一个纯解包萌新,想看看afk的素材
然后尝试去改了版本号
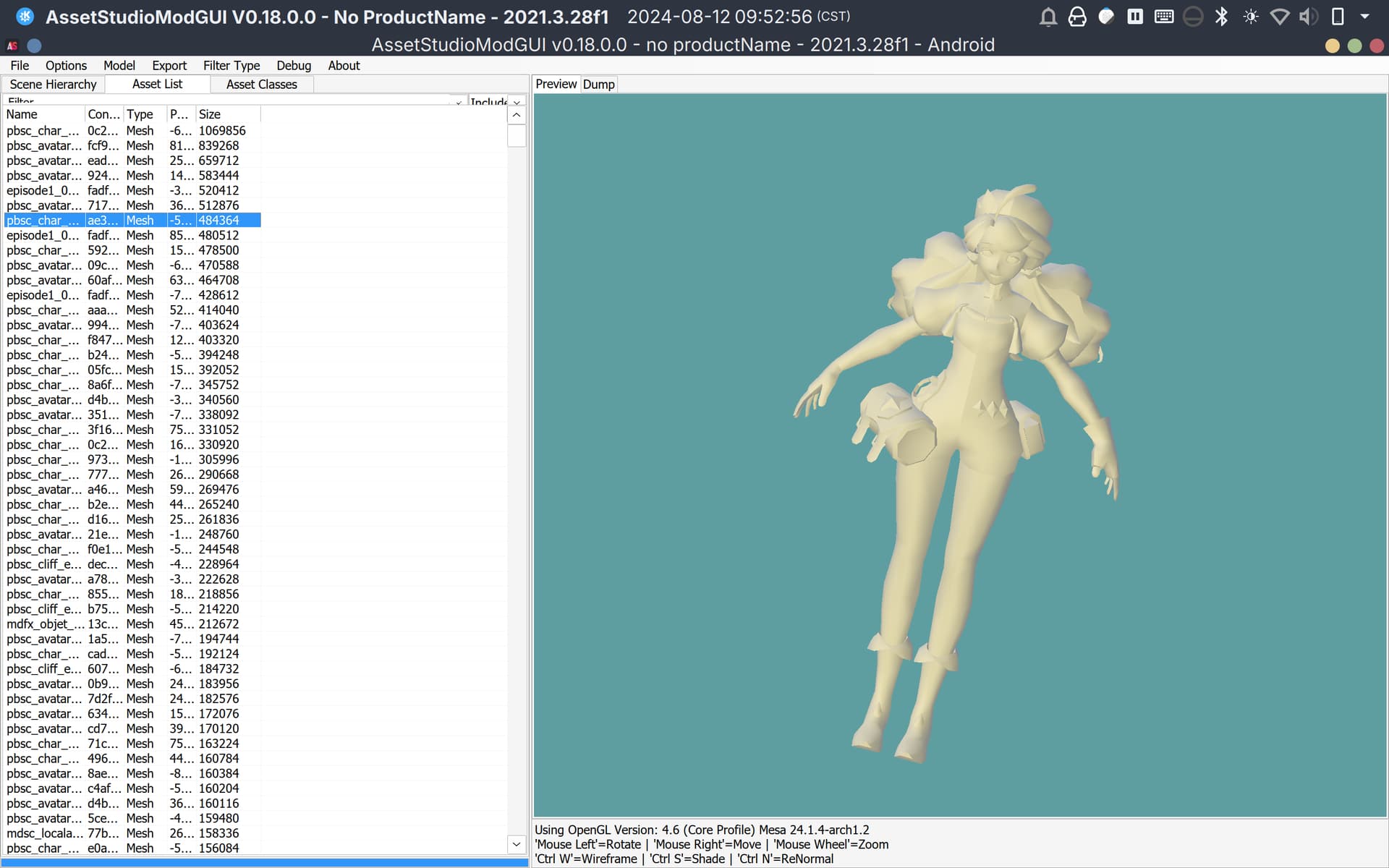
但是一导入AssetStudio里就会报错
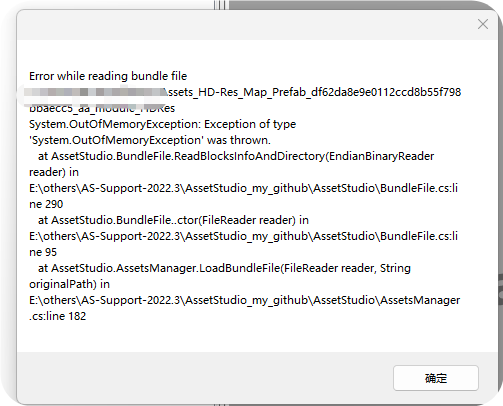
请问有没有大佬知道怎么回事,请求解决办法
一个纯解包萌新,想看看afk的素材
然后尝试去改了版本号
但是一导入AssetStudio里就会报错
请问有没有大佬知道怎么回事,请求解决办法
这是修改前后对比
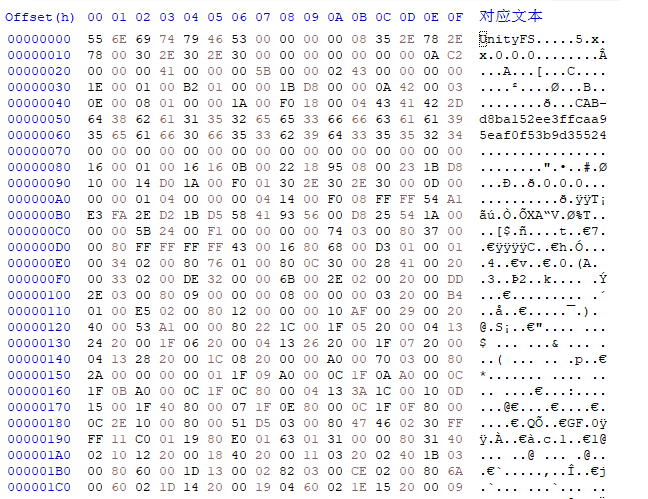
一个个都是神仙,
1.有重复帖子不要再单开帖子问了,发帖之前记得先搜一下有无重复帖子
2.怎么填版本号自己摸一下as别瞎搞,我回在那个afk帖子了
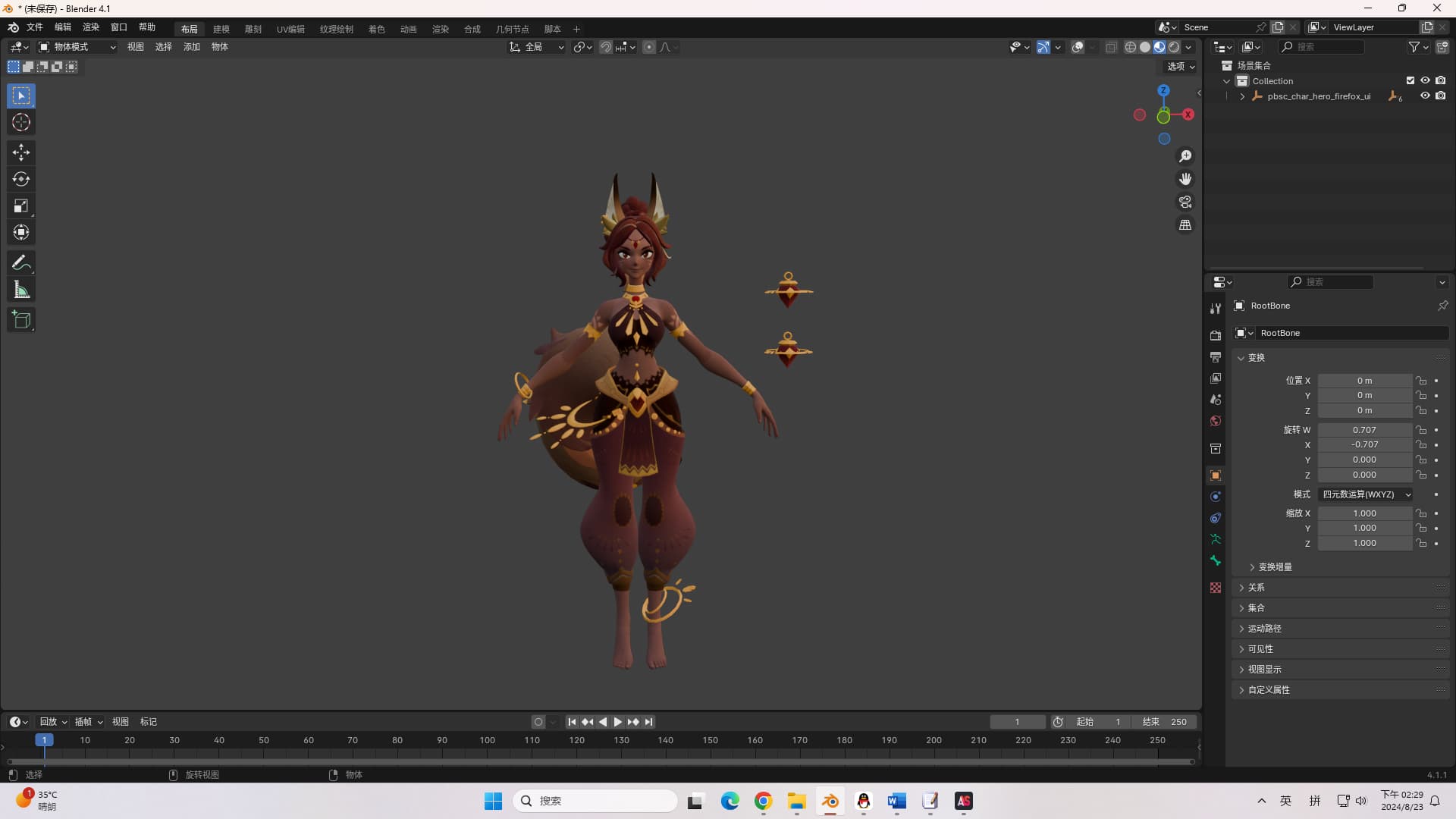
现在我有个新的疑问,就是解开的文件里并没有角色的立绘或者任何角色的3d模型,请问有什么办法吗
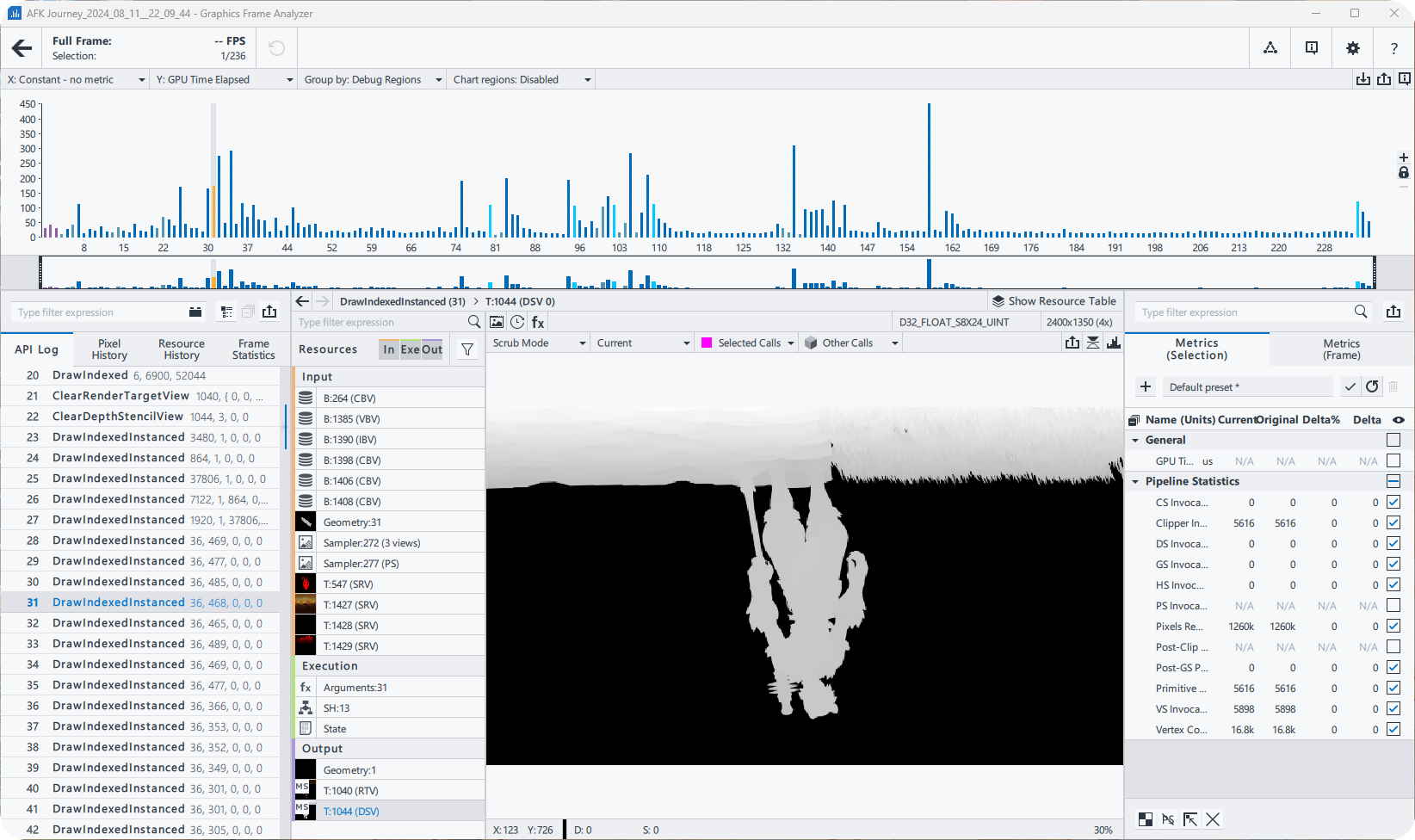
一样的问题,这个gpa是另外的一个解包软件?
抓帧分析用的,跟骁龙那个差不多应该
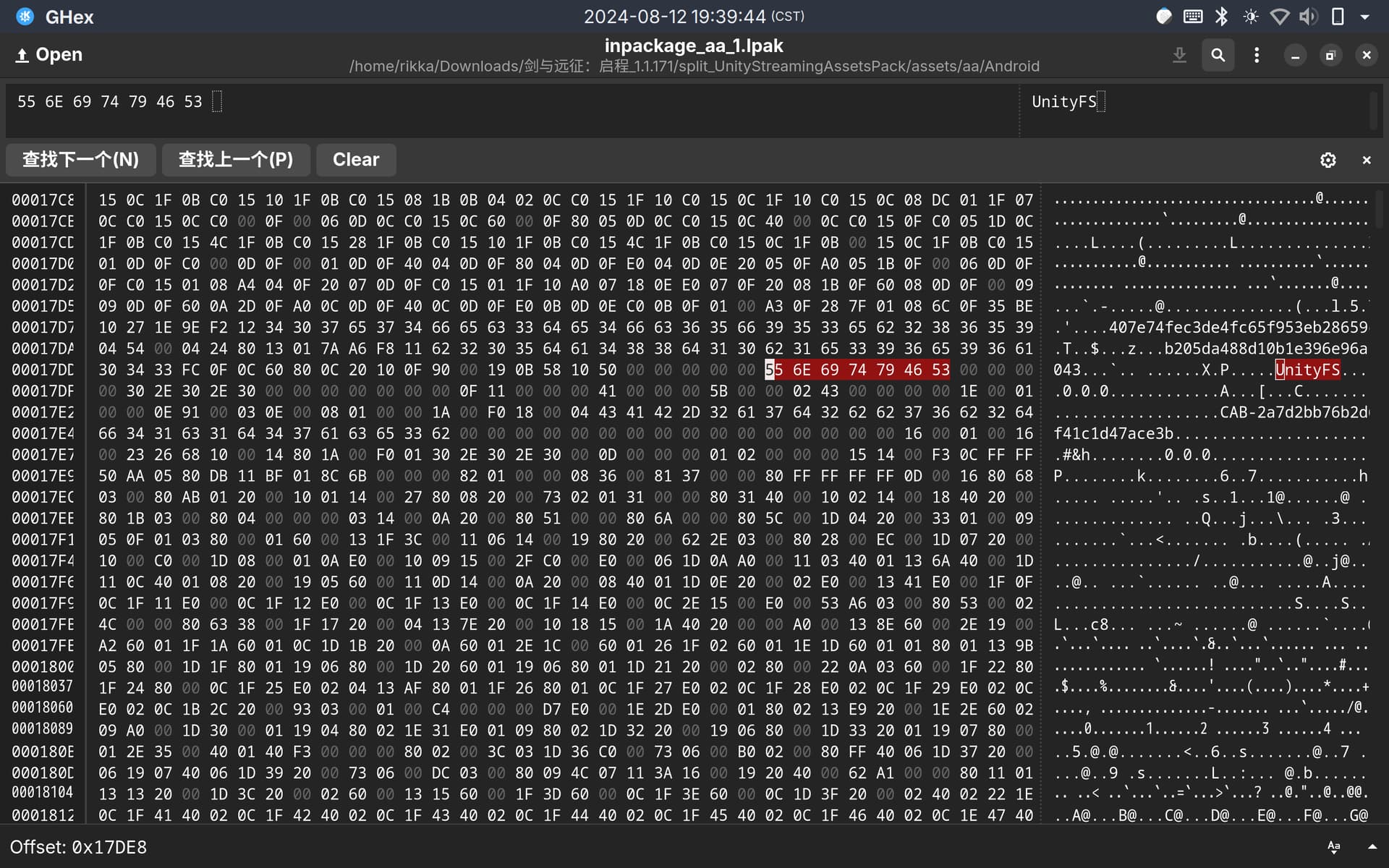
能再详细说一下吗,我翻unitypy的discord上也只讲到你这里,他说了一些工具但我都不会用。论坛上的“星落解包方法”也是ab包连着了,楼主是说有一个json文件记录了每个文件的起始位置和hash key,请问这个游戏也一样吗。

看大佬教程基本搞定了。
多个包合在一起,用python脚本来处理,我自己不会代码,拿AXiX_Official大佬的脚本让chatgpt改成能用的。
然后使用RAZ AssetStudio
Options —> Specify Unity version —>2021.3.28f1
然后就可以正常提取了。
然后我在网上看到别人整理的一张表用来对照资产名称和游戏内名称[AFK Journey Model Name Ref - Google ドキュメント](https://[name list reference for hero models])。
import os
import sys
# 定义特定字节序列(UnityFS)的十六进制表示
SIGNATURE = b"UnityFS"
def extract(file_obj, start_pos, end_pos, output_path, name):
# 将文件指针移动到开始位置
file_obj.seek(start_pos)
# 计算提取数据的大小:从 start_pos 到 end_pos(或文件末尾)
size = end_pos - start_pos
# 读取指定大小的数据
data = file_obj.read(size)
# 保存提取的数据块到指定路径
with open(os.path.join(output_path, name), "wb") as f:
f.write(data)
def find_signatures(file_obj):
positions = []
file_obj.seek(0)
data = file_obj.read()
# 搜索整个文件中签名出现的位置
start_pos = 0
while True:
start_pos = data.find(SIGNATURE, start_pos)
if start_pos == -1:
break
positions.append(start_pos)
start_pos += len(SIGNATURE) # 跳过已找到的签名,继续搜索下一个
return positions
def process_file(file_path, output_folder):
with open(file_path, "rb") as asset_file:
positions = find_signatures(asset_file)
if not os.path.exists(output_folder):
os.makedirs(output_folder)
for idx in range(len(positions)):
start_pos = positions[idx]
# 如果不是最后一个签名,end_pos 是下一个签名的位置
if idx + 1 < len(positions):
end_pos = positions[idx + 1]
else:
# 最后一个签名,end_pos 是文件的末尾
asset_file.seek(0, os.SEEK_END)
end_pos = asset_file.tell()
extract(asset_file, start_pos, end_pos, output_folder, f"{os.path.basename(file_path)}_extracted_{idx}.bin")
print(f"Extraction complete for {file_path}. {len(positions)} files were extracted.")
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: python extract.py <folder_path> <output_path>")
sys.exit(1)
folder_path = sys.argv[1]
output_path = sys.argv[2]
# 遍历文件夹中的所有文件
for root, dirs, files in os.walk(folder_path):
for file_name in files:
file_path = os.path.join(root, file_name)
print(f"Processing file: {file_path}")
process_file(file_path, output_path)
print("All files processed.")