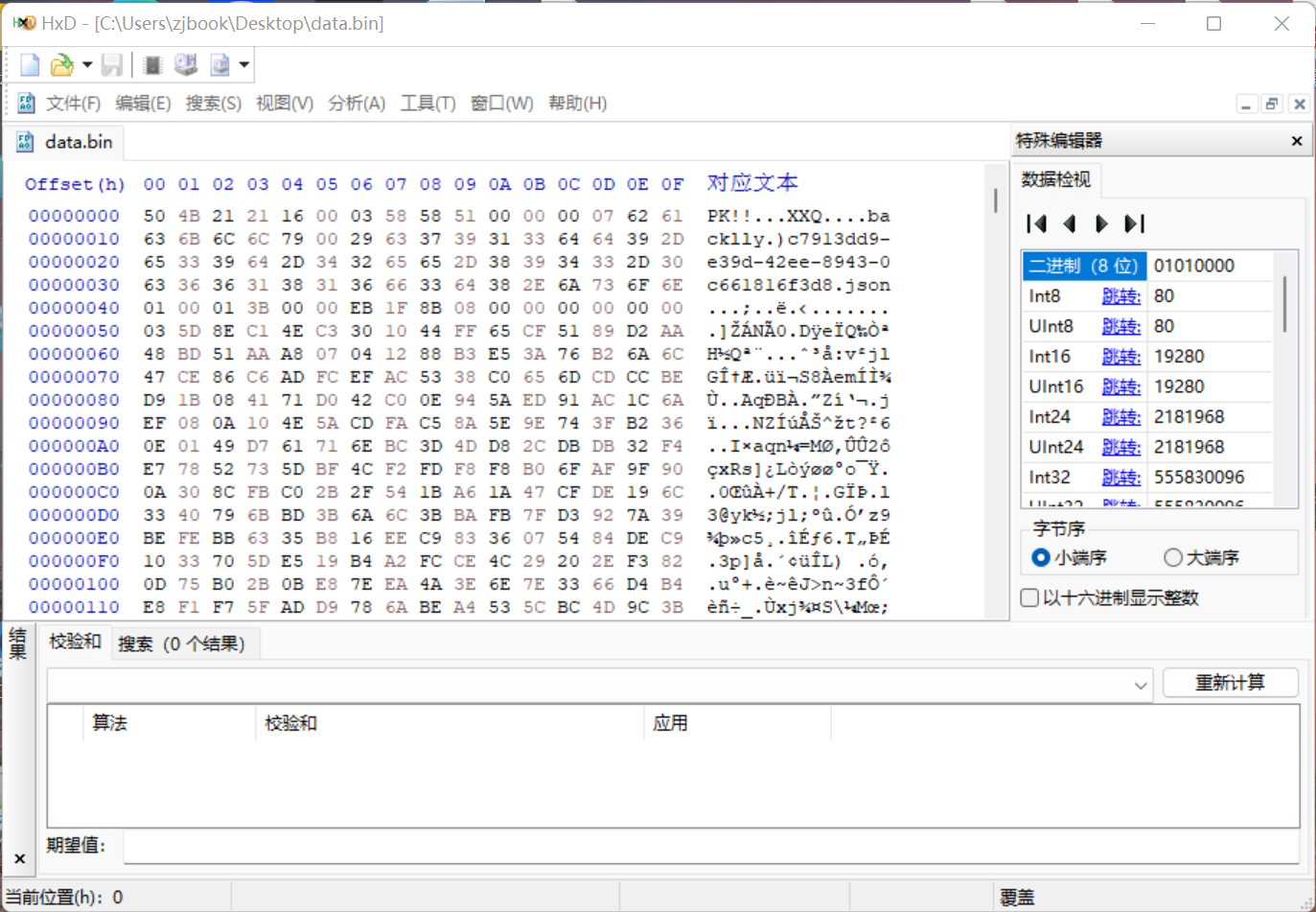
找到l2d少的部分配置文件的位置了,在apk包的res下有个data.bin文件 用十六进制显示查看看到 里面有json这样的文件名称 认为应该就是配置文件了 看到pk以为是压缩包 改zip尝试解压不能成功
分析了一下包内内容 看到里面有明文也有部分乱码 发现乱码似乎有之前解l2d bin的头部特征 猜测应该是采用gzip压缩的 通过分析 我个人认为的包体结构是这样的 包体文头部分23个字节 应该包含文件大小和文件数什么的 我不太清楚具体怎么划分的 就都算在头部里面了 然后是配置json文件名称 占41字节 不过还有一种短的配置json文件名称 占14个字节 然后1个字节 判断是否压缩 01则代表压缩 如果是 则用三个字节代表文件原来的大小 再用三个字节代表压缩文件的大小 然后2字节 00 29 用于分开两个文件 如果是非压缩 则为00 然后三个字节代表文件大小 文件内容后2字节 00 29 按此规则解包 包体最后10个字节代表尾部 按照这个逻辑写了个python代码 将json文件解包出来
import os
import gzip
filepath =r"C:\Users\zjbook\Desktop\新建文件夹\data.bin"
outputpath = r"C:\Users\zjbook\Desktop\新建文件夹\output"
with open(filepath,"rb") as f :
data = f.read()
data = data[23:-10]
i = 0
while i < len(data):
if data[i:i+41][-4:] == b'json':
file_name = data[i:i+ 41].decode('utf-8')
i += 41
if data[i:i + 1] == b'\x01': # 压缩文件
file_length = int.from_bytes(data[i:i + 7][-3 :], byteorder='big')
i += 7
file_content = gzip.decompress(data[i:i + file_length])
i += file_length + 2
with open(os.path.join(outputpath, file_name), 'wb') as f :
f.write(file_content)
f.close()
elif data[i:i + 1] == b'\x00': # 非压缩文件
file_length = int.from_bytes(data[i:i + 4][-3 : ], byteorder='big')
i += 4
file_content = data[i:i + file_length]
i += file_length + 2
with open(os.path.join(outputpath, file_name), 'wb') as f :
f.write(file_content)
f.close()
elif data[i:i+14][-4:] == b'json':
file_name = data[i:i + 14].decode('utf-8')
i += 14
file_length = int.from_bytes(data[i:i + 7][-3:], byteorder='big')
i += 7
file_content = gzip.decompress(data[i:i + file_length])
i += file_length + 2
with open(os.path.join(outputpath, file_name), 'wb') as f:
f.write(file_content)
f.close()
if data[i:i + 1] == b'\x01': # 压缩文件
file_length = int.from_bytes(data[i:i + 7][-3:], byteorder='big')
i += 7
file_content = gzip.decompress(data[i:i + file_length])
i += file_length + 2
with open(os.path.join(outputpath, file_name), 'wb') as f:
f.write(file_content)
f.close()
elif data[i:i + 1] == b'\x00': # 非压缩文件
file_length = int.from_bytes(data[i:i + 4][-3:], byteorder='big')
i += 4
file_content = data[i:i + file_length]
i += file_length + 2
with open(os.path.join(outputpath, file_name), 'wb') as f:
f.write(file_content)
f.close()
else:
print("解包失败,位置在",i)
break
然后根据之前的经验 来还原moc3和贴图的名称 不过仍有几张图片名称没找到对应 不太清楚为什么 不过不重要 名称已经还原了 然后根据名称 把高分辨率的图片找出来 高分辨率的名称都是texture没办法 只能手动找了 语音的配置文件也找到了 不过还没还原 估计也少 l2d动作很多 不怎么好做lpk和wpk 就直接分享吧 也懒得做配置了 就弄了个基础配置 看了下应该没什么问题 这次用的夸克盘 zgirl3 l2d 夸克好像有点问题不知道会不会被过滤 我又加了一个123压缩密码 百度网盘我也传了一份
1 个赞
diedye
23
其实是我怕不止百度网盘,而是所有要登录帐号并验证手机号码下载的网站服务… 
看完了,然后自己尝试解了一遍,我靠,这个解包我写代码我就总共写了不下500行,太麻烦了
diedye
26
看来未来有一堆游戏会从u3d跳到这个cocos creator上开发
所以我感觉到未加密就门槛就难受…
https://jsoneditoronline.org/ 先推荐个json编辑工具来分析import文件夹里的文件或者拆分xxx.model3.json
问题关键是怎样解index.jsc GitHub - NickMonkeys/CocosCreatorJscDecrypt: 解密CocosCreator构建的jsc文件 (我没法运行java脚本也就没试下去)
然后根据资源的uuid/文件名反向从import文件夹的json甚至index.jsc中找对应的话,能否减少解包代码行数?
比如说这个zgirls3除了热更新外是不是还有资源从服务器下载到手机本地?
jinmo
27
大佬,很抱歉过节的时候打扰你,但是看帖操作的时候发现连接炸了,实在心痒难耐,所以恳请您上线的时候有空补个链接
43rfe
28
我找到关于spine的还原的方法了,还没实现因为现在时间太晚了具体的思路按照
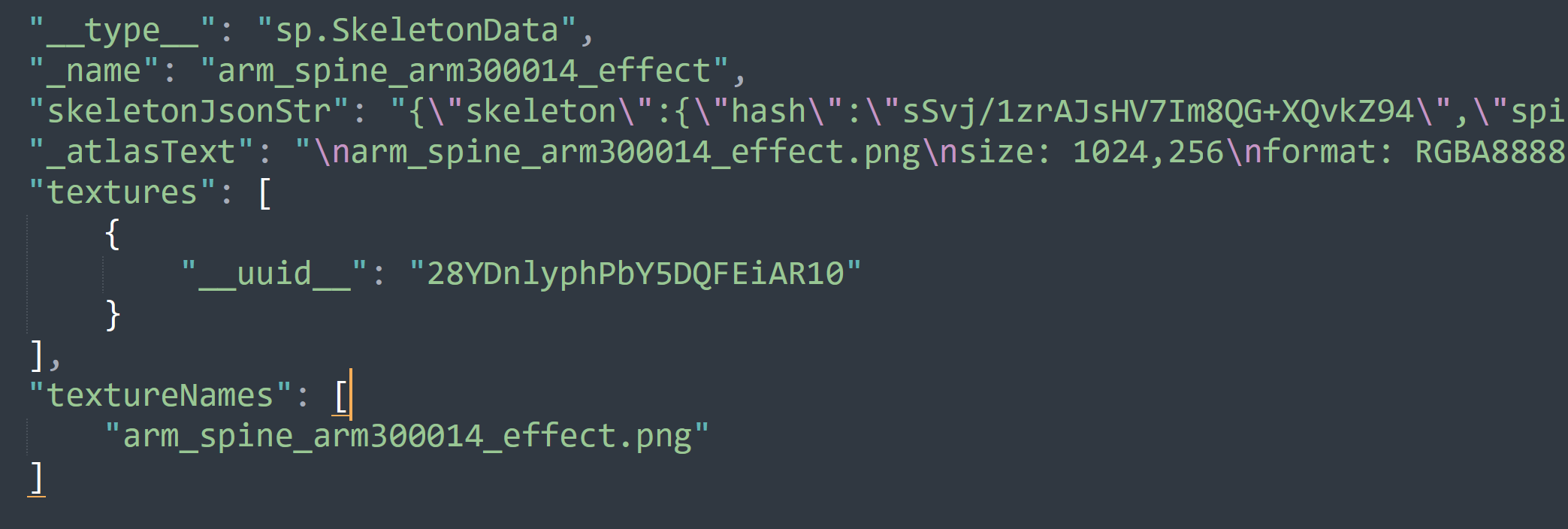
https://live2dhub.com/t/topic/2676/2?u=43rfe 这个地方使用hex editor来找到相关spine的东西,可以去(import 文件夹里面的json去搜索)然后找到相关的json通过ai来把json里面的关于spine的东西提取出来(文件路径:\assets\res\import\?\00516793-1594-42ec-8e3b-f92f0990ed03_1.json)
这里面有相关的skel对于atlas也可以这样找通过ai来写一个相关的提取的功能(但是我没时间找到相关的uuid映射表了(或许有因为我通过hex找到了相关的uuid但是没用找到对应的路径只找到对应的md5))至于live2d可以通过上面的来弄(但是要跳过非live2d的否则会报错,具体可以通过ai来写一个跳过非相关文件,然后通过
#!/usr/bin/env python3
-- coding: utf-8 --
“”"
extract_from_bin.py
从当前目录下的 .bin 文件(实际为 model3.json)中提取 Live2D 资源
每个 .bin 解密到一个以其命名的文件夹中
“”"
import json
import os
from pathlib import Path
def extract_physics(data):
physics_str = data[“FileReferences”][“Physics”]
return json.loads(physics_str)
def extract_motions(data):
motions = data[“FileReferences”][“Motions”]
extracted = {}
for motion_list in motions.values():
for motion in motion_list:
file_path = motion[“File”]
file_data_str = motion[“FileData”]
try:
motion_json = json.loads(file_data_str)
extracted[file_path] = motion_json
except json.JSONDecodeError as e:
print(f" [!] 解析 {file_path} 失败: {e}")
return extracted
def save_json(obj, filepath):
filepath = Path(filepath)
filepath.parent.mkdir(parents=True, exist_ok=True)
with open(filepath, ‘w’, encoding=‘utf-8’) as f:
json.dump(obj, f, ensure_ascii=False, indent=2)
print(f" [✓] {filepath.name}")
def process_bin_file(bin_path):
print(f"\n[i] 正在处理: {bin_path.name}")
# 创建以 .bin 文件名命名的输出目录
output_dir = bin_path.with_suffix("") # 去掉 .bin
if not output_dir.exists():
output_dir.mkdir()
print(f" [dir] 创建目录: {output_dir.name}/")
else:
print(f" [dir] 使用目录: {output_dir.name}/")
# 读取内容
try:
with open(bin_path, 'r', encoding='utf-8') as f:
content = f.read()
data = json.loads(content)
except Exception as e:
print(f" [✗] 读取或解析失败: {e}")
return
base_path = output_dir
# 1. 保存 model3.json
save_json(data, base_path / "model3.json")
# 2. 保存 physics3.json
try:
physics_data = extract_physics(data)
save_json(physics_data, base_path / "physics3.json")
except Exception as e:
print(f" [!] physics3.json 提取失败: {e}")
# 3. 保存所有 motion3.json
try:
motions = extract_motions(data)
for file_path, motion_json in motions.items():
motion_output = base_path / file_path
save_json(motion_json, motion_output)
if motions:
print(f" [i] 共提取 {len(motions)} 个动作")
except Exception as e:
print(f" [!] 动作提取失败: {e}")
# 4. 创建 textures 目录并提示
textures_dir = base_path / "textures"
textures_dir.mkdir(exist_ok=True)
textures = data["FileReferences"].get("Textures", [])
if textures:
print(f" [tex] 需放入 {len(textures)} 个纹理文件:")
for t in textures:
tex_file = textures_dir / Path(t).name
print(f" - {Path(t).name}")
else:
print(f" [tex] 无纹理引用")
print(f" [✓] {bin_path.name} 提取完成!\n")
def main():
current_dir = Path(“.”)
bin_files = list(current_dir.glob(“*.bin”))
if not bin_files:
print("[!] 当前目录未找到 .bin 文件")
return
print(f"[i] 发现 {len(bin_files)} 个 .bin 文件,开始批量提取...\n")
for bin_file in sorted(bin_files):
process_bin_file(bin_file)
print("[ALL DONE] 所有 .bin 文件已提取完成!")
if name == “main”:
main()
来提取弄好的非moc的bin的py)希望弄好的人能分享一下相关的spine谢谢了
43rfe
31
在回复前先下载看看里面的文件,里面有pkm(可以转png)但是里面没用相关的atlas skel 这些是在import这个包的json里面,但是这些json太杂了,可以通过那个软件来把需要的json分出来,但是这些json和原本的skel又不一样他大概率也是封转的就像我发的图片里面和skel的内容一样,所以你需要提取出来skel,同理atlas也是这样。至于原本在pkm和其他在另一个包他的命名是以uuid命名的,如果不能把这个命名转会原来的名字那就要自己一个一个配,会死人的(这样解释懂了吗)
43rfe
32
然后那个我给的代码是live的,是基于上面**bakaneko** 他写的解压后的,但是解压后还是bin 其中一部分是moc一部分是混合的 他们的类型都是.bin,我需要通过py来把混合的分成符合live2d格式的动作,和另外两个json,他会全部整理好(尽量一个一个来,如果要全部弄请教ai修改代码,因为我是一个一个弄的,而且他是匹配当前运行的目录不是自己手动输入和py修改的)
我解到live2D这块 发现只有待机甚至有的待机都没有,加载出模型就没有动作,查看model文件对比正常model文件,发现里面motion段落格式是缺失要素不完整的,应该就是这里出问题了导致无法加载动作,这是为什么啊,如何解决?
补充 data.bin 结构
Magic 3B // "PK!"
uint16 fileCount; // big-endian
file_1
[name_len: 2B] // big-endian 00 29大端读取是41, 也就是36+5 (uuid36 + ".json"(5))
[name: name_len B]
[flag: 1B]
[size: 3B] // 体积/解压后体积 big-endian
[(optional) extra_size: 3B] // flag判断 压缩体积 big-endian
[data: size or extra_size B] // 优先使用extra_size, 需要先检测头, 如果是`1F 8B 08`则需要gzip解压
file_2
...
file_3
...
file_fileCount
...
Magic 3B // "PK!"