x52, 0x20, 0x67,
0x39, 0x04, 0x48, 0x24, 0x55, 0x34, 0x31, 0x33, 0x3D, 0x22,
0x76, 0x42, 0x7D, 0x1D, 0x1F, 0x06, 0x7B, 0x2E, 0x3C, 0x0A,
0x58, 0x19, 0x41, 0x7E, 0x38, 0x3A, 0x49, 0x07
};
而加密的字符串表是传入的第二个参数a2
回到上级函数查看调用方法
sub_36AC34(v57, (int)&unk_CC0B22, 6);
那么可以知道unk_CC0B22是一个加密的字符串编码表
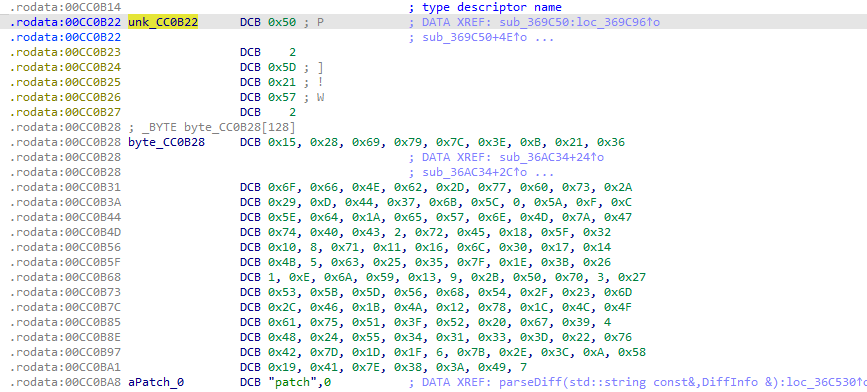
unsigned char unk_CC0B22[] =
{
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02
};
使用python代码可以解密
def decode_str():
decoded_bytes = [byte_CC0B28[b] for b in unk_CC0B22]
return bytes(decoded_bytes).decode('latin1')
可以得到公司名 TianJi
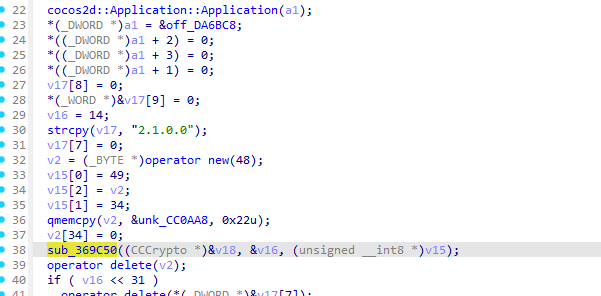
继续分析可以看到他再次调用了sub_36AC34
这次就是公司全名解码了
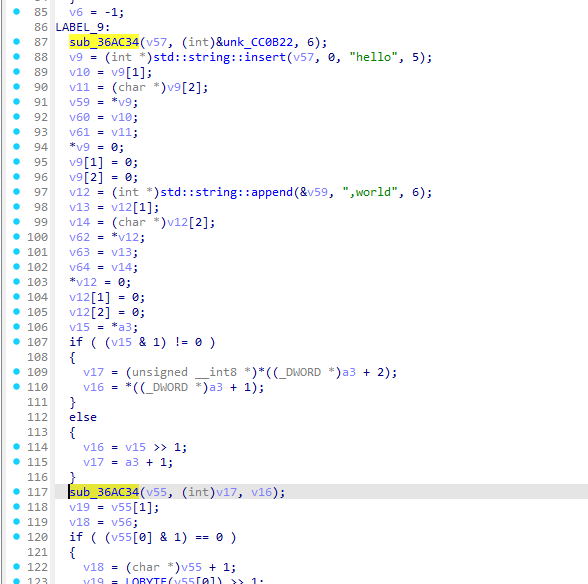
但是这次传入的参数并不是加密码表的指针而是一个基于a3的指针而a3是sub_369C50的第三个参数
int __fastcall sub_369C50(CCCrypto *a1, unsigned __int8 *a2, unsigned __int8 *a3)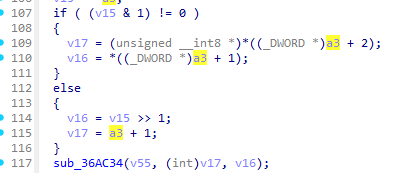
回到AppDelegate::AppDelegate查看sub_369C50的调用方法
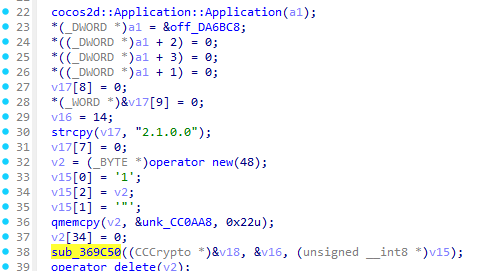
可以看到v15并没有什么有价值的东西
但是我们看到了
qmemcpy(v2, &unk_CC0AA8, 0x22u);这或许是IDA不能完美反汇编ARM的问题这里的unk_CC0AA8实际上才是加密的公司全名编码表
unsigned char unk_CC0AA8[] =
{
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02, 0x62, 0x7E, 0x21, 0x0A,
0x09, 0x29, 0x53, 0x5D, 0x25, 0x02, 0x09, 0x21, 0x62, 0x50,
0x1F, 0x39, 0x4F, 0x21, 0x09, 0x33, 0x09, 0x63, 0x03, 0x62,
0x7E, 0x21, 0x39, 0x75, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00
};
这里我们注意到unk_CC0AA8的长度为0x28(40)
而qmemcpy只复制0x22(34)长度
所以最终我们只保留
unsigned char unk_CC0AA8[] =
{
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02, 0x62, 0x7E, 0x21, 0x0A,
0x09, 0x29, 0x53, 0x5D, 0x25, 0x02, 0x09, 0x21, 0x62, 0x50,
0x1F, 0x39, 0x4F, 0x21, 0x09, 0x33, 0x09, 0x63, 0x03, 0x62,
0x7E, 0x21, 0x39, 0x75
};
继续分析sub_369C50就能看到日期位的字符串常量注意这里不一定是这种日期格式也有一些公司喜欢改成其他字符串
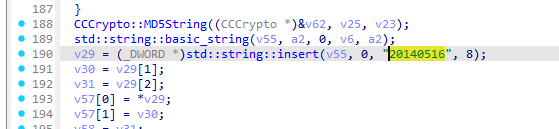
所以最终的密钥生成代码是
import hashlib
unk_CC0AA8 = [
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02, 0x62, 0x7E, 0x21, 0x0A,
0x09, 0x29, 0x53, 0x5D, 0x25, 0x02, 0x09, 0x21, 0x62, 0x50,
0x1F, 0x39, 0x4F, 0x21, 0x09, 0x33, 0x09, 0x63, 0x03, 0x62,
0x7E, 0x21, 0x39, 0x75
]
unk_CC0B22 = [
0x50, 0x02, 0x5D, 0x21, 0x57, 0x02
]
byte_CC0B28 = [
0x15, 0x28, 0x69, 0x79, 0x7C, 0x3E, 0x0B, 0x21, 0x36, 0x6F,
0x66, 0x4E, 0x62, 0x2D, 0x77, 0x60, 0x73, 0x2A, 0x29, 0x0D,
0x44, 0x37, 0x6B, 0x5C, 0x00, 0x5A, 0x0F, 0x0C, 0x5E, 0x64,
0x1A, 0x65, 0x57, 0x6E, 0x4D, 0x7A, 0x47, 0x74, 0x40, 0x43,
0x02, 0x72, 0x45, 0x18, 0x5F, 0x32, 0x10, 0x08, 0x71, 0x11,
0x16, 0x6C, 0x30, 0x17, 0x14, 0x4B, 0x05, 0x63, 0x25, 0x35,
0x7F, 0x1E, 0x3B, 0x26, 0x01, 0x0E, 0x6A, 0x59, 0x13, 0x09,
0x2B, 0x50, 0x70, 0x03, 0x27, 0x53, 0x5B, 0x5D, 0x56, 0x68,
0x54, 0x2F, 0x23, 0x6D, 0x2C, 0x46, 0x1B, 0x4A, 0x12, 0x78,
0x1C, 0x4C, 0x4F, 0x61, 0x75, 0x51, 0x3F, 0x52, 0x20, 0x67,
0x39, 0x04, 0x48, 0x24, 0x55, 0x34, 0x31, 0x33, 0x3D, 0x22,
0x76, 0x42, 0x7D, 0x1D, 0x1F, 0x06, 0x7B, 0x2E, 0x3C, 0x0A,
0x58, 0x19, 0x41, 0x7E, 0x38, 0x3A, 0x49, 0x07
]
def decode_company_name():
decoded_bytes = [byte_CC0B28[b] for b in unk_CC0AA8]
return bytes(decoded_bytes).decode('latin1')
def decode_company_names():
decoded_bytes = [byte_CC0B28[b] for b in unk_CC0B22]
return bytes(decoded_bytes).decode('latin1')
def to_confuse(s):
s = s.upper()
return s.replace('_', '+').replace('.', ';').replace('6', ';')
def generate_key(version):
COMPANY_SHORT = str(decode_company_names())
DATE_STRING = "20140516"
company_full = decode_company_name()
version_main = version[:version.rfind('.')] if '.' in version else version
phase1_str = f"hello{COMPANY_SHORT},world{company_full}"
processed_phase1 = to_confuse(phase1_str)
md5_phase1 = hashlib.md5(processed_phase1.encode('utf-8')).hexdigest()
phase2_str = f"{md5_phase1}{DATE_STRING}{version_main}{COMPANY_SHORT}"
processed_phase2 = to_confuse(phase2_str)
reversed_str = processed_phase2[::-1]
final_key = hashlib.md5(reversed_str.encode('utf-8')).hexdigest()
return final_key
if __name__ == "__main__":
# 测试输出
test_version = "2.1.0.0"
print(f"Version: {test_version}")
print(f"Generated Key: {generate_key(test_version)}")
# 验证解码结果
print(f"\nDecoded Company Full Name: {decode_company_name()}")
print(f"Decoded Company Name: {decode_company_names()}")
得到的结果
Version: 2.1.0.0
Generated Key: d222827fe9d372a524908c6d0a96cba3
Decoded Company Full Name: TianJi Information Technology Inc.
Decoded Company Name: TianJi
1 个赞
如果他s_xxteaKey没有被处理的话我觉得dump更快,直接出结果免去上面的步骤,哪怕是处理了改改脚本也能继续dump
const LIB = "libcocos2dlua.so";
const poll = setInterval(function() {
if (Process.findModuleByName(LIB)) {
clearInterval(poll);
Interceptor.attach(Process.findModuleByName(LIB).base.add(0x96A39C), {
onLeave: function(ret) {
const key = Module.findExportByName(LIB, "_ZN7cocos2d9FileUtils10s_xxteaKeyE");
const keyLen = Module.findExportByName(LIB, "_ZN7cocos2d9FileUtils13s_xxteaKeyLenE");
console.log(hexdump(key.readPointer(), {
offset: 0,
length: keyLen.readInt(),
header: false,
ansi: true
}));
Interceptor.detachAll();
}
});
}
}, 300);
1 个赞
确实是dump最快也方便
但是我没有安卓设备使用模拟器一hook就卡死崩溃 ![]()
手机上有些游戏也是一hook就闪退
I also have tackled this, and gained the same xxtea_key(using CE), but I can’t decrypt any file at all.
Does anyone know about it?(Sorry for not using Chinese)
发送二进制文件和适量的加密文件样本
Good evening.
Am I picking up the key correctly?
libcocos2dlua.zip (5.2 MB)
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import hashlib
# LUT de 128 (byte_CAE53C)
# ( .rodata;)
BYTE_CAE53C = bytes([
0x15,0x28,0x69,0x79,0x7C,0x3E,0x0B,0x21,0x36,0x6F,0x66,0x4E,0x62,0x2D,0x77,0x60,
0x73,0x2A,0x29,0x0D,0x44,0x37,0x6B,0x5C,0x00,0x5A,0x0F,0x0C,0x5E,0x64,0x1A,0x65,
0x57,0x6E,0x4D,0x7A,0x47,0x74,0x40,0x43,0x02,0x72,0x45,0x18,0x5F,0x32,0x10,0x08,
0x71,0x11,0x16,0x6C,0x30,0x17,0x14,0x4B,0x05,0x63,0x25,0x35,0x7F,0x1E,0x3B,0x26,
0x01,0x0E,0x6A,0x59,0x13,0x09,0x2B,0x50,0x70,0x03,0x27,0x53,0x5B,0x5D,0x56,0x68,
0x54,0x2F,0x23,0x6D,0x2C,0x46,0x1B,0x4A,0x12,0x78,0x1C,0x4C,0x4F,0x61,0x75,0x51,
0x3F,0x52,0x20,0x67,0x39,0x04,0x48,0x24,0x55,0x34,0x31,0x33,0x3D,0x22,0x76,0x42,
0x7D,0x1D,0x1F,0x06,0x7B,0x2E,0x3C,0x0A,0x58,0x19,0x41,0x7E,0x38,0x3A,0x49,0x07
])
# Síndices) BYTE_CAE53C
# unk_CAE500 (12 bytes) unk_CAE50C (48 bytes)
UNK_CAE500 = bytes([0x73,0x1D,0x56,0x21,0x63,0x16, 0x73,0x1D,0x56,0x21,0x63,0x16])
UNK_CAE50C = bytes([
0x29,0x57,0x47,0x7F,0x7E,0x21,0x14,0x09,0x29,0x53,0x5D,0x25,0x02,0x09,0x21,0x62,
0x50,0x1F,0x39,0x4F,0x21,0x09,0x33,0x09,0x63,0x03,0x62,0x7E,0x21,0x39,0x75,0x6F,
0x4E,0x1F,0x39,0x37,0x21,0x09,0x33,0x09,0x63,0x03,0x62,0x7E,0x21,0x39,0x75,0x7A
])
# nanoILLCPHtp XOR
BYTE_CAE4C0 = bytes([0x29,0x4F,0x43,0x13,0x23,0x12,0x14,0x1A,0x50,0x2A,0x0B,0x16,0x12,0x08,0x09,0x06])
# 161 bytes:
BYTE_CAE41F = bytes([
0xD4,0x8D,0xA9,0xF1,0xEF,0xEF,0xD0,0xF4,0xB5,0xD5,0xDB,0xDF,0xE8,0x92,0xD9,0xC1,
0xD2,0xB2,0x8F,0xFC,0xEF,0xEC,0xCC,0xF6,0xA9,0xE9,0xF9,0xD7,0xD8,0xCC,0xEB,0xDD,
0xD8,0xD5,0xDE,0xE8,0xEA,0xFD,0xFA,0xEA,0xB6,0xDA,0xF1,0xDF,0xEC,0xDA,0xF4,0xD9,
0xD2,0xB2,0xBD,0xF4,0xEF,0xD7,0xF6,0xEB,0xA9,0xEF,0xCB,0xD7,0xD8,0xCD,0xD2,0x00,
0xD3,0xD7,0xA1,0xEE,0xDA,0xF2,0xCC,0xDD,0xA2,0xD5,0x96,0xCD,0xD8,0x92,0x94,0xC0,
0xF1,0x88,0xB1,0xEC,0xBE,0xC9,0xDE,0xC2,0x97,0xD8,0xF4,0x8B,0xC9,0xC2,0xD1,0x00,
0xF1,0x88,0xB1,0xEC,0xBE,0xC9,0xDE,0xC2,0x97,0xD8,0xF4,0x8B,0xC9,0xC2,0xD1,0x00,
0xF2,0x85,0x9B,0xD4,0xD1,0xED,0x89,0xDD,0xA2,0xD5,0x96,0xCD,0xD8,0xCF,0xFB,0xF9,
0xB4,0x94,0x89,0xC8,0xE9,0xCA,0xD3,0xDD,0xA2,0xD5,0x96,0xCD,0xD8,0xFA,0xF6,0x00,
0xB7,0xC9,0xD3,0x95,0xBA,0x94,0x85,0x00,0xB3,0xD7,0xD9,0x89,0xBA,0x8A,0x8D,0x8B,
0x00
])
S_PREFIX1 = "finalFantaAngoda"
S_SUFFIX1 = ",coLTDMAXASSiT"
DATE_STR = "20221111"
DEFAULT_VERSION = "4.0.1.1"
def map_with_lut(idx_bytes: bytes) -> bytes:
return bytes(BYTE_CAE53C[b & 0x7F] for b in idx_bytes)
def to_confuse(s: str) -> str:
"""sub_3A9AAE: upper + substituições .,_ ,6."""
out = []
for ch in s:
o = ch
if 'a' <= o <= 'z':
o = o.upper()
elif o == '.' or o == '6':
o = ';'
elif o == '_':
o = '+'
out.append(o)
return ''.join(out)
def rev_inplace(s: str) -> str:
""" sub_3AB2C2 (reverse)."""
return s[::-1]
def md5_hex(data: bytes) -> str:
return hashlib.md5(data).hexdigest()
def strip_last_dot(ver: str) -> str:
"""std::string::rfind('.', -1) [0..pos)"""
p = ver.rfind('.')
return ver[:p] if p != -1 else ver
# -------------------------------
# 1 (AppDelegate): KEY_A
# -------------------------------
def compute_KEY_A(version: str = DEFAULT_VERSION) -> str:
part_A = map_with_lut(UNK_CAE500).decode('latin1', 'ignore')
part_B = map_with_lut(UNK_CAE50C).decode('latin1', 'ignore')
# concatenação completa
s1 = S_PREFIX1 + part_A + S_SUFFIX1 + part_B
# MD5 do fluxo já completo
md5_1 = md5_hex(to_confuse(s1).encode('utf-8'))
version_main = strip_last_dot(version)
s2 = DATE_STR + version_main + part_A
s2_conf = to_confuse(s2)
s2_rev = rev_inplace(s2_conf)
key_a = md5_hex(s2_rev.encode('utf-8'))
return key_a
# -------------------------------
# 2 (nanoILLCPHtp + suDoMonoAssTCP): KEY_B
# -------------------------------
def nanoILLCPHtp():
"""
(dword_D8C5E4/E8/EC/F0/F8/F4).
byte_CAE4C0[i & 0xF] ^ byte_CAE41F[offset + i] ^ 0xA8
LEN: 63,31,15,31,7,8
"""
def fill(count, offset, use_mask=True):
out = bytearray(count)
for i in range(count):
lut = BYTE_CAE4C0[(i & 0xF) if use_mask else i]
out[i] = (lut ^ BYTE_CAE41F[offset + i] ^ 0xA8) & 0xFF
return bytes(out)
# offsets
blk_F0 = fill(63, 0, True) # dword_D8C5F0
blk_E8 = fill(31, 64, True) # dword_D8C5E8
blk_E4 = fill(15, 96, False) # dword_D8C5E4 (not use &0xF)
blk_EC = fill(31,112, True) # dword_D8C5EC
blk_F8 = fill(7, 144, False) # dword_D8C5F8
blk_F4 = fill(8, 152, False) # dword_D8C5F4
return blk_E4, blk_E8, blk_EC, blk_F0, blk_F8, blk_F4
def compute_KEY_B():
"""
suDoMonoAssTCP:
stream1 = E4 + E8 + EC + F0
md5_1 = MD5( to_confuse(stream1) )
stream2 = md5_1 + F4 + E8
KEY_B = MD5( reverse( to_confuse(stream2) ) )
"""
blk_E4, blk_E8, blk_EC, blk_F0, _blk_F8, blk_F4 = nanoILLCPHtp()
# stream 1
s1 = (blk_E4 + blk_E8 + blk_EC + blk_F0).decode('latin1', 'ignore')
s1_conf = to_confuse(s1)
md5_1 = md5_hex(s1_conf.encode('utf-8'))
# stream 2 (ordem coerente com os << capturados)
s2 = md5_1 + blk_F4.decode('latin1','ignore') + blk_E8.decode('latin1','ignore')
s2_conf = to_confuse(s2)
s2_rev = rev_inplace(s2_conf)
key_b = md5_hex(s2_rev.encode('utf-8'))
return key_b
if __name__ == "__main__":
from binascii import unhexlify
key_a = compute_KEY_A()
key_b = compute_KEY_B()
ver = "4.0.1.1"
combo_md5 = hashlib.md5((key_a + key_b).encode()).hexdigest()
xor_key = bytes(a ^ b for a, b in zip(unhexlify(key_a), unhexlify(key_b)))
print("KEY_A:", key_a)
print("KEY_B:", key_b)
print("MD5(A+B):", combo_md5)
print("XOR16:", xor_key.hex())
Version: 4.0.1.1
Generated Key: c2a3603c1bd99f7bbd137369fa684f4b
Decoded Company Full Name: rJPaInDormation Technology Inc.BVecKnology Inc.A
Decoded Company Name: dengkdengk
import hashlib
unk_CAE50C = [
0x29, 0x57, 0x47, 0x7F, 0x7E, 0x21, 0x14, 0x09, 0x29, 0x53,
0x5D, 0x25, 0x02, 0x09, 0x21, 0x62, 0x50, 0x1F, 0x39, 0x4F,
0x21, 0x09, 0x33, 0x09, 0x63, 0x03, 0x62, 0x7E, 0x21, 0x39,
0x75, 0x6F, 0x4E, 0x1F, 0x39, 0x37, 0x21, 0x09, 0x33, 0x09,
0x63, 0x03, 0x62, 0x7E, 0x21, 0x39, 0x75, 0x7A
]
unk_CAE500 = [
0x73, 0x1D, 0x56, 0x21, 0x63, 0x16, 0x73, 0x1D, 0x56, 0x21,
0x63, 0x16
]
byte_CAE53C = [
0x15, 0x28, 0x69, 0x79, 0x7C, 0x3E, 0x0B, 0x21, 0x36, 0x6F,
0x66, 0x4E, 0x62, 0x2D, 0x77, 0x60, 0x73, 0x2A, 0x29, 0x0D,
0x44, 0x37, 0x6B, 0x5C, 0x00, 0x5A, 0x0F, 0x0C, 0x5E, 0x64,
0x1A, 0x65, 0x57, 0x6E, 0x4D, 0x7A, 0x47, 0x74, 0x40, 0x43,
0x02, 0x72, 0x45, 0x18, 0x5F, 0x32, 0x10, 0x08, 0x71, 0x11,
0x16, 0x6C, 0x30, 0x17, 0x14, 0x4B, 0x05, 0x63, 0x25, 0x35,
0x7F, 0x1E, 0x3B, 0x26, 0x01, 0x0E, 0x6A, 0x59, 0x13, 0x09,
0x2B, 0x50, 0x70, 0x03, 0x27, 0x53, 0x5B, 0x5D, 0x56, 0x68,
0x54, 0x2F, 0x23, 0x6D, 0x2C, 0x46, 0x1B, 0x4A, 0x12, 0x78,
0x1C, 0x4C, 0x4F, 0x61, 0x75, 0x51, 0x3F, 0x52, 0x20, 0x67,
0x39, 0x04, 0x48, 0x24, 0x55, 0x34, 0x31, 0x33, 0x3D, 0x22,
0x76, 0x42, 0x7D, 0x1D, 0x1F, 0x06, 0x7B, 0x2E, 0x3C, 0x0A,
0x58, 0x19, 0x41, 0x7E, 0x38, 0x3A, 0x49, 0x07
]
def decode_company_name():
decoded_bytes = [byte_CAE53C[b] for b in unk_CAE50C]
return bytes(decoded_bytes).decode('latin1')
def decode_company_names():
decoded_bytes = [byte_CAE53C[b] for b in unk_CAE500]
return bytes(decoded_bytes).decode('latin1')
def to_confuse(s):
s = s.upper()
return s.replace('_', '+').replace('.', ';').replace('6', ';')
def generate_key(version):
COMPANY_SHORT = str(decode_company_names())
DATE_STRING = "20221111"
company_full = decode_company_name()
version_main = version[:version.rfind('.')] if '.' in version else version
phase1_str = f"finalFantaAngoda{COMPANY_SHORT},coLTDMAXASSiT{company_full}"
processed_phase1 = to_confuse(phase1_str)
md5_phase1 = hashlib.md5(processed_phase1.encode('utf-8')).hexdigest()
phase2_str = f"{md5_phase1}{DATE_STRING}{version_main}{COMPANY_SHORT}"
processed_phase2 = to_confuse(phase2_str)
reversed_str = processed_phase2[::-1]
final_key = hashlib.md5(reversed_str.encode('utf-8')).hexdigest()
return final_key
if __name__ == "__main__":
# 测试输出
test_version = "4.0.1.1"
print(f"Version: {test_version}")
print(f"Generated Key: {generate_key(test_version)}")
# 验证解码结果
print(f"\nDecoded Company Full Name: {decode_company_name()}")
print(f"Decoded Company Name: {decode_company_names()}")